在詳細介紹 GAN 的理論前,想先補充一下條件生成的概念,以及如何訓練 GAN 以達到條件生成的目標~
生成任務依照輸入是否有控制模型產生圖片的條件,可分為條件生成與無條件生成。
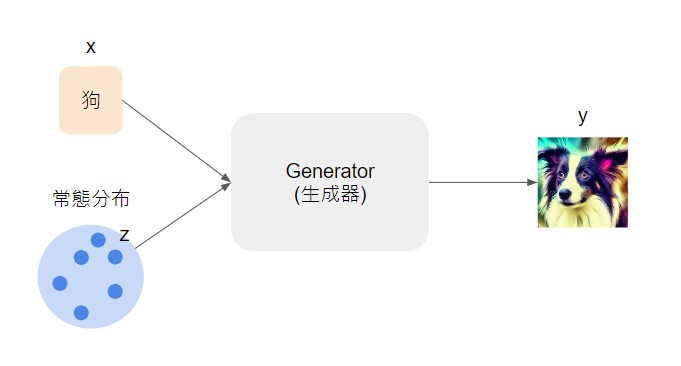
條件生成其實就例如我之前這張圖所畫的,模型的輸入除了有隨機抽樣的向量(z),還有一個條件(x)控制模型生成圖片的內容,例如這裡輸入了「狗」,我們就會期望模型產生狗的影像,而不是貓啊熊啊之類其他不相干的影像
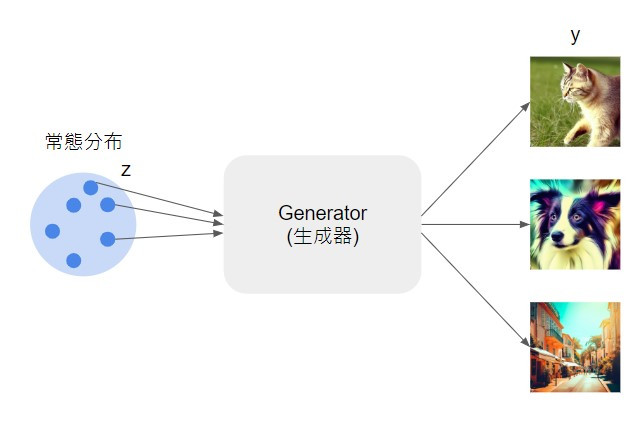
如果生成任務沒有受到條件的限制,就隨機的產生影像,那就是無條件生成。如下圖只輸入從常態分布抽樣出來的向量,輸出就是隨機的,如果訓練資料的內容涵蓋動物圖片和風景照,模型就可能隨機生成貓狗影像和街景照。
從實際應用的角度來看,能用條件控制生成比較接近我們對生成任務的期待。其實,條件生成不只包含像上面的例子使用一個標籤(「狗」)作為條件,利用一段文字引導影像生成(text-to-image,例如 Bing Image Creator)、輸入一張影像讓模型轉換為另一種風格的影像(pix2pix),或透過語音控制影像生成(sound-to-image),都屬於條件式影像生成的範疇。
不知道大家有沒有注意到了,上一篇文章在介紹如何訓練 GAN 時,只要求 discriminator 分辨影像是真實的還是生成的,generator 也只要產生夠逼真的圖片騙過 discriminator 就好,我們並沒有訓練模型依照輸入條件產生影像,因此這樣的訓練方式得到的會是 unconditional GAN。
那要如何訓練 conditional GAN,讓它依照條件產生圖片呢?
首先我們必須準備條件與圖片的成對資料訓練 discriminator,此時 discriminator 不只要能依照影像品質分辨出真實影像和生成影像,還要判斷影像內容和條件是否符合。
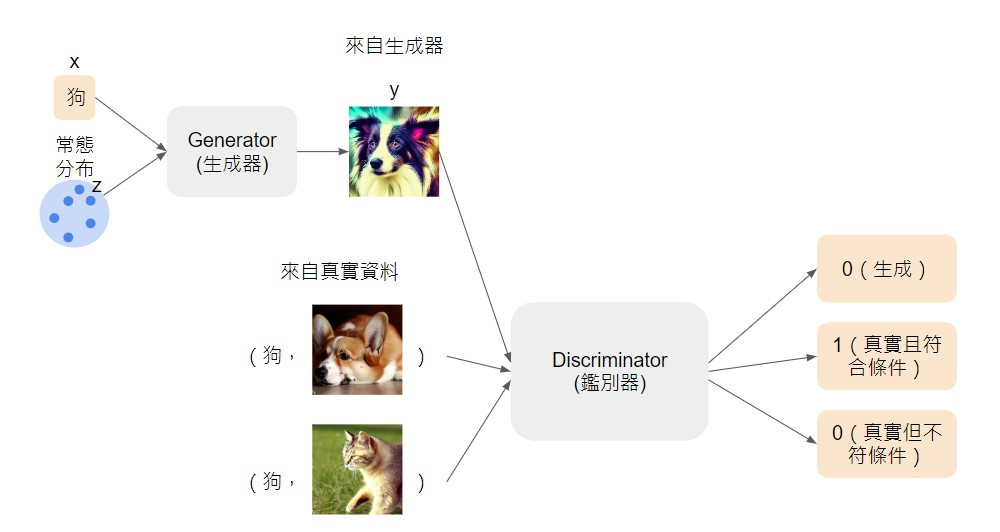
接著,generator 再依照 discriminator 判別的結果,學習產生更逼真且符合條件的影像。然後就像是先前介紹訓練 unconditional GAN 一樣,不斷重複訓練 discriminator 和 generator,我們就能獲得能夠依照條件產生精緻影像的模型了~
今天就先這樣啦~明天要介紹的是 GAN 的理論,真是令人緊張啊

