
電腦要如何辨認這些由「0」、「1」組成的位元字串代表什麼文字呢?
其實是使用編碼系統將文數字等資料轉換成「二進位」
常見的編碼系統有ASCII, Unicode, EBCDIC(IBM的)等
ASCII(唸作Ass-key) 是美國國家標準局在 1963 年發表的一套基於拉丁字母的電腦編碼系統,為當今最普及的公定標準。最初是由電報碼發展而來
正規版的 ASCII 是以 7 個位元儲存一個字符,而先前有提到電腦常用的儲存位元數為 8 個位元
那麼這個多出來的一個位元要做什麼呢?怎麼處理呢?
這個多出來的位元有時就用來儲存「錯誤檢驗位元」 (Parity Bit) 用的
另外,也有些擴展版本的 ASCII 是以 8 個位元儲存一個字符,像是 apple,共有五個字符,所以就會需要 40 個位元來儲存(= 5 個位元組)它。 擴展版本的 ASCII 比正規版多了一倍的儲存量
那這些多出來的要做什麼用呢?
通常是用來儲存「非英文的符號」、「圖形符號」、「數學符號」等
附上一張 ASCII 對照表的其中某部分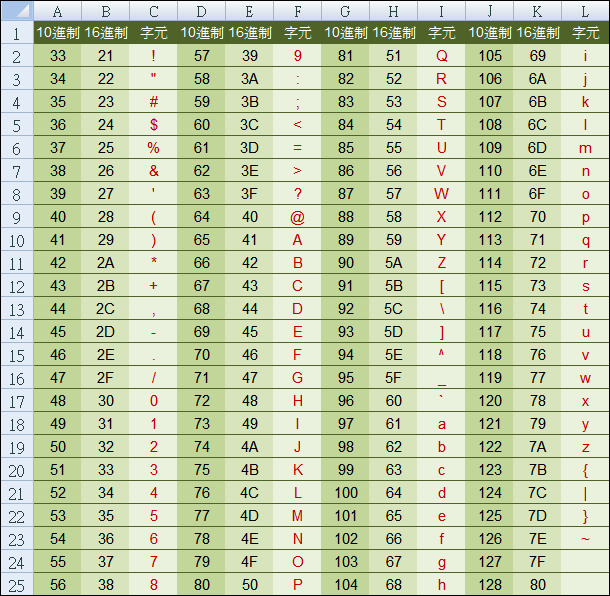
其中 ...
A 用十進制表示是 65, B 是 66 以此類推...
a 用十進制表示是 97, B 是 98 以此類推...
0 用十進制表示是 48, 1 是 49 以此類推...
可以留意一下小寫的a所代表的十進位數值是最大的,有些人會稍微記一下大小寫的 a 和 0 開頭的數字
這些年來原本的文字編碼已經沒有辦法滿足其他國家的文字,也不是 8 個 位元(256種組合)所能表達的完的,所以造就了以兩個位元組(=16 個位元; 65536種組合)進行編碼的 Unicode 誕生~~解決 ASCII 不夠用的問題
附上完整的 ASCII 常用對照表
Unicode 就是一般俗稱的「萬國碼」,大陸地區稱之為「統一碼」,由美國萬國碼制定委員會於 1988~1991年間訂定,已成為國際標準局ISO認證(ISO10646)之標準,全球通用。目前發展出多種編碼形式,主要為
UTF-8 (WWW 全球資訊網所採用)
UTF-16 (JAVA 及 Window 所採用)
UTF-32 (一些 UNIX 系統所使用)
UTF-8, UTF-16 , UTF-32 分別代表每個字符以8 , 16, 32 個位元來表示一個字符
萬國碼的前面 128 個符號來自於 ASCII ,其他都是其他國家常用之文字,像是英、中、日、韓文等
詳情可見 unicode 官網 https://home.unicode.org/
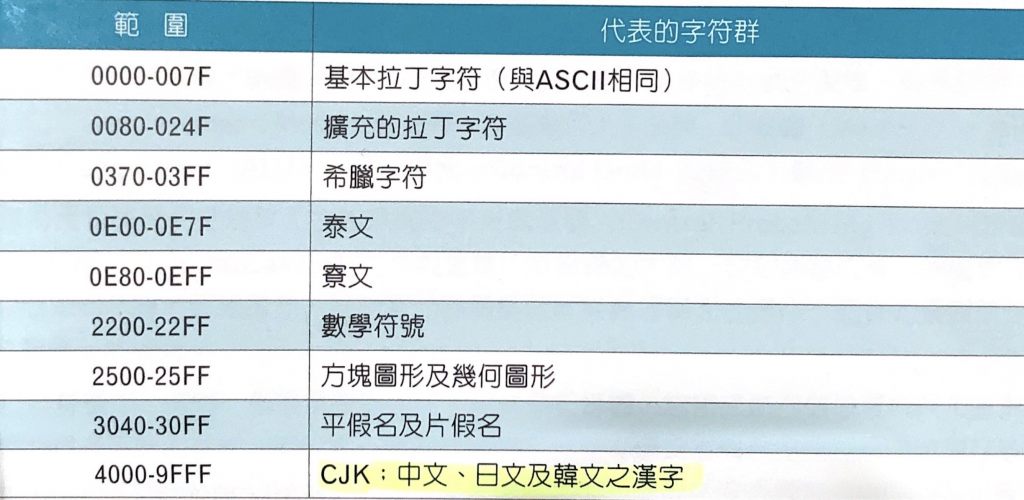
Unicode 符號對照簡表
在 Unicode 中,最大宗的分類就是 CJK,主要是中、日、韓文之漢字級,可以透過下面的 pdf 來找出你要的文字編碼,可以嘗試看看找自己的名字喔😆
https://unicode.org/charts/PDF/U4E00.pdf
Big-5 是以種存於電腦內部的「中文編碼」,屬於內碼,每個字元以 16 個位元來表示一個中文字、標點符號、注音、全形英文字母。Big 5 的字體已慢慢的整合在 Unicode CJK 字級中
在寫文章時,第一次聽到這個交換碼,原來..
EBCDIC 是 IBM 於 1963年-1964 年間推出的字元編碼表,每個字元以 8 個位元來表示。它的缺點是英文字母不是連續地排列,中間會出現多次斷續,為工程師帶來了一些困擾
電腦是使用編碼系統將文數字等資料轉換成「二進位」,常見的編碼系統有ASCII, Unicode, EBCDIC(IBM的)等。一個字符所代表的位元依照不同編碼系統而不同。不論在哪個程式語言和機器中,也不論用著什麼母語,每個字符在萬國碼中都有一個唯一的代碼


 iThome鐵人賽
iThome鐵人賽