本文同步更新於個人網站中,有更好的程式碼 syntax highlighting 和 KaTeX 數學公式顯示支援。
通常解決一個問題都會有很多方法可以用,但要怎麼評估這些方法的優劣好壞呢?
不外乎就是評估時間與空間,時間很好理解,解決一個問題的時間越短,我們就會認為是越好的方法,空間則是看你的方法會佔用到多少的記憶體,這個當然也是越小越好,但現今記憶體容量都越來越大的情況下,我們更願意用空間換取時間,所以大部分情況下會更偏重於時間複雜度的分析
在電腦科學中,我們會用漸進式符號來表示複雜度,這邊介紹最常用的“大 O”標記 (Big O Notation) 表示。
Big O 的定義如下:
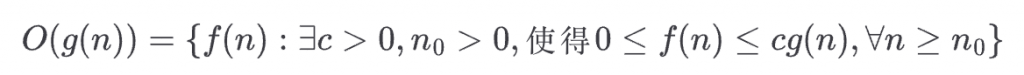
例如,當輸入值 趨近於無限大時,函式
的漸進上界為
,因為當
趨近於無限大時,
的值會趨近於
。這時候我們就可以說
的時間複雜度為
。
另外還有像是 ,我們將
趨近於無限大時,
的值會趨近於
,所以
的時間複雜度為
。
假設現在有一個陣列 persons,裡面有 n 個物件:
const persons = [
{ name: 'John', age: 20 },
{ name: 'Jane', age: 21 },
{ name: 'Jack', age: 22 },
{ name: 'Jill', age: 23 },
// ...
];
這些物件有兩個屬性:name 與 age,現在要從裡面存取 name 為 Sheep 的物件的 age。
我們可以把查詢一次,定義為執行一次操作,如果我們知道 Sheep 的位置(假如 index = 5),就可以直接 person[5].age 來存取,這樣時間複雜度就是 O(1)。
如果我們不知道 Sheep 排在第幾位,通常會用迴圈來找:
for (let i = 0; i < persons.length; i++) {
if (persons[i].name === 'Sheep') {
console.log(persons[i].age);
break;
}
}
這樣最差情況下我們需要查詢 n 次才能找到 Sheep,時間複雜度就為 O(n)。
另外在實際應用中,我們也會考慮最佳和平均情況。漸進符號還有其他像是 、
等等,但我們最常用
來比較演算法的時間效率,它表示的是當輸入值趨近於無限大時,函式的上界,就是這個演算法最久會需要花多久,用此來比較各演算法的時間優劣。
接下來我們來計算一個演算法的時間複雜度。時間複雜度是用來衡量一個演算法的效能是否高效的一個指標。我們可以通過下面的步驟計算時間複雜度:
T(n)。T(n) 中所有加法常數。T(n) 最高次項。下面是一個實作高斯算法(即等差數列求和公式)的程式碼:
function add(n) {
let sum = 0; // 執行 1 次
sum = (n + 1) * n / 2; // 執行 1 次
console.log(sum); // 執行 1 次
}
(1) 計算得到 T(n) = 1+1+1 = 3。
(2) 用常數 1 代替 3。
(3) 因為沒有其他高次項(平方、立方等),所以直接跳過。
(4) 最高次項為 1,無須去掉與其相乘的常數。
所以這個函式的時間複雜度為 O(1)。這裡我們把 n 改成 100 或 1000,都不會影響這個函式的時間複雜度,因為它的時間複雜度是常數級別的。
常見的複雜度級別從小到大依序為:

來看一下其他數量級的例子:
let a = 0, b = 1; // 語句 1
for (let i = 1; i < n; i++) { // 語句 2, 語句 3, 語句 4
s = a + b; // 語句 5
b = a; // 語句 6
a = s; // 語句 7
}
這段程式碼有 7 條語句,按照前面的步驟來計算複雜度。
(1) 分別計算每條語句的執行次數,得到語句的總執行次數:
(2) 用 1 代替常數項 -2,得到 5n+1。
(3) 只保留最高次項,所以去掉常數項 +1,得到 5n。
(4) 去掉最高次項的相乘的常數 5,得到 n。用 Big O 標記可以表示為 O(n)。
let number = 1; // 語句 1
while(number < n) { // 語句 2
number = number * 2; // 語句 3
}
這段程式碼有 3 條語句,語句 1 的執行次數為 1,語句 2 和語句 3 怎麼計算呢?
比較容易看出的是 3 比 2 少執行一次。由於每次 number 乘以 2 之後,就會更接近 n。也就是說,我們要計算多少個 2 相乘後大於 n,因為這時候會跳出迴圈。假設有 x 個 2 相乘後大於 n,那麼 ,
。所以語句 2 的執行次數為
,於是計算結果為:
所以這段迴圈的時間複雜度為 。
下面是我們常見的雙重迴圈,氣泡排序也是這種結構:
for (let i = 0; i < n; i++) {
for (let j = i; j < n; j++) {
// 複雜度為 O(1) 的演算法
// ...
}
}
需要注意的是,內層迴圈中 j = i,而不是 j = 0。當 i = 0 時,內層迴圈執行 n 次;當 i = 1 時,內層迴圈執行 n-1 次;當 i = 2 時,內層迴圈執行 n-2 次;以此類推,當 i = n-1 時,內層迴圈執行 1 次,由此,我們可以推算出總執行次數為:
把 去掉低次項和最高次項的相乘的常數,得到這個迴圈的複雜度為
。
和平方差不多,只是多了一層迴圈:
for (i = 1; i <= n; ++i) {
for (j = 1; j <= n; ++j) {
for (k = 1; k <= n; ++k) {
// 複雜度為 O(1) 的演算法
// ...
}
}
}
其實對於這類型的迴圈,可以進行這樣的簡單計算:第一層迴圈執行 n 次,第二層迴圈執行 次,第三層迴圈執行
次,保留最高次項後就是
,所以時間複雜度為
。
指數時間的演算法,最經典的代表就是費氏數列(Fibonacci sequence):
function fibonacci(n) {
if (n <= 1) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
這個計算起來就非常複雜了,但可以知道的是當 n 越來越大時,裡面重複計算的次數也會越來越多。關於費氏數列的時間複雜度計算,可採取母函數法獲取 。我們通常把它當作
來計算。
我們可以參考下面這張圖來理解這幾種時間複雜度的差異:

資料來源: Big O Cheat Sheet
| Big O 標記 | 10個資料量需花費的時間 | 100個資料量需花費的時間 | 1000個資料量需花費的時間 |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log n) | 3 | 6 | 9 |
| O(n) | 10 | 100 | 1000 |
| O(n log n) | 30 | 600 | 9000 |
| O(n^2) | 100 | 10000 | 1000000 |
| O(2^n) | 1024 | 1.26e+29 | 1.07e+301 |
| O(n!) | 3628800 | 9.3e+157 | 4.02e+2567 |
此表格參考自 GitHub trekhleb/javascript-algorithms
我們主要用時間複雜度的數量級去評價一個演算法的時間效能。時間複雜度和兩個因素有關:演算法中的最大迴圈數和最內層迴圈中執行的次數。
空間複雜度是一個衡量演算法在執行過程中臨時佔用的記憶體大小的量度。
下面以 Two Sum 來舉例:
給定一個整數陣列 nums 和一個目標值 target,請你在該陣列中找出和為目標值的那兩個整數,並回傳它們的陣列索引(index)。
方法一:暴力列舉
function twoSum(nums, target) {
for (let i = 0; i < nums.length; i++) {
for (let j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] === target) {
return [i, j];
}
}
}
}
方法二:雜湊表
function twoSum(nums, target) {
const map = new Map();
for (let i = 0; i < nums.length; i++) {
const complement = target - nums[i];
if (map.has(complement)) {
return [map.get(complement), i];
}
map.set(nums[i], i);
}
}
這裡先不關心具體實作,我們只分析複雜度:
在方法一中透過雙重迴圈遍歷,消耗的時間複雜度為 ,採用“原地”儲存的方式,消耗的空間複雜度為 O(1)。
在方法二中引入雜湊表進行元素儲存,消耗的時間複雜度為 O(n),採用“額外”儲存的方式,消耗的空間複雜度為 O(n)。
有時候面試時會有一些題目對複雜度要求很高,例如合併兩個有序的陣列要求時間複雜度 O(n) 空間複雜度 O(1),這時就需要用一些巧妙的寫法了,例如:
function mergeArray(src, dest) {
const n = src.length;
const m = dest.length;
let indexOfNew = n + m - 1;
let indexOfSrc = n - 1;
let indexOfDest = m - 1;
while (indexOfDest >= 0) {
if (indexOfSrc >= 0) {
if (src[indexOfSrc] >= dest[indexOfDest]) {
src[indexOfNew--] = src[indexOfSrc--];
} else {
src[indexOfNew--] = dest[indexOfDest--];
}
} else {
src[indexOfNew--] = dest[indexOfDest--];
}
}
}
const src = [1, 1, 1, 1, 1, 1, 3, 5, 7, 9];
const dest = [2, 4, 6, 8, 10, 12];
mergeArray(src, dest);
console.log(src); // [1, 1, 1, 1, 1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12];
剛開始看這段程式碼可能會覺得有點難懂,不過這很正常,因為我們的大腦還沒有經過演算法的訓練,等到後面我們學完各種排序演算法,了解各種 for 迴圈的寫法套路後,再回頭看這段程式碼就會覺得很簡單了。
今天簡單的介紹了時間複雜度和空間複雜度,時間複雜度是用來衡量一個演算法的效能是否高效的一個指標,空間複雜度是衡量演算法在執行過程中臨時佔用的記憶體大小的量度,且 Big O 只是表示一個演算法的複雜度的數量級,不是一個具體的數值。
資料結構的選擇會影響到演算法的時間複雜度和空間複雜度,那麼除了我們平常在 JavaScript 中常用的陣列、物件之外,還有哪些資料結構呢?
明天開始我會介紹 JavaScript 中沒有內建的資料結構,預計會先從線性結構的 Stack、Queue、LinkedList 開始介紹,然後是非線性結構的 Tree 和 Heap。由於這些資料結構都沒有內建在 JavaScript,所以我們要自己去實作它們,透過實作的過程,我們可以更深入地了解這些資料結構的原理和特性。

