今天繼續延伸 VAE 的主題,會分別介紹兩個基於 VAE 改良的變形:β-VAE 和 DFC-VAE。這兩種變形改良的方向和帶來的效果都不太一樣,讓我們繼續看下去~
β-VAE 是 DeepMind 團隊在 2016 年提出的 VAE 的變形(paper: β-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework),而 2018 年他們又對 β-VAE 提出進一步的解釋與改良(paper: Understanding disentangling in β-VAE)。
關於 β-VAE 的研究比較著重在如何更好的學習到影像中的表徵,讓我們能從表徵中明確拆分出不同的視覺因子。以人臉影像為例,這個研究即希望模型能學習到人臉影像的身分、角度、光照分別是不同因子。
這系列的研究不只與生成影像相關,因為當模型如果可以學習到跟高階視覺意義有關的資訊,這些資訊更可以應用在影像分類等其他用途。
還記得在 VAE 的數學原理提到,以下的式子是 VAE 學習的目標函式的 lower bound(evidence lower bound, ELBO),它又可以拆分成還原影像與真實影像的 reconstruction likelihood,以及後驗分布 q(z|x) 和先驗分布 p(z) 的 KL divergence: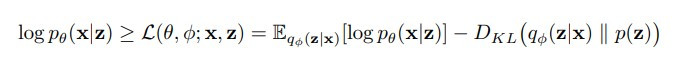
(圖片來源:Understanding disentangling in β-VAE)
而 β-VAE 就是在這個目標函式中加入了一個可以調整的超參數 β(在機器學習領域中,參數通常是模型從資料中學習的,超參數則是人訂的),修改過的式子如下: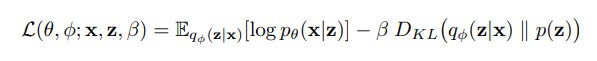
(圖片來源:Understanding disentangling in β-VAE)
由於 β 通常大於 1,因此模型會更關注學習讓後驗分布 q(z|x) 接近先驗分布 p(z),作者認為這樣的做法能限制 code 分布的範圍,進而依照因子排列影像資訊,因此我們能得到更接近視覺意義的影像表徵。
然而限制 code 分布範圍的過程也會造成一些資訊損失,因此還原影像的效果通常相較於原始的 VAE 會差一些。
DFC-VAE(Deep Feature Consistent Variational Autoencoder)是 2016 年被提出的 VAE 變體,它的出發點和昨天介紹的 VAE-GAN 有點像,都是想用深度影像特徵的相似程度來評估 VAE 重建影像的品質,取代原本利用影像像素值估算相似程度的做法。讓重建影像和真實影像更符合我們視覺上的「相似」。
DFC-VAE 的模型架構如下圖: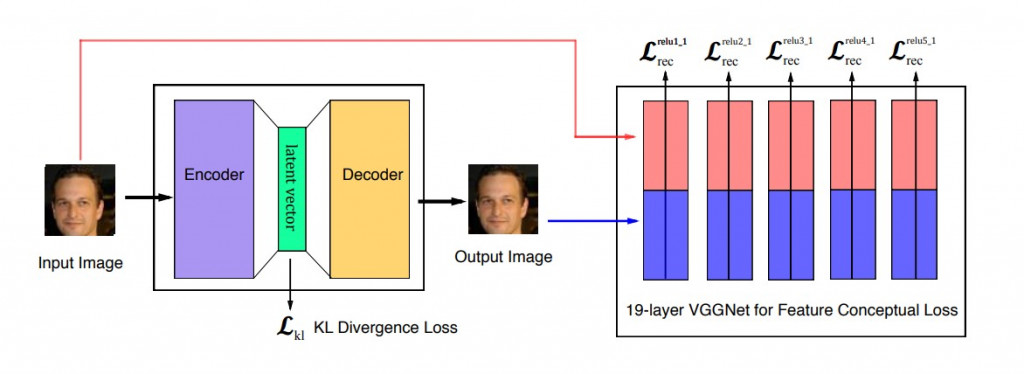
(圖片來源:Deep Feature Consistent Variational Autoencoder)
DFC-VAE 包含原本 VAE 有的 encoder 和 decoder 架構,並另外利用一個預訓練好的 VGGNet 來萃取影像的從淺層到深層的特徵,而 VAE 的學習目標就變成要讓重建影像各個階層的特徵都與真實影像接近。
下圖是 DFC-VAE 生成人臉影像的效果:
(圖片來源:Deep Feature Consistent Variational Autoencoder)
可以看到原始的 VAE 如同之前提過的,生成的影像總是比較模糊。而基於 GAN 的方法產生的影像雖然富有細節,但人臉會有變形、不自然的情況。而要求淺層特徵一致性的 DFC-VAE(VAE_123)比起要求深層特徵一致性的 VAE_345 表現較好,五官是比較清晰且自然的。
而關於 DFC-VAE 重建人臉影像的能力,可以參考下圖的效果:
(圖片來源:Deep Feature Consistent Variational Autoencoder)
可以看到要求淺層特徵一致性的 DFC-VAE(VAE_123)對於還原人臉局部的細節(例如五官)效果較好,且與原圖較無色差。
今天就先這樣啦~原本還想研讀一下看起來表現蠻好的 VQ-VAE,不過由於準備時間不足,只好之後找機會再介紹

