早期提出的經典的 flow-based model 包括 NICE(NICE: Non-linear Independent Components Estimation)和 RealNVP(Density estimation using Real NVP),但可能由於背後的數學原理比較複雜,產生影像的效果也不夠令人驚艷,因此相較於 GAN 和 VAE,比較少受到注意。
而如同在[Day 13] 簡介 flow-based model 以及試玩人臉影像合成提到的,OpenAI 在 2018 年提出基於 NICE 和 RealNVP 改良的 Glow(Glow: Generative Flow with Invertible 1×1 Convolutions),並提供簡單但效果不錯的人臉影像合成 demo,這也讓比較多人注意到 flow-based model~
而今天的文章要介紹的就是 Glow,包括它單一 flow step 的架構(也就是之前提到的 flow-based model 中串接的任一個 generator),還有整體如何串接起來,以及生成影像的效果。
不過在此之前先補充一下在[Day 14] Flow-based model 的數學原理(一)簡介的 Jacobian matrix 與 flow-based model 數學原理的關聯(之前好像漏掉了啊
昨天的文章有提到,flow-based model 的學習目標可以整理成以下的形式: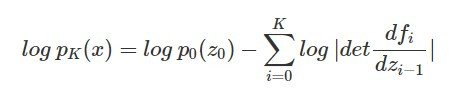
其中的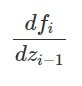 就是 z_(i-1) 轉換到 z_i 的 Jacobian matrix,而上面式子的第二項就要求出每個階段轉換的 Jacobian matrix 的 determinants,再取 log 並加總起來。
就是 z_(i-1) 轉換到 z_i 的 Jacobian matrix,而上面式子的第二項就要求出每個階段轉換的 Jacobian matrix 的 determinants,再取 log 並加總起來。
要計算高維 Jacobian matrix 的 determinant 似乎很困難,但由於轉換函式是特意設計過的,得到的 Jacobian matrix 會是 triangular matrix,因此它的 determinant 就是矩陣對角線所有元素的乘積,log likelihood 的計算也就容易達成。
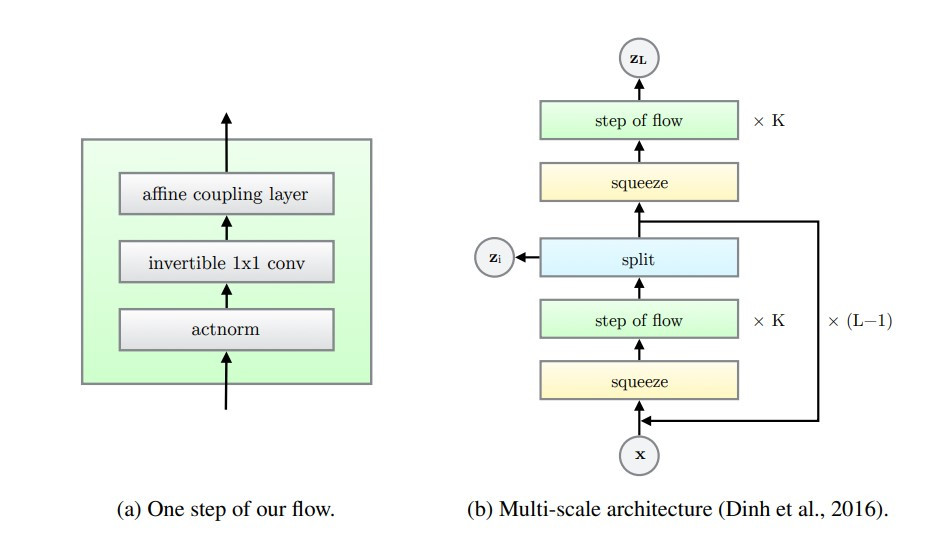
(圖片來源:Glow: Generative Flow with Invertible 1×1 Convolutions)
Glow 的模型架構如上圖,左半邊的圖是指每個 flow step 由一個 actnorm、一個 1x1 invertible convolution layer 和一個 affine transformation 構成,左邊的圖則是組合多個 flow steps 的結構。
Actnorm 代表的是 activation normalization,它會對 activaions 的每個 channels 進行仿射轉換(affine transformation),效果類似 batch normalization。它的初始化與資料有關,參數是可以跟著模型被訓練的。
Affine coupling layer 是在 NICE 和 RealNVP 就提出的方法,它的反函數和 log determinant 是很容易計算的。
Affine coupling layer 會將輸入依照 channel 拆分成兩半,其中一半的輸入本身不進行任何轉換,但會透過它得到用以轉換另外一半輸入的參數,最後將未轉換的一半與轉換後的一辦組合在一起,就得到輸出。
雖然這個 layer 的計算很簡單,但單純串接多個 affine coupling layer 會有一個顯而易見的問題,那就是會有一半的 channels 從頭到尾都沒有經過任何轉換,因此 NICE 和 RealNVP 就必須在每個 flow step 之後重新排列 channels,確保各個 channel 都能在 flow step 被轉換到。
而在 Glow paper 提出的 1x1 invertible convolution 就是解決這個問題一般性方法。
在 NICE 和 RealNVP 中,是依照人定的規則來重新排列 channels,而 Glow paper 提出的 1x1 invertible convolution 則是讓模型學出轉換的參數。假設輸入的 channel 數量為 c,1x1 invertible convolution 就是一個 cxc 的矩陣,而轉換後的輸出 channel 也是 c,但轉換後的每個 channel 會包含輸入的不同 channels 的資訊,因此不用擔心 affine coupling layer 一次只會轉換一半 channel 的問題。
之前試玩 OpenAI 提供的互動式 demo時,我們可以將兩張人臉影像合成成一張,其實不只將兩張影像對等的合在一起,我們也可以讓其中一張影像對合成影像的影響占比多一點或少一點:
(圖片來源:Glow: Generative Flow with Invertible 1×1 Convolutions)
而它的做法很簡單,首先我們必須找到兩張真實影像對應到 code space 的位置(找到代表兩張影像的 code),然後我們只要依照不同比例內插兩個 code,再透過 Glow 將內插後的 code 轉換為影像,就可以得到組合兩張人臉特徵的合成影像了!
而如果要改變人臉影像的臉部特性(例如表情、膚色、髮色等),我們必須找到這些特性大概在 code space 的什麼方向,然後將真實影像的 code 往那個方向移動,通過 Glow 就能得到具有特定特性的合成人臉影像了。在 paper 中展示的效果如下:
(圖片來源:Glow: Generative Flow with Invertible 1×1 Convolutions)
總感覺...demo 呈現的效果比較明顯

