今天我們要針對昨天說到的三個部份的第一個部分 Tokenizer 來做說明 (會先講一半)
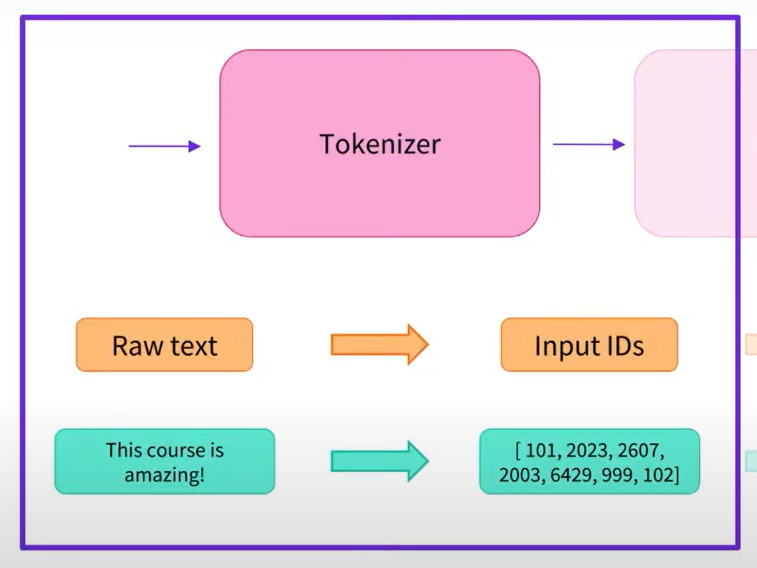
以上圖出自 Hugging Face 官方
Tokenizer 的主要功能是將自然語言文本轉換為機器可理解的形式,Tokenizer 接受原始文本作為輸入,並將其分解成詞彙或子詞(subwords)的序列,每個詞彙或子詞通常對應到一個唯一的數字 ID。這個轉換過程稱為 "tokenization",它將文本轉換成機器可理解的形式,使得模型能夠處理它們。
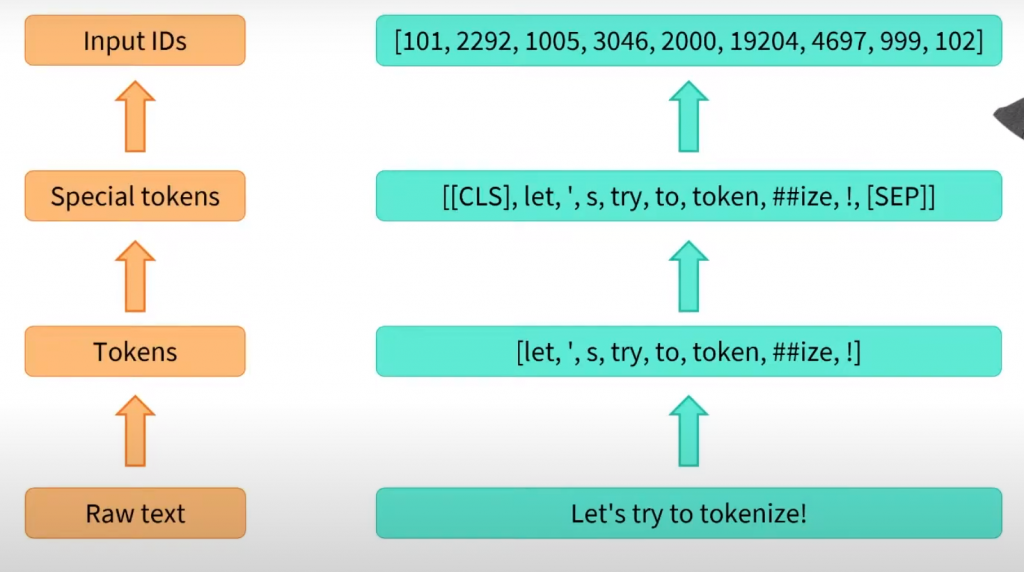
以上圖出自 Hugging Face 官方
通常這個動作稱為標記 (token)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
['Using', 'a', 'Trans', '##former', 'network', 'is', 'simple']
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
[7993, 170, 11303, 1200, 2443, 1110, 3014]
final_input = tokenizer.prepare_for_model(ids)
print(final_input['input_ids'])
[101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102]
預訓練模型而不同,我們使用的是 BERT Tokenizer,所以最後的 final 輸出前加上了 101 後面加上了 102
下一章我們繼續把剩下的 Tokenizer 的部分完成 (●'◡'●)

