今天終於要開始介紹另一個生成模型了!那就是 variational auto-encoder,簡稱 VAE
不過在開始解釋 VAE 是什麼之前,先來說明一下 auto-encoder 是什麼~
Auto-encoder 是由一個 encoder 和一個 decoder 組成,encoder 會將輸入的影像壓縮降維成比較低維度的向量(通常會被稱為 code 或 latent vector,能代表輸入影像的精簡化表徵),decoder 則是將 code 再解碼還原為影像。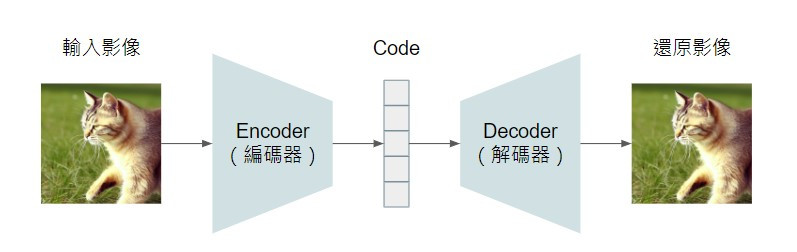
這個模型架構最早是由 Hinton 於 2006 年提出(可參考 Reducing the Dimensionality of Data with Neural Networks)。許多 auto-encoder 相關的應用都是為了利用 encoder 取得複雜資料(例如影像、文件)的降維資訊(code),這樣就可以利用影像的 code 進行以圖找圖,或用文件的 code 進行文件檢索等。然而,我們並不知道每個輸入資料應該對應到什麼樣的 code,因此我們沒辦法準備用監督式的方法來訓練 auto-encoder。
而解決的辦法就是在 encoder 後面接上一個 decoder,將降維後的 code 再還原為原始的資料。為什麼這樣的機制就能幫助 encoder 學習到如何將複雜資料轉換成 code 呢?以影像的 auto-encoder 為例,如果 code 帶有輸入影像的重要資訊,能作為輸入影像的精簡表徵,那 decoder 應該就能夠透過這個 code 再還原出原本的影像。要求 auto-encoder 讓輸入影像和還原影像一致,就能確保它學習到的 code 是和輸入資訊非常相關的。
補充一點,這樣的訓練方法是不需要額外準備人工標註的資料的,而且學習的目標就是輸入資料本身,這類型的訓練模式就被稱為自監督式學習(self-supervised learning)。
那在訓練好一個 auto-encoder 後,我們除了可以用 encoder 將複雜資料降維以外,能不能用 decoder 來產生影像呢?答案是可以的。Decoder 就如同之前介紹的 generator 一樣,輸入是一個向量,而輸出是一張圖片,我們可以藉由輸入不同的向量來產生影像。
然而實際上使用 auto-encoder 中的 decoder 產生影像的效果並不好,這是為什麼呢?
記得之前在介紹 generator 時提到,generator 的輸入會是一個從特定分布(通常是常態分佈)抽樣得到的向量,但在訓練 auto-encoder 時,我們並沒有要求模型學習讓 code 符合一個特定的分布啊
而 variational auto-encoder(VAE)就是針對 auto-encoder 學習的 code 進行限制的一種方法。
VAE 是由 Diederik Kingma 和 Max Welling 於 2013 年所提出,原始 paper 為 Auto-Encoding Variational Bayes。
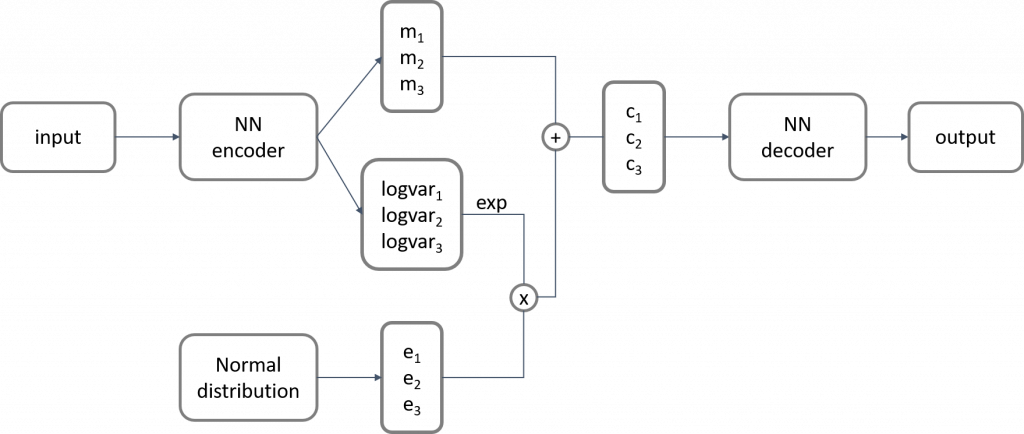
以上就是 VAE 的簡化架構圖。和 auto-encoder 最大的差別是,VAE 的 encoder 不再是直接把影像壓縮成 code,而是產生兩個 vectors,並另外由 normal distribution 產生一個隨機的 vector,來組成最終的 code。這樣的作法一方面能讓 code 符合常態分佈,也將隨機性引入了 auto-encoder。
關於 VAE 的數學原理,之後的文章會再詳細說明。這裡先讓大家看看 VAE 影像生成的效果:

(圖片來源:VAE-for-Image-Generation)
很明顯可以看到,相較於之前介紹的 GAN,VAE 產生的影像通常都比較模糊,而且主體也不太明確,因此,在需要產生高品質的影像時通常不會使用 VAE。
然而,VAE 因為它的訓練方式,也是有其他優勢的,其中一個最主要的就是我們可以藉由調整 code 的特定維度的數值來控制生成的圖片。以下是用人臉影像訓練 VAE 的例子:

(圖片來源:Structured Disentangled Representations)
Code 的每個維度可能分別代表影響人臉影像的不同要素,有的維度可能代表人臉面向的角度,有的則代表表情的變化,有些則代表配件的有無等等,對於控制要產生什麼影像,和瞭解模型從訓練資料學習到哪些資訊,都非常方便。
今天就先這樣啦~關於 VAE 的數學原理,請再讓我多準備一下~

