因為 PDF Analyzer 真的太重要了,因此我們花了三個篇的篇幅在介紹他,在 Page Normalized Coordinate (PNC) 座標系統中,我們一共介紹了 4 種不同的資料取得方式,分別是單資料選取的 Input.getKeyObj() 和 Input.resolve(),還有範圍資料選取 Input.resolveRange(),今天要利用範例的方式,直接把整個 PDF 資料給抓下來,並且實際儲存起來。
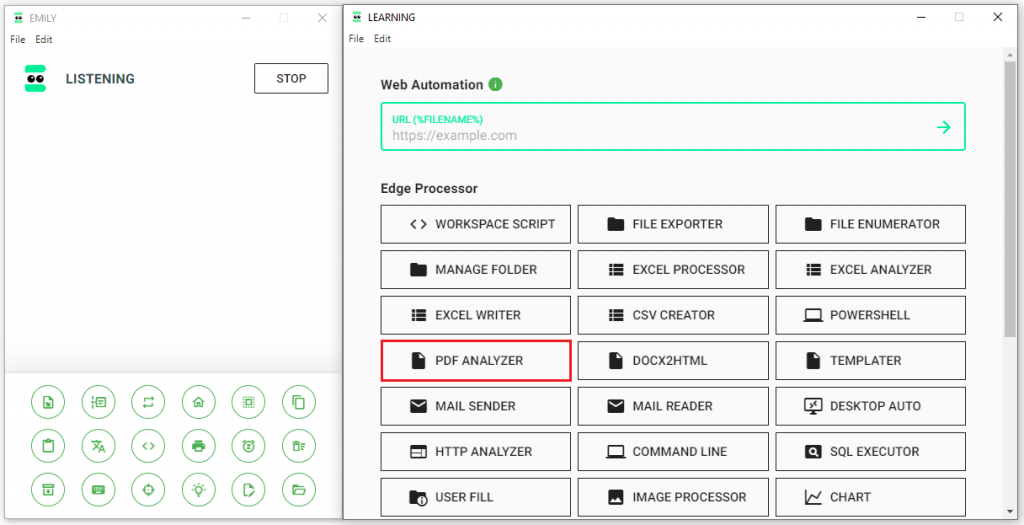
建立訓練命名技能群組,打開主畫面右邊的 PDF Analyzer 模組,今天我們要把整個 PDF 檔內的資料進行輸出。
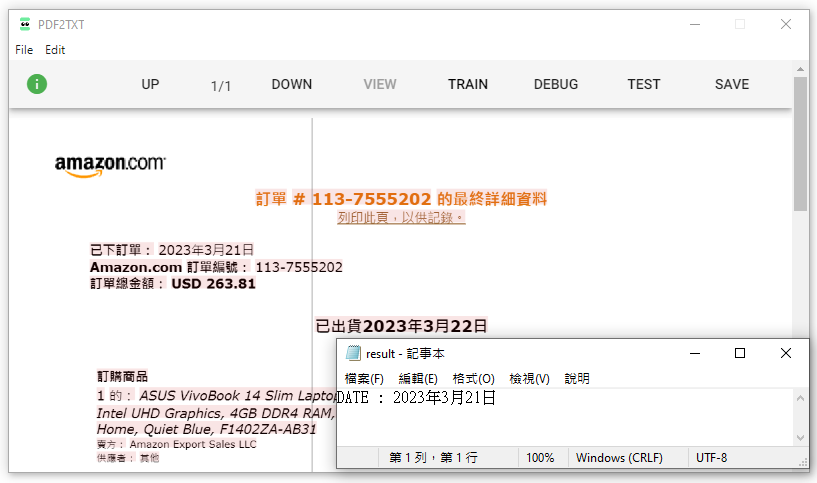
首先第一件事情是訂單的日期,我們切換到 View 查看這個 Amazon 訂單,可以看到「已下訂單」這個元素,我們點選後按著 Shift 向右,他會自動將結果做儲存,並且切換回 Train 模式中貼上程式碼,可以看到結果應該會如同下圖,我們將這個變數設定為 data。
完成後再設定一個新的變數名為 result,這個 result 是用來儲存我們的內容,後續進行資料輸出所用,我們將 result 設定。 result = result + "DATE : " + date.text,完成後進行 output 執行,我們就能打開輸出的 txt 檔案,查看 result 記事本內的資料。
let date = input.resolve( {"keyName":"已下訂單:","keyBounds":{"page":1}, "valPos":"RIGHT"})
let result = ""
result += "DATE : " + date.text
output['result'] = result
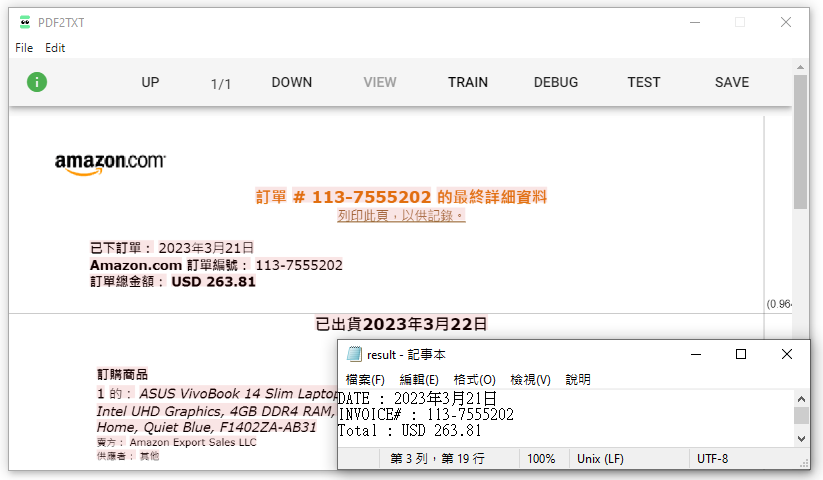
有了上面的抓取經驗,我們把範圍擴大到訂單日期、訂單編號、訂單總金額,首先根據我們要抓取的資料搜尋,並且同樣利用 Shift + 方向鍵來做資料抓取。完成後放入 result 儲存。我們一樣能夠從 result 記事本中看見我們的結果。
let date = input.resolve( {"keyName":"已下訂單:","keyBounds":{"page":1}, "valPos":"RIGHT"})
let invoice_num = input.resolve( {"keyName":"訂單編號:","keyBounds":{"page":1}, "valPos":"RIGHT"})
let total = input.resolve( {"keyName":"訂單總金額:","keyBounds":{"page":1}, "valPos":"RIGHT"})
let result = ""
result += "DATE : " + date.text + "\n"
result += "INVOICE# : " + invoice_num.text + "\n"
result += "Total : " + total.text + "\n"
output['result'] = result
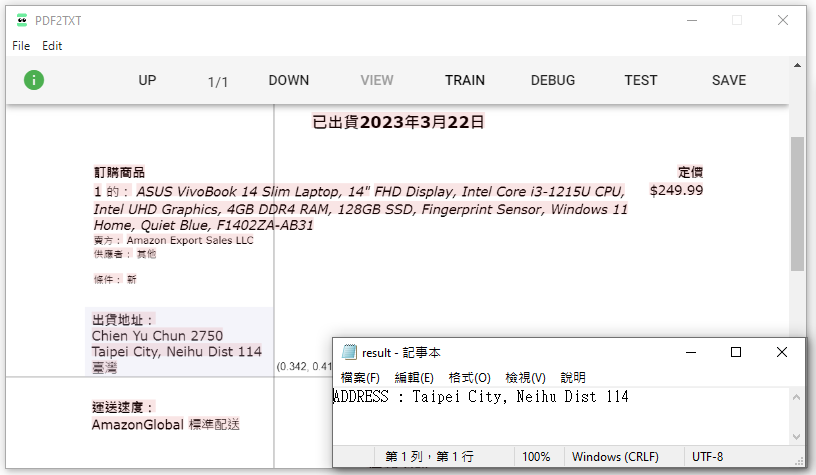
接下來要介紹的是範圍抓取,因為通常地址是比較長的,我們可以先把地址範圍給抓取出來,正常運行的情況下,可以得到以下 resolveRange 的程式碼,我們將他設定為變數 address_objs。
通常在範圍抓取時,可能有部分資料並不是我們所希望的,舉例來說這次有抓到一段 2750 的姓名資料,我可以利用程式碼把我不需要的內容給刪除掉,我們在第二行撰寫刪除程式碼,_.remove(obj, (o)=>o.text.includes('2750')),如此一來他就會把含有 ‘2750’ 的段落給刪除。
完成後我們要進行輸出,與上面不同的是,因為範圍資料是多段組成,因此輸出設定必須使用 forEach 執行,objs.forEach(t => {x = x + t.text}),可以將每一段抓取到的內容寫入。最後我們在將結果輸出。
let address_objs = input.resolveRange( {"startKeyName":"出貨地址:","startKeyBounds":{"page":1}, "valPos":"DOWN", "endKeyName":"臺灣","endKeyBounds":{"page":1} })
_.remove(address_objs, (o)=>o.text.includes('2750'))
let result = ""
result += "ADDRESS : "
address_objs.forEach(t => {result += t.text + " "})
output['result'] = result
// DATE
let date = input.resolve( {"keyName":"已下訂單:","keyBounds":{"page":1}, "valPos":"RIGHT"})
// INVOICE
let invoice_num = input.resolve( {"keyName":"訂單編號:","keyBounds":{"page":1}, "valPos":"RIGHT"})
// TOTAL
let total = input.resolve( {"keyName":"訂單總金額:","keyBounds":{"page":1}, "valPos":"RIGHT"})
// ADDRESS
let address_objs = input.resolveRange( {"startKeyName":"出貨地址:","startKeyBounds":{"page":1}, "valPos":"DOWN", "endKeyName":"臺灣","endKeyBounds":{"page":1} })
_.remove(address_objs, (o)=>o.text.includes('2750'))
//output
let result = ""
result += "DATE : " + date.text + "\n"
result += "INVOICE# : " + invoice_num.text + "\n"
result += "Total : " + total.text + "\n"
result += "ADDRESS : "
address_objs.forEach(t => {result += t.text + " "})
output['result'] = result
今天簡單了解了基本的操作概念,PDF Analyzer 是一個強大的工具,可幫助我們深入了解PDF文件的內容。無論是需要自定義處理還是僅僅想快速預覽文件,它都能滿足需求。優化了對PDF文件的分析,使其更加容易,也使其應用更加廣泛。
黃仁勳的一句話讓這個世界都瘋了,身為與數據打交道多年的我們能做些什麼呢? 很簡單就是跟著一起瘋。「You Learn the more, you Get the more.」。沒想到鐵人賽又一年了呢,這篇是 【Five mins RPA】 系列文章除此之外也歡迎大家走走逛逛關於我過去的文章
一個正在為 300 多萬訂閱的 Youtuber 服務的資料科學家,擅長將商管行銷導入機器學習與人工智慧,並且從大量的數據中找出 Insight,待過 FMCG、Communication、Digital Marketing,最近一直在資訊圈打滾,趕著不被這波人工智慧浪潮給吞噬,寫文章寫了好一段時間了,期待著這個社會每個人能在各個角力間不斷沖突而漸能找到一個平衡點並回歸最初的初心。


 iThome鐵人賽
iThome鐵人賽