經過前幾天的努力,我們的錄音功能已經成功建置完成。終於可以來介紹本次主題的另一個重點:ChatGPT。近年來,隨著AI的劇烈進展,特別是今年可以稱為生成式AI的元年,ChatGPT的誕生無疑進一步推動了AI語言模型的發展。這個強大的自然語言處理模型已成為許多創新應用的核心,從客服自動回答到創作輔助,它都展示了其無限潛力。在接下來的鐵人賽中,我們將會使用Whisper模型來實現語音轉文字並且搭配GPT模型來實現APP的英文對話核心功能,因此今天就讓我們先來了解GPT和Whisper API的使用方式吧!注意!使用OpenAI提供的模型時,會產生一定的費用!
GPT-3.5和GPT-4模型都是由OpenAI開發的先進語言模型。這些模型透過大量的文本數據訓練,能夠理解和生成自然語言文本。ChatGPT則是建立在GPT-3.5和GPT-4模型架構之上。GPT-4模型可以看作是GPT-3.5模型的升級版,除了具有更多的參數和增強的穩定性,其Token數量也達到了GPT-3.5模型的2到8倍。由於Token數量的增加,模型能夠儲存的上下文對話記錄也相應增加,但這也意味著使用成本將會提高。以下是GPT API價格。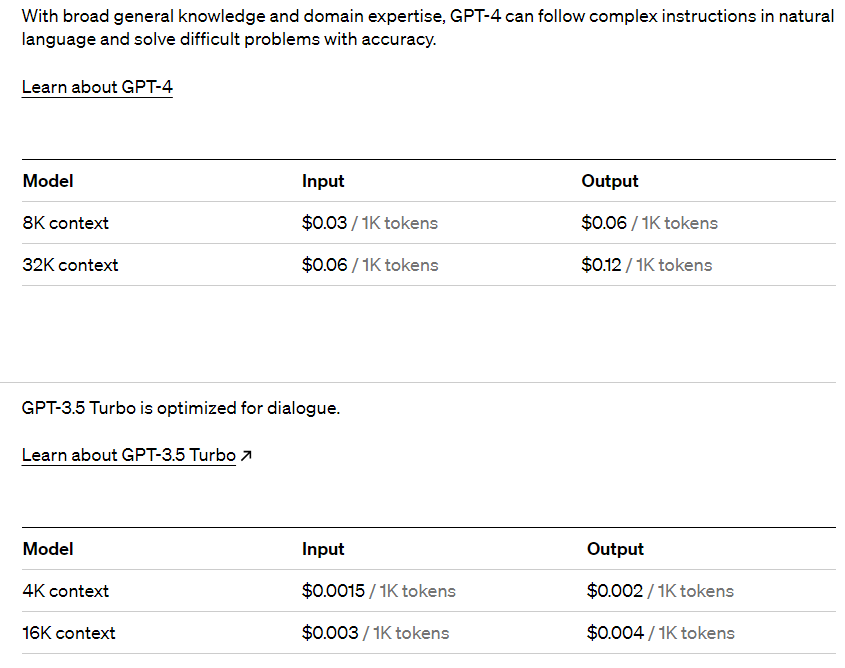
Whisper模型則是一個專門為語音識別和語音翻譯設計的自動語音識別(ASR)系統。與其他語音轉文字系統不同,Whisper模型能夠透過其內建的神經網路技術,有效處理各種不同的口音、背景噪音和專業語言。以下是Open AI上Whisper API的價格。
在使用API之前,我們需要先申請OpenAI的帳號並設定好「信用卡」(以前新用戶有18美元的免費額度可用,現在好像只剩下5美元)。完成後,請在右上角的頭像中選擇「View API Keys」來查看相關密鑰。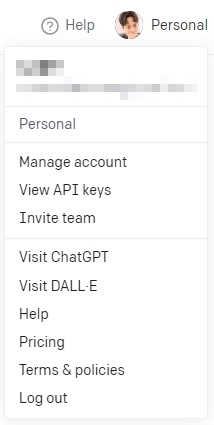
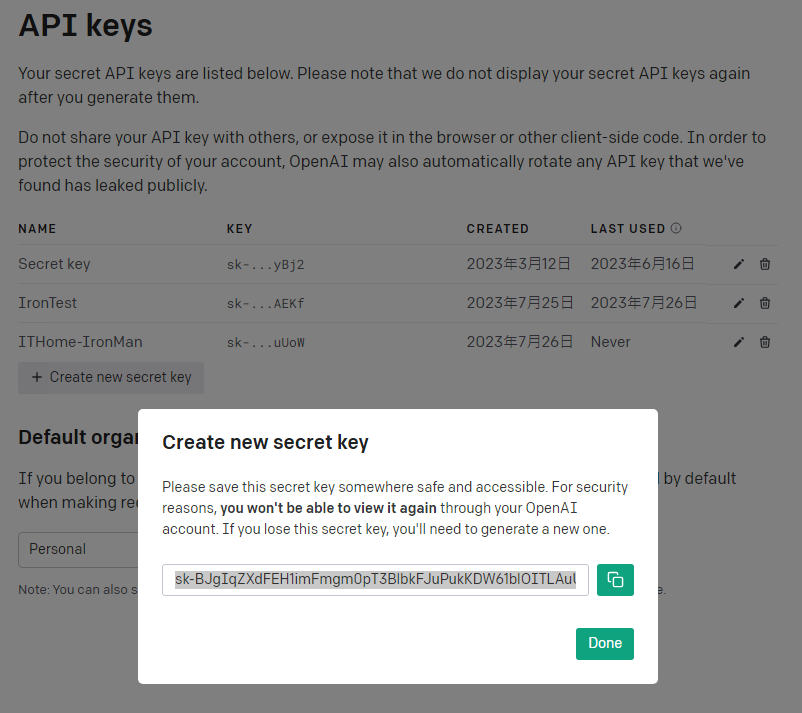
在API keys頁面中,找到「Create new secret key」按鈕並點擊。接著輸入名稱後,就可以完成API Key的建立。請記得將這組Key記錄下來,以便後續使用。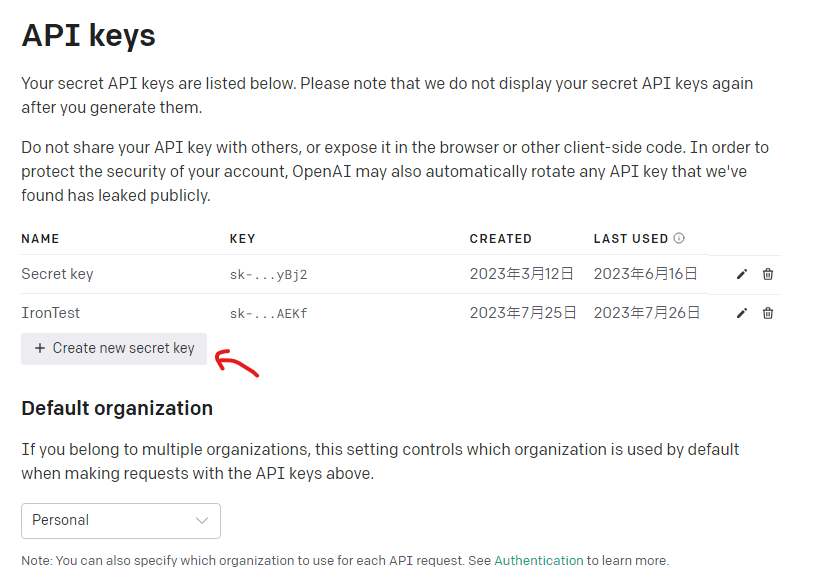
在理解API結構之前,我們可以先利用Postman工具來實際執行一次API請求。透過觀察和了解其回應內容,可以更深入的瞭解API。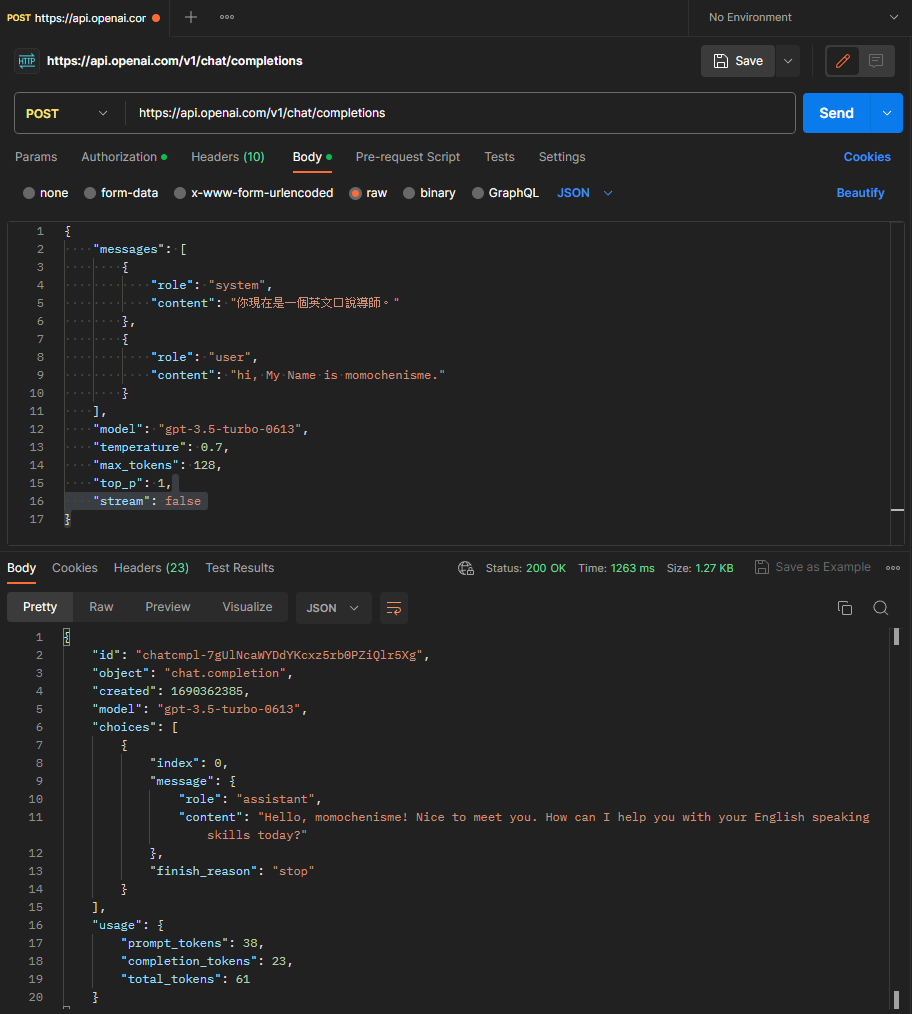
Request的主要參數有以下兩項:
除了主要參數外,還有一些選用的參數可以設定:
以上是比較常用到的參數,如有想了解其餘的參數設定,可以參考Open AI的API Reference文檔。
choices[0].message.context來取得對話內容。我還記得當初在使用gpt-3.5-turbo-0301版本時,官方提到該版本不太關注系統消息(System Prompt)。然而,在0613版本發佈後,gpt-3.5-turbo開始關注系統消息,使得操作變得更加容易。有關此次更新的詳細資訊,可以參考Open AI官方的公告。
Whisper API提供了以下兩個API功能:
在接下來的實作中,我們將主要集中在使用「transcriptions」功能。我們一樣先使用Postman工具實際進行一次API請求,並仔細觀察和了解回應的內容。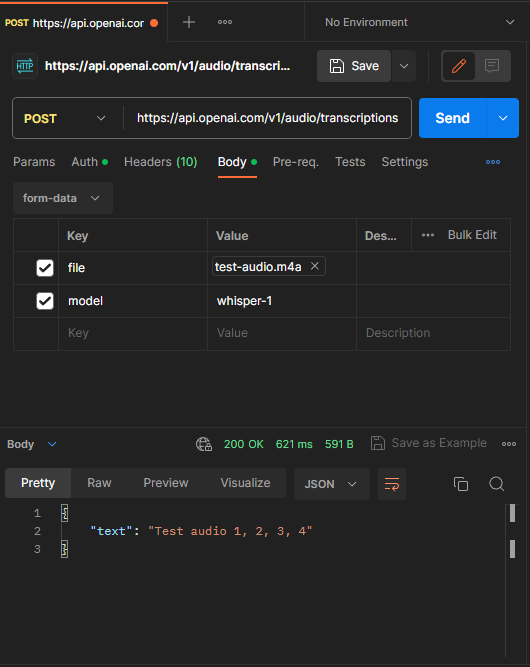
Request中主要的參數:
更多其他選用參數,請參考Open AI API Reference文檔。
至於Whisper的Response則相對簡單,只有一個參數:
今天,我們探索了GPT和Whisper API,並學習了如何使用它。其中,我覺得Whisper模型絕對值得大家細細品味。在測試它的過程中,我發現Whisper模型不僅能辨識我的「台式口音」、「破英文」和「中文」,甚至是簡單的「台語」,都能以驚人的精確度將語音轉化為文字,真的非常的厲害呢!也正因為Whisper模型的強大性能,它自然成為我在實作語音轉文字功能時的首選方案。
Github專案程式碼:Ionic結合ChatGPT - Day8

