接下來登場的GAN模型同樣也是改變目標函數的Boundary-seeking Generative Adversarial Networks (BGAN),他與WGAN的訓練方式也有差距,馬上就來介紹一下BGAN的基本原理吧!
BGAN它讓生成器匹配一個目標分布,這個目標分布在一個優秀的判別器的極限下收斂到數據分布。BGAN的優點是可以減少模式崩潰的問題,並且可以使用任何形式的判別器,並無規定判別器的架構。BGAN的核心思想是讓生成器產生的樣本盡可能靠近資料分布的邊界,而不是像前幾天的GAN一樣是直接模仿資料的分布狀況。
使用一個 「完美」 的判別器 就類似強化學習 (Reinforcement Learning, RL)中的獎勵函數 (Reward Function),生成器則類似智能體 (Agent)一樣,透過不斷的生成去給判別器打分數,經過不斷的練習以後生成器的分數就會越來越高。強化學習通常也會使用策略梯度法 (Policy Gradient, PG)來直接學習最佳的策略,使用策略梯度可能可以使生成器的訓練更加穩定。
根據其原始論文的 Theorem 1. ,我們可以看到 ,它看起來非常艱深,不過這個方程式可以視為重要性採樣 (importance sampling)的問題,其中令
的
可以視為最優的重要性權重,如文章中 Definition 2.3 ,其中 β **是一個配分函數 (Partition function),方程式為
。
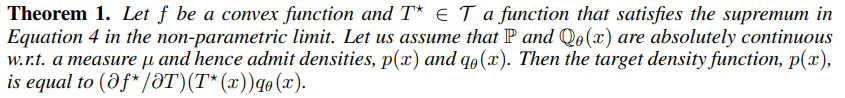

接著使用 作為獎勵的方式,可以得到基於KL散度的策略梯度公式:

接著作者使用了正規化後的 來降低公式的變異數,這會使收斂會變得較穩定,經過一連串的計算後最後得到的就是在變異數較小的條件下,基於KL散度的策略梯度公式。BGAN會根據此公式去學習最佳的策略。根據論文作者所述,BGAN的生成圖片甚至比WGAN還要好!
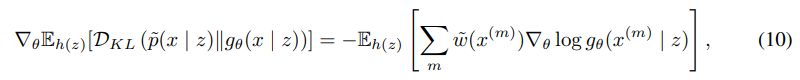
講了那麼多理論的基礎,接著要來看看所謂的完美判別器葫蘆裡到底是賣甚麼藥,因為這個部分會直接影響到之後程式要如何定義損失函數。
完美的判別器並非我們先訓練一個已經訓練好、能夠準確評分的判別器,相反的,完美的判別器其實並不容易獲得,但是我們可以用近似值,並訓練判別器逼近完美的狀態 。所以其實還是對抗式的學習,判別器學習成為一個完美判別器;生成器學習生出可以讓判別器打高分的圖片。判別器逐漸接近完美的狀態時BGAN的訓練效果就會越來越好。
首先我們要先知道最優判別器如何計算,簡單來說,我們知道GAN的目標函數: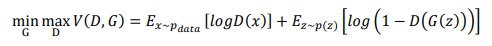
接著就對它做微分吧,微分是取得函數極大以及極小值的好方法,這個也不例外,只要找到這個函數斜率為0的地方就好。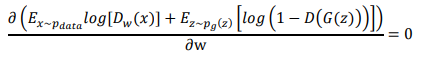
接著使用一些「小技巧」來解決它,這些就是一般微積分會遇到的鬼東西: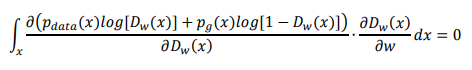
再來化簡上式: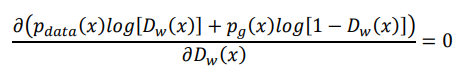
最後就可以直接計算出最優的判別器了,其數學公式表達如下: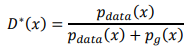
算出來然後呢?
我們思考一下, 就是生成器生成的結果,
就是真實圖片,假如這兩個東東相等的話,代表生成器已經是完美的狀態,因為生成資料與真實圖片完全相同。如果相等的話則上式結果會變成 0.5 。這個意思就是說如果生成器要生成最近似真實圖片的話,
必須等於0.5,此時
就是 決策邊界 ,也是BGAN名稱的由來。
在這種情況下,生成器生成的圖片完美到判別器無法判斷,所以期望的輸出就是每張圖片真假的機率各為50%。
現在我們可以來修改生成器的訓練目標以讓判別器對於我們生成的每一張圖片都輸出0.5的機率,此時 。有了這個概念以後接著就可以修改生成器的損失函數了:
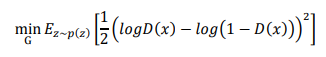
這就是我們生成器之後要寫程式時會用到的損失!
BGAN與GAN的差別有許多,其中有幾個比較重要的差異:
今天介紹了BGAN,這個GAN也相當有趣,且訓練方式與我去年所介紹的強化學習有一點點類似。題外話現在也是有許多研究是讓GAN與強化學習結合,藉此提升穩定性以及生成圖片的多樣性,但是都非常消耗運算資源XD。明天會帶各位實際做一次BGAN,BGAN在寫成程式後也並不會太複雜,所以不用擔心會被複雜的數學公式嚇到囉。

