
昨天經歷了數學的摧殘(?)以後,今天來點輕鬆一點的內容吧~
截至目前的文章已經介紹了 GAN 和 VAE 兩種類型的圖像生成模型。其實,我們還可以進一步結合兩者的優點組合新的模型:VAE-GAN。
這樣的組合有什麼樣的優點呢?話要說回原始版本 VAE 的問題。
VAE 預設是以輸入影像和還原影像每個 pixel 值的差距來評估模型還原影像能力的好壞,然而,我們可以試想以下兩個例子:
從以上的例子我們可以發現,用影像 pixelwise 的差距當作影像差異的衡量指標,和人視覺上的感受是不完全一致的。
而要改善這樣的問題,其中一個方向是用高階且穩健(robust)的影像表徵來評斷影像的相似程度,此處「高階」指的是具有抽象視覺意義的資訊,而不只是局部的筆劃或色塊等資訊。
GAN 就是用 discriminator 來判斷真實和生成影像分布的相似程度,藉此可以產生非常逼真的影像。因此我們可以應用這樣的想法來判斷真實影像樣本和 VAE 還原的影像樣本的相似程度,並藉此評估 VAE 重建影像的品質,讓還原影像和真實影像在視覺感受上更加相像。而如果 VAE 能更好的還原影像,也代表它學到的影像表徵更能代表原本的輸入影像,充分學習到真實影像的分布。
VAE-GAN 的架構如下: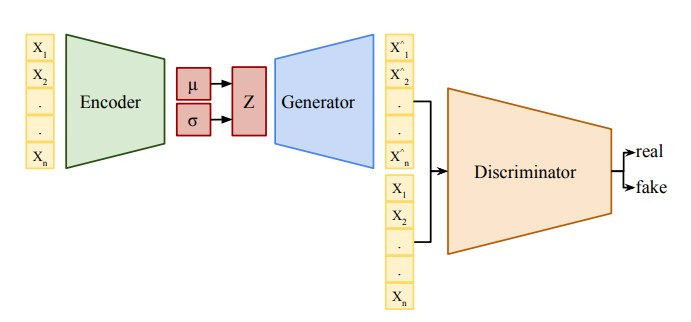
(圖片來源:Variational Autoencoder Generative Adversarial Network for Synthetic Data Generation in Smart Home)
由於 VAE 的 decoder 和 GAN 的 generator 的功能都是將 code z 轉換為影像 x,因此 VAE-GAN 結合了 VAE 的 decoder 和 GAN 的 generator。
VAE-GAN 會有三個學習目標: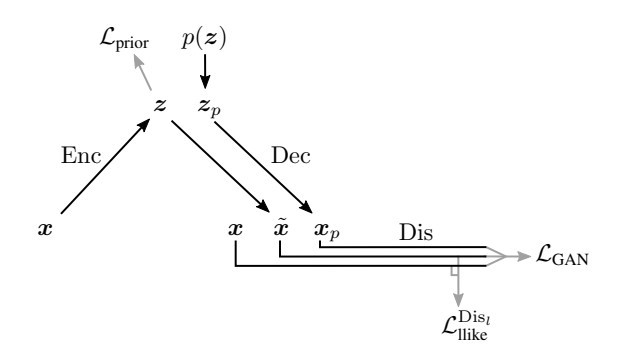
(圖片來源:Autoencoding beyond pixels using a learned similarity metric)
接著我們來看看 VAE-GAN 的表現如何吧~

(圖片來源:Autoencoding beyond pixels using a learned similarity metric)
從以上這些生成和重建的人臉影像可以發現,單純使用 VAE 得到的圖雖然臉部的中間是清楚的,但邊緣明顯模糊。
而 VAE_Dis 指的是 VAE 和 GAN 分開訓練,VAE 透過預訓練好 discriminator 得到影像特徵相似程度,並進行訓練。這樣的做法雖然產生的人臉影像清晰很多,但同時也產生了不自然的 artefacts,例如影像中的有些固定間距的直線,以及部分重建影像的右下角有藍色的 noise patterns。
而 VAE-GAN 和 GAN 產生的人臉影像,效果算是比較好的。
除此之外在 VAE-GAN 的 paper 也探討了模型學習的表徵是否含有比較高階的視覺意義,它實驗的方法是讓生成模型產生和特定一張人臉影像(query)具有相同特性的新影像,而結果如下圖:

(圖片來源:Autoencoding beyond pixels using a learned similarity metric)
值得注意的是下面這個例子,query 是一張有帶眼鏡的人臉,而只有 VAE-GAN 產生的人臉比較明顯看得出有眼鏡,這就證實了 VAE-GAN 能學習到高階的視覺特徵,因此能學到眼鏡的特性。而原始的 VAE 因為是使用像素差值來評斷影像是否相似,而眼鏡只占影像的極少像素,就不容易再生成影像重現這樣的特性了。
在查詢關於 VAE-GAN 的資訊時,我也注意到後續有不一些關於這個模型的應用,在此列舉出來提供給大家參考:

