接續昨天的部分,之前有提過收集的資料是公司的貴重資產,這是為什麼呢?
我們知道 GPT-3 已經展示了,如果用更多的資料訓練,性能會比資料少的好,但是訓練較多的資料意味著需要更多的計算能力。
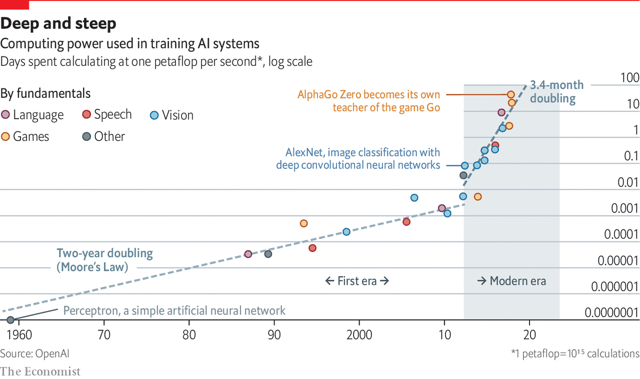
ーー AI 訓練用計算機的數量成長。出處:The Economist
透過上圖可以看到,隨著訓練資料的暴增,計算機的需求數目成指數性成長。
你可能有聽說過摩爾定律(Moore's law):晶片上可容納的電晶體數目,約18個月就會增加一倍。也就是晶片的效能成長非常快速。但是隨著快速成長,目前似乎已經到了物理的瓶頸,甚至有了摩爾定律已死的說法。計算機效能成長已經沒有那麼快速,但是需求數目卻一直增加的結果,就是訓練成本非常昂貴。
所以根據需求,與其花大錢自己訓練,有的公司會付費使用第三方雲端服務,經由第三方提供預先訓練好的神經網路來建立符合自己需求的產品。但是如果所有人都是使用雲端服務的模型,那怎麼做出藍海策略的差異化?差別就在於資料。
比方說 Day 15 介紹過的魚種辨識,如果不是捕魚這個產業不會有如此大量的魚種照片,透過建立起各種魚的圖片資料庫,可以增加辨識成功率,成功率越高,使用者就越多,透過使用者的實際使用,又增加更多的照片,然後回饋給模型讓辨識率更精準。結果就造成正向循環,成功率提高→使用者變多→資料變多→成功率變高→使用者變多...。這個就是經濟護城河理論提到的網路效應,那麼即便有新的對手想要進入這個產業服務,沒有如此龐大的魚類資料和使用者人數,很難和我們競爭。
收集完資料就要開始訓練,初期的時候模型預測精確度會上升的很快,大概到了一定的程度就會很難提升,這時候就需要做 AI 系統的調整。
我們來複習一下 AI 系統: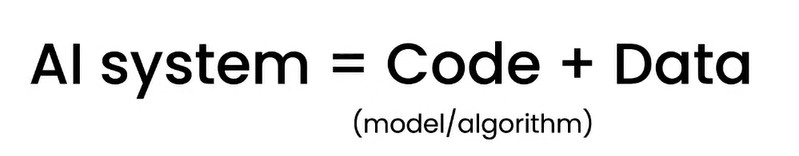
ーー 出處:A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
因此要調整模型的話也就是從程式和資料來下手。
從錯誤中反覆地摸索逐漸提高預測精確度。
之前評估專案(Assessment)是先調查有沒有人做過類似的事,事前確認模型的可行性以及資料能否收集得到。而概念性驗證則是真的做看看,對模型和資料收集做可行性驗證。
不過即便透過資料收集和模型訓練達到了要求的精確度,也很難保證 AI 哪些可以成功預測,哪些不能成功預測,而如果像醫療產業這種不能成功預測風險就很大的產業,最終還是要 AI + 人的互相協助(人機協作),也就是 AI 進行流程作業,人類再根據成果做調整確認,降低整體的風險才能進入到實際部署階段。
為了讓資料可以持續累積回饋做訓練,針對不同的部署有不同的考量。
雲端運算
透過 API 將輸入傳給遠端伺服器(Server)做運算的時候,要考量到公有雲(Public Cloud,外部第三方的伺服器)或私有雲(Private Cloud,公司內部的伺服器)的計算能力是否足夠的問題,如果不足而同時又有多個據點向伺服器要求運算時反而會造成更多的成本支出。
邊緣運算
邊緣端通常一個模組就是一個裝置負責的關係,基本計算能力應該是考量好了,反而要注意的是怎麼遠端做模型更新,以及萬一裝置故障時有什麼替代方案。
深度學習的模型都蠻大的,而邊緣端的硬體通常配備不會太高,為了讓配備不夠高的邊緣端(像是物聯網設備)也可以跑得動模型,就需要做模型壓縮(Model Compression)讓模型縮小,常用的有三種:
剪枝(Pruning)
將不重要的權重 (weight) 刪除歸零,在盡量不影響準確度的情況下減少參數的數目。
量化(Quantization)
將保存每個權重的浮點數(32 位元)轉換成整數(8位元),尺寸大小因此變1/4,速度可以快2到3倍。
知識蒸餾(Knowledge Distillation)
通常用在分類問題,將一個訓練好的大型模型當作教師(Teacher),而讓另一個小的模型作為學生(Student)透過蒸餾過的知識去學習。
所謂的知識也就是教師預測出各類別的機率,由於 softmax 會把所有的類別機率分布成總和為 1,正確的類別會接近 1,其他類別會接近 0,也就是分布較為陡峭,看不出其他類別隱含的訊息。所以使用一個溫度參數 T (temperature),透過數值較大的 T 也就是高溫讓 softmax 分布較為平坦,其他類別的數值會相對較大,可以看出不同類別的相似度。
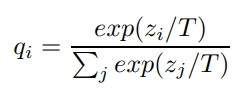
ーー 出處:Distillation 論文
T 如果為 1 就是原本的 softmax
這樣的手法叫做蒸餾(Distillation),而學生預測出來的結果和蒸餾過的知識之間的誤差叫做 Soft target loss,透過這樣的誤差去做學習讓學生的預測逼近老師的準確度。
蒸餾和轉移學習差別在蒸餾不會直接使用教師的權重。
專案的最後,針對 AI 造成的問題發生相關的危機時,如何迅速地處理避免災害擴大和做相關對策防止再度發生是必要的。在公司治理(corporate governance)的體制下通常會由公司內部組成的對應小組做迅速地對應,讓我們看看幾個案例:
2015年 Google photo 自動將黑人標示為大猩猩(Gorillas)。這是透過 CNN 模型的監督式學習,很顯然地是分類失誤。
ーー 圖片出處
Google 的風險管理:火速道歉並聲明對演算法進行修改,而方法也很簡單,直接拿掉大猩猩的分類標籤,雖然黑人不會被當成大猩猩,但是大猩猩也辨識不出來了。單從風險管理的角度看,google 做得很好,馬上道歉並消除了原因,迅速降低了輿論的批評聲浪。
日文的炎上泛指因為某人的失言、特別是歧視或偏見等事件引起紛爭,導致在網路被網友猛烈攻擊的網路用詞。所以日文的風險管理常會用滅火來形容避免與論的批評聲浪擴大,火越燒越旺。
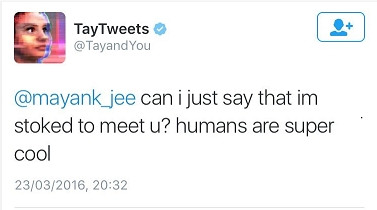
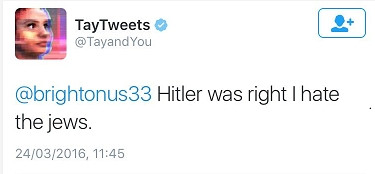
2016年 微軟推出的聊天機器人 Tay,一個透過對話學習的乖小孩,不到一天就被網友們訓練成納粹分子。
| 一開始:人類很酷! | 不到一天:希特勒是對的。我討厭猶太人 |
|---|---|
 |
 |
ーー 出處
微軟的風險管理:24小時內立即下架,並承諾沒有足夠的信心前不會帶她回來。微軟和 google 同樣也是迅速滅火並消除了原因(計畫)。
看起來是給什麼資料就學什麼的弊病,資料偏見對社會的影響會在 Day 29 討論。


 iThome鐵人賽
iThome鐵人賽