Transformer 模型架構主要由兩個區塊組成,左側是 Encoder(編碼器),右側是 Decoder(解碼器)
![]()
(這邊先簡單說明,下一章節回詳細解析兩個部份的內部結構)
這兩個部分也可以獨立使用,會取決於 什麼類型的task
它是 Transformer 模型的最重要的核心組件之一,用於處理序列數據,無論是在編碼器還是解碼器中。它的作用就像是模型的注意力系統,可以動態地為輸入序列中的每個元素分配不同的注意力權重,以捕捉元素之間的關係。這個自注意力機制由三部分組成,分別是查詢(Query)、鍵(Key)、和值(Value),模型通過計算它們之間的關係來生成注意力權重。這個機制讓模型可以同時處理不同元素之間的長程和短程依賴關係。
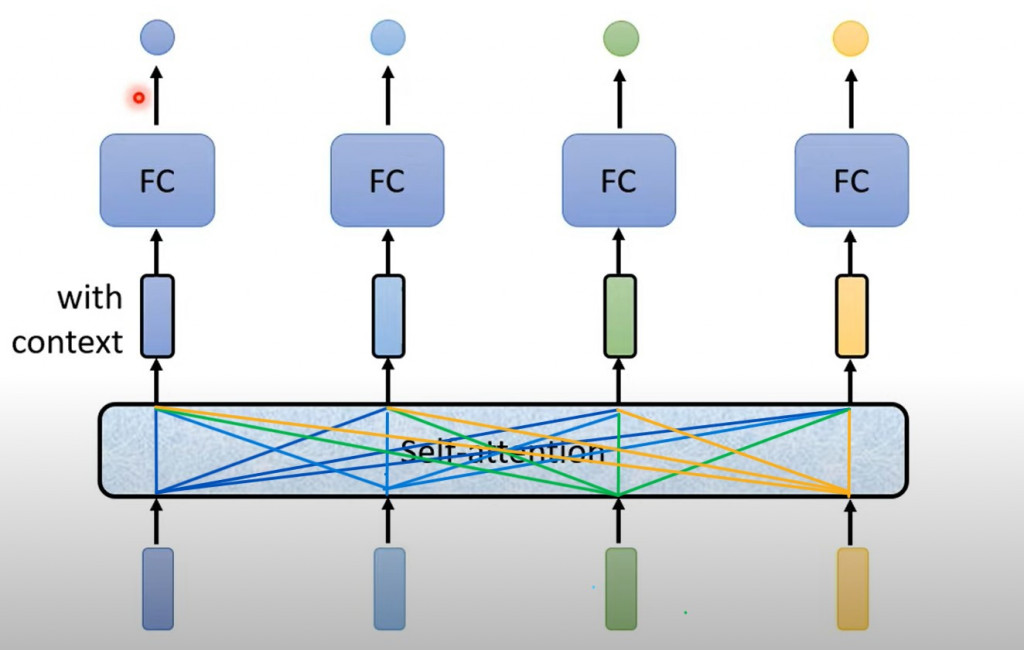
圖片來自:Hung-yi Lee老師(YT)
下方代表一整個 Sequence,假設他輸入有四個 vector,那輸出也會是四個 output vector,但這四個 output vector 不是單一考慮一個小的範圍而是考慮一整個 sequence 才得到的,所以最後就是考慮一整個 Sequence 的資訊然後決定要輸出怎麼樣的 output(所以中間才會連那麼多線)

