今天要介紹的是生成對抗網路(generative adversarial network,簡稱 GAN)~
GAN 是一種用於解決生成任務的機器學習演算法,最早在 2014 年由 Ian Goodfellow 提出。就如同前一天簡介圖像生成提到的,生成模型要能夠學習到真實影像的分布,並利用這個估計出來的分布產生接近真實的新影像,而 GAN 就是能讓我們得到生成模型的其中一種方法。
下圖為 Ian Goodfellow 當時得到的一部分結果,雖然從現在的角度看,感覺只是一些模糊、看不清楚內容的影像,但以當時來說已經是非常大的突破!

(圖片來源:Generative Adversarial Networks)
而在 GAN 提出後的四五年間,各種基於 GAN 的變形與優化方法不斷被提出, GAN 生成影像的能力也越來越驚人。下圖提供了人臉生成方面的例子,從 GAN 剛提出時只能產生模糊、五官有點不自然扭曲的人臉,到 2018 年時已經能產生充滿細節的高解析度影像,皺紋與髮絲都栩栩如生,效果是不是非常令人震撼呢?
如今,GAN 確實就是以產生逼真且高品質的影像而聞名,而 GAN 究竟是如何達到產生影像的目標呢?
首先必須先提到 GAN 的架構,GAN 是由一個生成器(generator)和一個鑑別器(discriminator)組成的結構。
Generator 就是最終我們要拿來產生影像的模型,輸入可能會有一個給定的值、標籤或文字指令,以及從簡單分布(通常是常態分布)抽樣得到的向量,而輸出會是一張影像。
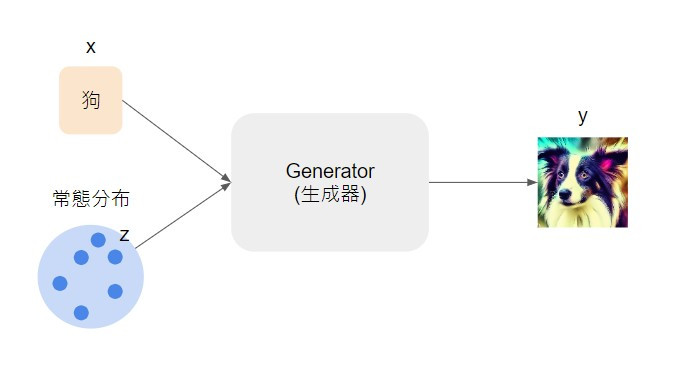
為什麼除了輸入我們想要模型產生什麼以外,還要輸入一個從機率分布抽樣的向量呢?這是因為我們希望模型生成的影像可以有不同的變化,所以還需要加上隨機的輸入。
至於 discriminator 則是用於分辨影像是來自真實資料還是生成的,因此輸入是影像,輸出則是一個純量,用以代表影像的真實程度,值越大代表越有可能是真實影像,值越小則越有可能是生成影像。
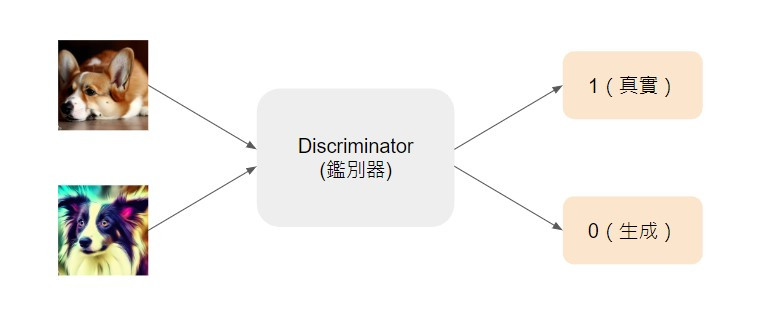
例如柯基圖片是真實影像,discriminator 的輸出就要越接近 1 越好;邊境牧羊犬圖片是生成影像,輸出就要越接近 0 越好。(雖然兩張圖片都是我用生成工具產生的啦~只是舉例
稍加思考 GAN 的兩個組成部分,是否覺得它們的功能有點互相衝突呢?
沒錯,這就是 GAN 運作的核心想法,在對抗中互相砥礪、持續進步,因此命名才會有 adversarial 這個字。在原作 paper 中,作者用製造假鈔的人和警察來比喻這樣的關係,generator 就像是製作假鈔的人,而 discriminator 則像是鑑別假鈔的警察,兩者之間的對抗關係會促使製造假鈔的人把假鈔越做越逼真,而警察也越來越會辨別假鈔。
同理,在 GAN 中,generator 會盡可能生成很接近真實的圖片,能「騙過」discriminator,讓其誤判為真實影像;而 discriminator 則要盡可正確判斷真實和生成影像。因此 generator 在這樣的對抗過程中逐漸學會產生逼真的影像,而 discriminator 同時也越來越會分辨真實影像與生成影像。由於我們的任務目標是影像生成,我們會期待透過這樣的架構與訓練方式,最終讓 generator 產生的影像與真實影像變得難以區分,如此就能得到可以生成精緻影像的模型了
這裡簡單介紹一下 GAN 的訓練方式。首先我們會先初始化 generator 和 discriminator 的參數,接著不斷重複以下兩件事:
固定 generator 的參數,訓練 discriminator
訓練 discriminator 時,我們會將真實影像樣本標記為 1,生成的樣本標記為 0,引導 discriminator 分辨真實影像與生成影像。
固定 discriminator 的參數,訓練 generator
在 discriminator 的判別能力變強一些之後,discriminator 判別的結果會成為 generator 學習的依據。Generator 的學習目標會是讓自己產生的影像通過 discriminator 之後,得到的分數接近 1 越好。
上面第一個步驟會提升 discriminator 的判斷能力,第二個步驟則透過變強的 discriminator 促使 generator 增強圖片生成的品質,接著,變強的 generator 又能再加強 discriminator 的判別能力,如此不斷循環~
關於 GAN 的簡介在此先告一段落~之後幾天會再陸續介紹更詳細的理論、訓練技巧和評估方法,敬請期待!如果對於這系列文章有任何建議或發現有需要修正的地方,也歡迎留言告訴我


