在介紹完 GAN 和 VAE 後,今天開始要進入到第三種生成式模型-flow-based model
在為了瞭解 flow-based model 參考了一些課程和文章後發現,這一系列的模型有很多數學原理需要解釋
不過別擔心,今天的內容會比較輕鬆的簡介 flow-based model 的架構,以及用 OpenAI 在 2018 年發布的 Glow(優化的 flow-based model)demo 合成人臉影像,大家可以一起動手玩玩看~(介紹了那麼久的影像生成模型,終於有機會讓大家實際玩玩看啦
由於還沒有介紹 flow-based model 的數學原理,所以這裡先簡單介紹它是怎麼訓練和運作的,至於背後的原因在講到數學原理時就會比較清楚了。
Flow-based model 會訓練一個特定架構的 encoder,而 encoder 就是將影像投射到 code 空間的函數。訓練完之後,取 encoder 的反函數(inverse function)就可以得到能將隨機的 code 轉換為影像的 generator。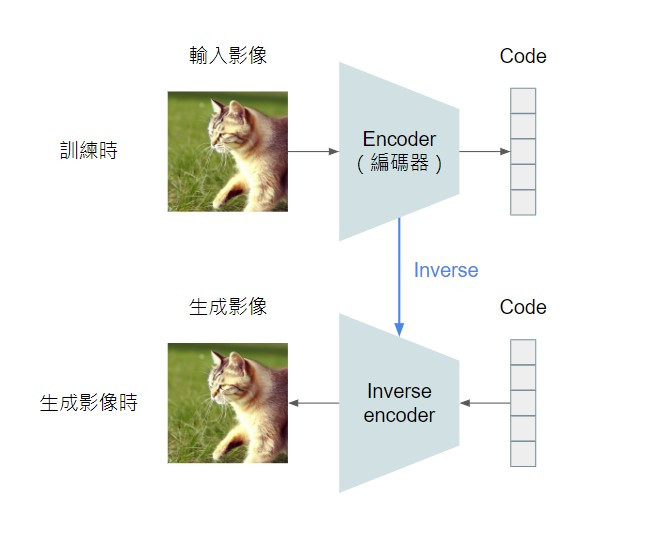
不過,為了容易計算 encoder 的反函數,encoder 的架構是特別設計過,也因此有諸多限制,進而影響生成影像的表現,因此 flow-based model 會串接好多個 generator,將原本簡單的常態分佈(code 的分布)一步一步轉換為複雜的影像分布,也因此這類模型有「flow」這樣的命名。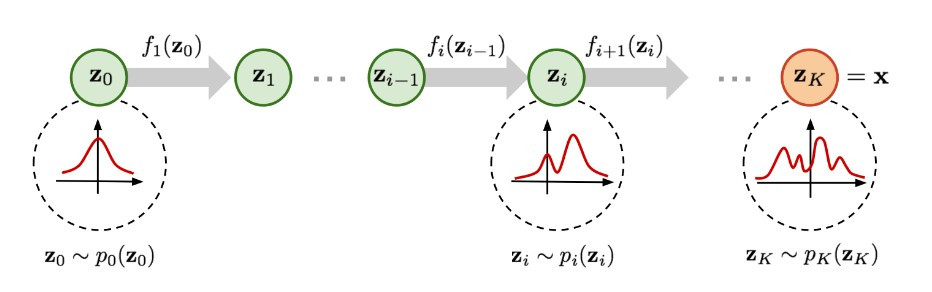
(圖片來源:Flow-based Deep Generative Models | Lilian Weng)
Glow 是 OpenAI 在 2018 年發表的改良 flow-based model,這個研究除了有開源程式碼以外,也發布了一個 demo 網頁,讓大家可以按幾個按鈕就能簡單操作看看,瞭解 Glow 在影像生成與合成的效果。
網頁連結在此:Glow: Better reversible generative models
網頁的首圖就展示了使用 Glow 合成人臉影像的效果,雖然看起來不及 GAN,但是以 GAN 以外的生成模型來說表現算是很好了: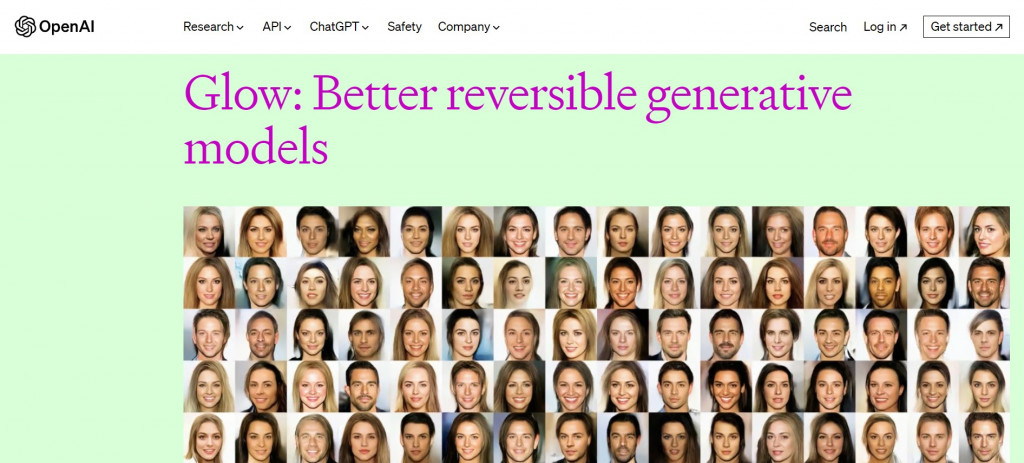
而網頁往下滑,除了會有關於 Glow 的介紹,還會看到這個互動式的展示,這裡展示了兩種類型的人臉影像合成,其中一個是利用拉桿就能調整人臉影像的特性,包括是否微笑、年齡、金髮等等。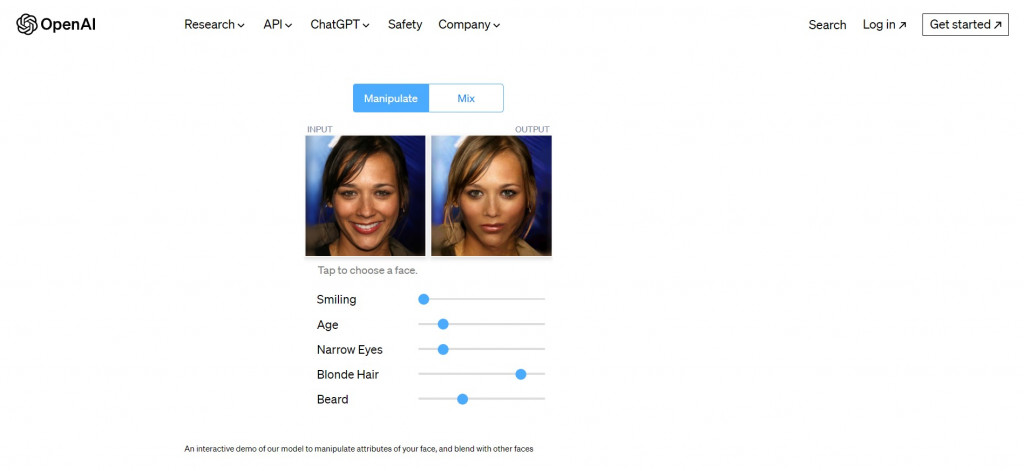
在 Glow 訓練的過程中,訓練資料並不會帶有這些人臉特性的標註,而之所以我們能控制 Glow 產生具有特定性質的人臉,是 OpenAI 在模型訓練好後分析影像表徵(code)和人臉特性的關係,進而達到控制影像生成的效果~
這裡展示的另一種人臉影像合成是將兩張不同人的臉合成成一張臉的影像,效果如下: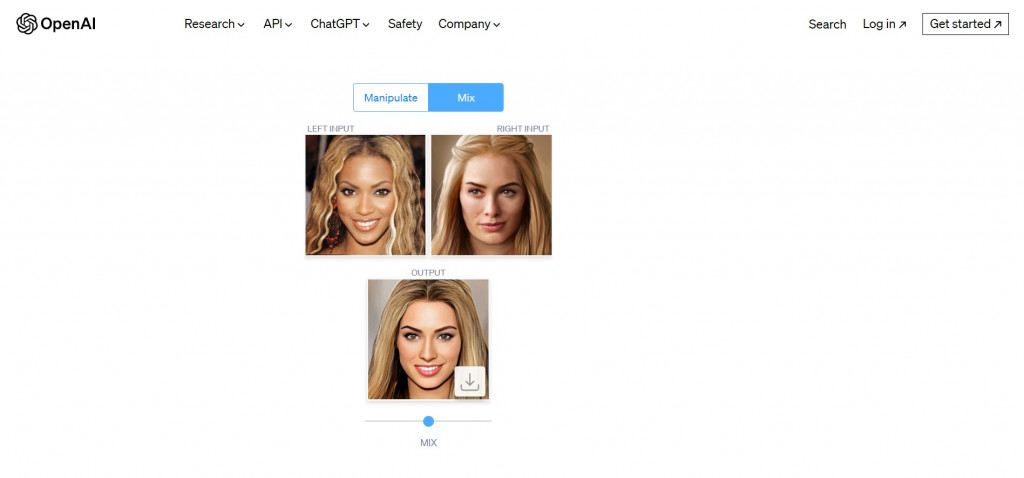
如果兩張人臉的特性沒有差異太大,效果看起來蠻好的~
不過如果輸入的兩張人臉影像差異太大,合成的影像還是會明顯不自然: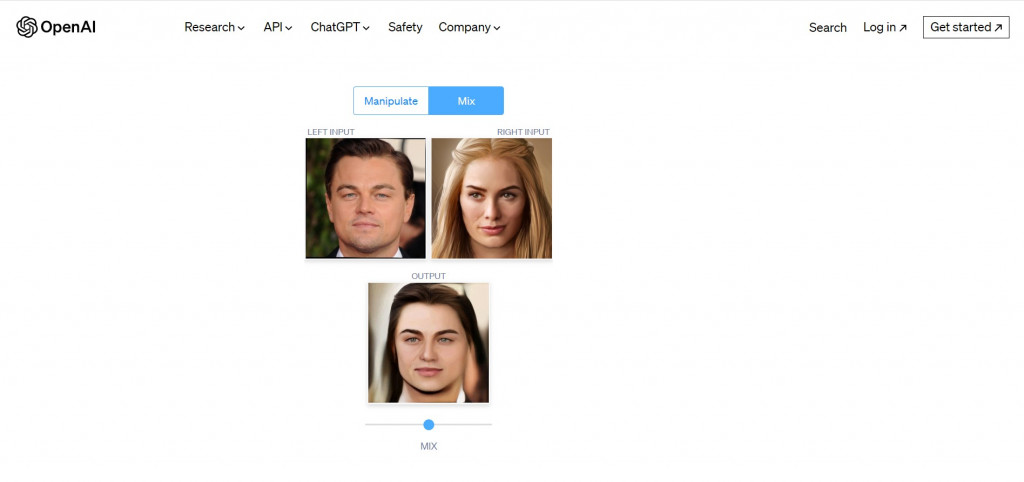
而這兩個 demo 除了可以使用 OpenAI 提供的範例影像,也可以自己上傳人臉影像,如果...不介意傳送個人照片的話,也可以拿來玩玩看合成的效果喔
那今天就這樣啦~明天就要開始介紹 flow-based model 的數學原理啦

