接續前一天的文~在 [Day 8] 簡介 variational auto-encoder (VAE) 有提到,我們可以在 VAE 學出來的 code space 中透過調整個別維度的數值控制影像生成,這也是 VAE 的特色,然而這是怎麼做到的呢?
先講回 auto-encoder,我們已經知道 auto-encoder 能學習到 code 和影像間一一對應的關係,但是怎麼它是如何將影像壓縮為 code,或將 code 解碼為影像,這之中的轉換通常是高度非線性的。
這裡我們以用一維的 code 產生不同月象的影像為例子: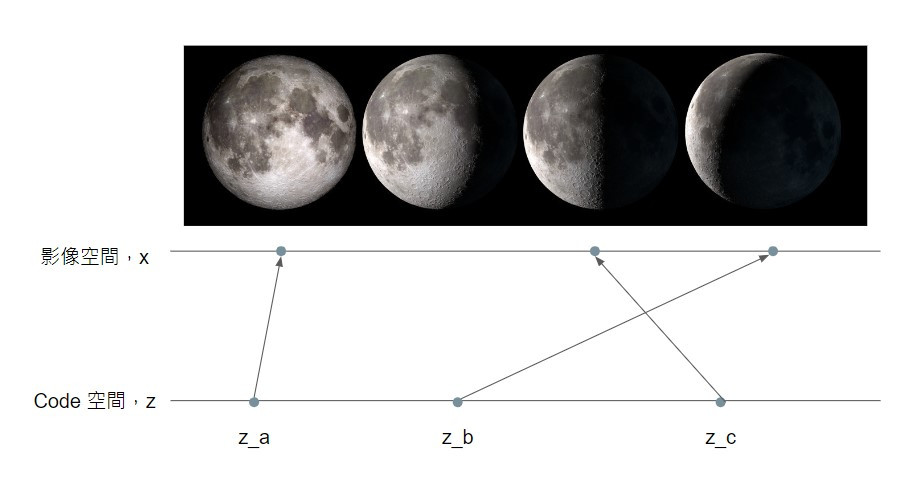
假設輸入一個 code z,decoder 就會輸出一張月象影像,輸入向量 z_a 對應的輸出影像是滿月的影像,z_c 則是對應到下弦月的影像,那介於 z_a 和 z_c 之間的向量 z_b 是否就會對應到介於滿月與下弦月之間的下凸月影像呢?答案是不一定的。
這是因為我們在訓練 auto-encoder 的時候,並沒有要求模型學習 code 空間的相對位置要和影像空間有所對應,因此輸入 z_b 得到的影像說不定也可能是殘月的影像。
讓我們回顧一下 VAE 的架構: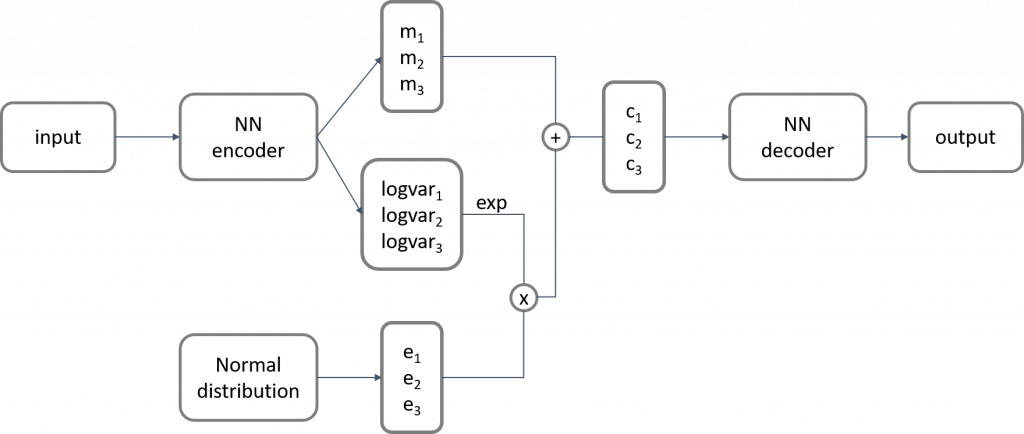
VAE 並不會直接從影像學到對應的 code,而會學到一個(高維)Gaussian distribution 的平均(mean,以 m 表示)和變異數(variance,以 var 表示),而最終取得的 code 就如同在這個學出來的 Gaussian distribution 抽樣,或可以想成在學到的 mean 加上雜訊。
然而,為什麼要這樣用這樣的方式組合一個代表影像的新的 code 呢?這樣的做法隱含的意思是,當我們讓 code 從原本的位置偏移一點點,解碼 / 還原出來的影像還是要跟原本的影像很接近,這會使得 code 和影像間的對應關係變得比較平滑。
再次以月象影像生成為例子,由於 z_b 和 z_a 接近,和 z_c 也接近,因此對應到的影像應該既接近滿月影像,又接近下弦月影像,結果就會是兩者之間的過渡:下凸月的影像。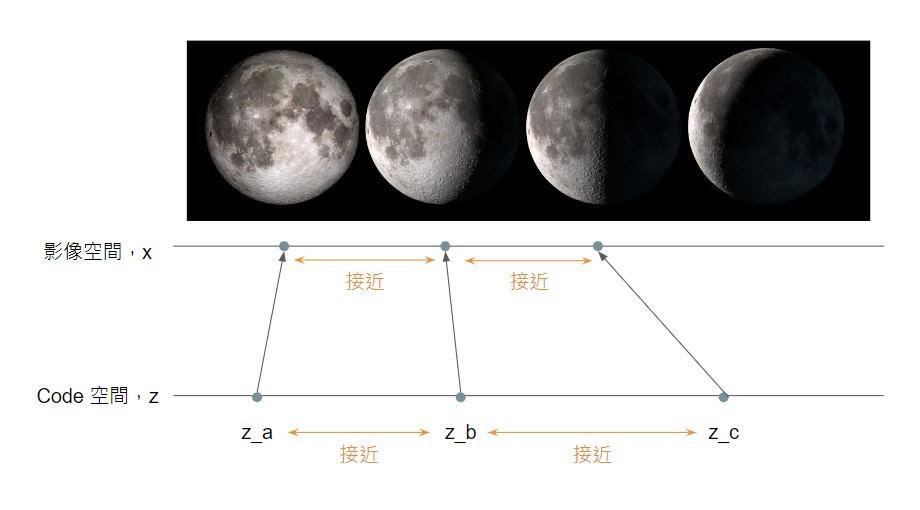
在訓練 auto-encoder 時,我們只要要求輸入和輸出的影像接近即可。但是如果在訓練 VAE 時也只要求輸入和輸出的影像越接近越好,學習出來的 variance 很可能都等於 0,代表 code 就剛好等於學習出來的 mean 而不會有隨機偏移,這樣其實就等同於一般的 auto-encoder 了,並沒有達到讓 code 空間的相對位置和影像空間的相對位置有所對應的目標。
因此,我們必須在訓練 VAE 時多設定一個目標,讓 variance 不會等於 0。
總而言之,VAE 有兩個學習目標
今天先這樣啦~明天的文章將會逐一解釋數學原理的部分!

