"Transformer模型" 是一種深度學習架構,最初由Google於2017年提出。它是一種用於處理序列數據的神經網絡架構,特別在自然語言處理任務中表現出色。Transformer的核心思想是注意力機制(Attention Mechanism),它允許模型專注於序列中不同位置的重要信息,從而實現了在長序列中建立上下文感知的能力。
下面這張圖是來自Hugging Face官網的 Transformer 發展史
![]()
Transformer 模型最初是為了解決翻譯任務而設計的,但 Transformer 模型的成功啟發了更廣泛的應用領域,隨後推出了幾個有影響力的模型。
(以下取自官方網站)
上述的所有Transformer 模型(GPT、BERT、BART、T5 等)都被訓練成語言模型。這意味著他們已經以無監督學習的方式接受了大量原始文本的訓練。無監督學習是一種訓練類型,其中目標是根據模型的輸入自動計算的。這意味著不需要人工來標記數據!
這種類型的模型可以對其訓練過的語言進行統計理解,但對於特定的實際任務並不是很有用。因此,一般的預訓練模型會經歷一個稱為遷移學習的過程。在此過程中,模型在給定任務上以監督方式(即使用人工註釋標籤)進行微調。


上面這一段話我知道可能會有點看不懂(Transformers 是語言模型),這段是官方教學的其中一段,我這邊先解釋幾個名詞的意思,再用比較短的話講述上述的重點
預訓練:預訓練是指在大規模的文本數據上訓練模型,使其學習通用的語言表示。這一階段模型是無監督地學習的,
因此不需要人工標記的數據。預訓練的目標是讓模型理解自然語言中的語法、語義和文本結構。BERT、GPT等模型都是通過預訓練來學習語言表示的。
微調:微調是指在特定任務上使用預訓練模型,並根據任務的需要對模型進行有監督的調整。
這通常涉及到使用人工標註的數據,如文本分類、命名實體識別等任務。微調過程重點在將預訓練的通用語言理解能力轉化為特定任務的性能。
遷移學習:遷移學習是一種學習方式,它強調了在不同但相關任務之間共享知識的能力。在NLP中,預訓練和微調就是一種遷移學習的應用。
預訓練模型在大規模數據上學到了通用的語言知識,然後通過微調來應用這些知識到特定任務,從而加速了模型在特定任務上的收斂和性能提升。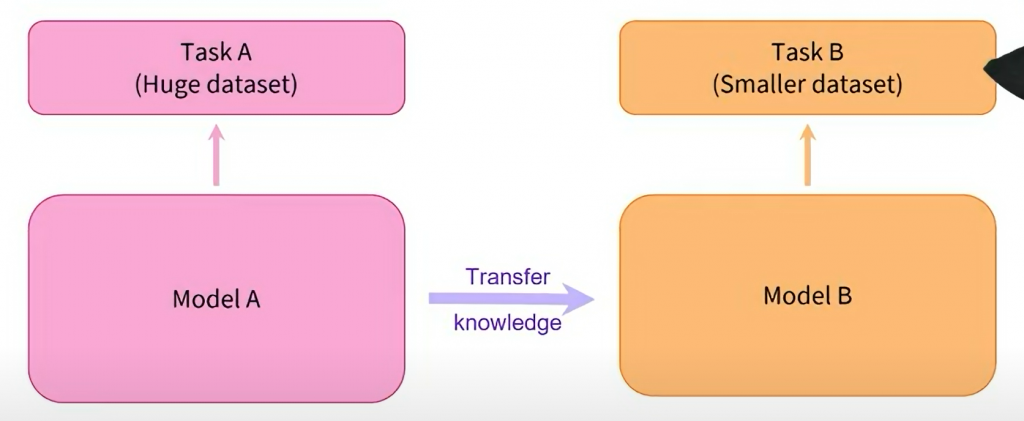
這段話的重點是強調了Transformer模型的兩個關鍵階段,預訓練和微調。理解這兩個概念對於有效利用預訓練模型來解決各種NLP任務至關重要。
這是深度學習在NLP領域取得成功的關鍵之一,因為它允許模型利用大規模的無監督數據進行學習,並將這些學習應用到各種具體任務中。
#說一下下一篇會講的是 Transformer 的架構

