本篇開箱Tesseract.js是能圖像中取得文字的工具
Tesseract.js 是一個 JavaScript 函式庫,它是基於 Google 的 Tesseract-OCR 引擎的封裝,用於文本光學字符識別(OCR)任務。它允許開發人員在網頁應用程序或 Node.js 環境中執行 OCR,將圖像中的文本轉換為文字
官網 https://tesseract.projectnaptha.com/
github https://github.com/naptha/tesseract.js#tesseractjs
Tesseract OCR 可以說是目前最普遍被使用的光學字元辨識(Optical Character Recognition,OCR)引擎,他可以自動辨識出圖片中的各種文字,支援 UTF8 編碼,可以辨識超過 100 種語言,辨識的結果可以輸出成各種檔案格式。
https://officeguide.cc/tesseract-open-source-ocr-engine-tutorial-examples/
CDN
<!-- v5 -->
<script src='https://cdn.jsdelivr.net/npm/tesseract.js@5/dist/tesseract.min.js'></script>
或
Node.js
npm install tesseract.js
或
yarn add tesseract.js
const { createWorker } = require('tesseract.js');
const worker = await createWorker('eng');
(async () => {
const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png');
console.log(text);
await worker.terminate();
})();
前往>> 官方範例
createWorker是一個創建 Tesseract.js 工作的函數
Worker.terminate() 終止工作執行緒並進行清理
Worker.recognize() 提供 Tesseract.js 執行 OCR 的核心功能
前往>> 官方API文件
今天範例就將官方基本使用轉成vue3吧!
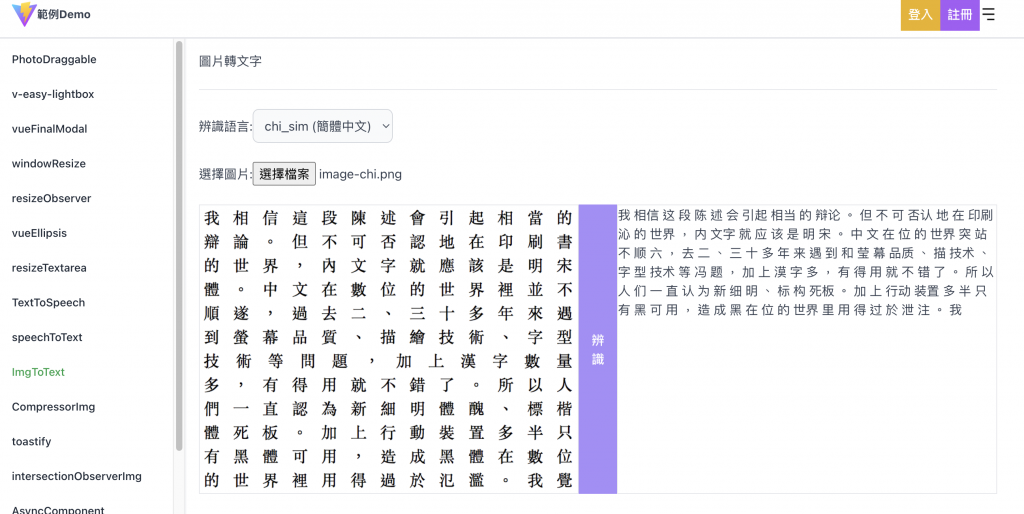
Demo網址:https://hahasister-ironman-project.netlify.app/#/imgToText
功能大綱
-選擇語言/檔案上傳預覽,辨識>回傳辨識結果
備註
-指示要下載的訓練語言資料時,若需要多種語言則用+連接,例如:eng+chi_traconst worker = await createWorker('eng+chi_tra');
前往>> 支援語言包清單
安裝npm install tesseract.js
版本
"tesseract.js": "^5.0.2"
<template>
<div class="container">
<div>
<input type="file" @change="processImage" accept="image/*" />
<select
v-model="selectedLang"
class="block p-2.5 w-full bg-gray-50 rounded-lg border border-gray-300 focus:ring-blue-500 focus:border-blue-500"
>
<option v-for="lang in langs" :key="lang.name" :value="lang.name">
{{ `${lang.name} (${lang.lang})` }}
</option>
</select>
</div>
<div v-if="loading">正在處理圖像...</div>
<div v-else>
<img v-if="imageData" :src="imageData" alt="圖像" />
<div v-if="recognizedText">{{ recognizedText }}</div>
</div>
</div>
</template>
<script setup>
import { ref, onMounted } from 'vue';
import { createWorker } from 'tesseract.js';
const loading = ref(false);
const selectedLang = ref('chi_tra');
const imageData = ref(null);
const recognizedText = ref(null);
const langs = [ //是我自己組的,若需要測試別種語言要自己加上去
{
name: 'chi_tra',
lang: '繁體中文'
},
{
name: 'eng',
lang: '英文'
},
{
name: 'chi_sim',
lang: '簡體中文'
}
];
const processImage = async event => {
const file = event.target.files[0];
if (!file) return;
const imageURL = URL.createObjectURL(file);
loading.value = true;
imageData.value = null;
recognizedText.value = null;
let worker;
try {
worker = await createWorker(selectedLang.value, 1, {
logger: m => console.log(m)
});
const {
data: { text }
} = await worker.recognize(imageURL);
recognizedText.value = text;
imageData.value = imageURL;
} catch (error) {
console.error('Error processing image:', error);
} finally {
loading.value = false;
await worker.terminate();
}
};
</script>
<style lang="scss" scoped></style>
這樣就完成拉!不過這只是基本使用,上傳一些比較模糊照片或者特殊字體還是都有亂碼出現
延伸閱讀
如何提升文字辨識率? Tesseract documentation:Improving the quality of the output
Tesseract documentation:FAQ
OCR 是什麼?https://go.commeet.co/blog/%E6%95%B8%E4%BD%8D%E8%BD%89%E5%9E%8B/ocr/
那我們明天再見了~

