到目前為止,在我們第一篇介紹 LangChain 的文章中,已經為大家展示了如何利用 ConversationChain 快速建立一個具有基本記憶功能的對話機器人。但是,對於 LangChain 在記憶單元方面的全貌和核心概念,我們還沒有深入地探究過。今天,我們會專門深入這一主題,為大家帶來詳盡的說明。
首先,我們來聊聊「記憶能力」和「記憶單元」是什麼。簡單來說,這些概念就像我們人類大腦的運作方式。大腦不僅儲存了我們與外界的互動,還會在未來的互動中查閱這些資料,以做出更加明確和合適的反應。換句話說,記憶能力就是我們的能力,將過去的經驗儲存並在未來需要時做出合適的選擇;而記憶單元則像是一個儲藏室,裡面裝滿了我們生活中的點點滴滴。
以上的概念,在對話系統的記憶功能的實做上,我們很幸運的,LangChain 已經內建了一套全面而豐富的記憶模組。這些模組範圍廣泛,從最基礎的讀取和寫入功能到各種特定需求的高度客制記憶單元都一應俱全。例如,我們有最基本的「對話記憶體」(ConversationBufferMemory)用於儲存簡單的對話歷史;有「局部窗口對話記憶體」,它限制了儲存空間,只保存最近的對話;還有更高級的「對話實體記憶體」(ConversationEntityMemory),它不僅保存對話,還能分析和記錄對話中的實體和事件關係;以及更專門的「知識圖譜記憶體」(ConversationKGMemory),這可以用於儲存和查詢更複雜的知識結構。
所以,無論是什麼樣的記憶需求,LangChain 都為您提供了全面的解決方案。這樣一來,只要我們從基礎開始了解,未來深入這些複雜的概念就會變得相對容易。讓我們一起探索 LangChain 內部設計的記憶模組架構吧!
在深入了解 LangChain 的記憶單元實作細節之前,讓我們先探索在一個對話系統中,「記憶」到底是什麼。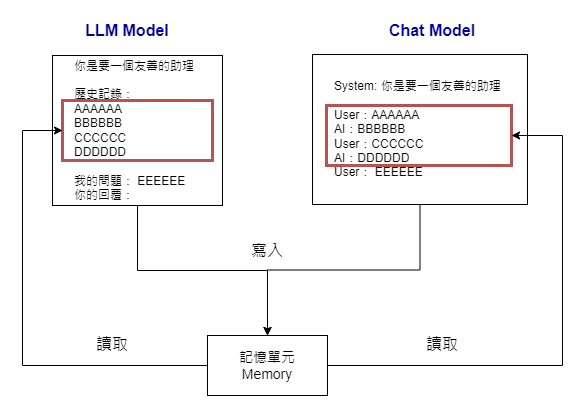
如果你是從這個系列開始就與我們一同探索的朋友,應該還記得我們最初是從 OpenAI 的 API 入手。在那裏,我們介紹了 OpenAI 的 Completions 和 ChatCompletions 端點。實際上,OpenAI 的 Completions 可以看作是 LangChain 的 LLM Model 的一個簡單形式,而 ChatCompletions 則類似於 LangChain 的 ChatModel。
這些模型的記憶功能運作原理大致如上圖所示。基本上,記憶單元的核心功能就是對對話歷史進行讀取和寫入。當我們建立一個提示功能時,我們會從記憶單元中讀取對話的歷史。每完成一輪對話後,我們也會將這些對話記錄更新到記憶單元中。
接下來,我們將進一步探討如何在 LLM 模型中實現這些記憶功能。
如果你想為 LLM(語言學習模型)加入記憶功能,這裡有一個簡單的範例。首先,建立一個記憶體實例,然後將它嵌入到 LLMChain 中,如下所示:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# 初始化 LLM 實例
llm = OpenAI(temperature=0)
# 建立一個 ConversationBufferMemory 實例來作為記憶體
memory = ConversationBufferMemory()
# 設置對話模板,並注意 "history" 部分用於存儲對話歷史
template = """你是一個友善的學習助理,你接下來會跟使用者來對話。
對話記錄:
{history}
使用者新訊息: {question}
你的回應:"""
# 從模板中生成對話提示
prompt = PromptTemplate.from_template(template)
# 初始化 LLMChain 並將記憶體與其連接
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
現在,我們可以用一個簡單的對話來測試這個組合
conversation({
'question': '你好'
})
-- 在這裡,你會看到模型的實際輸出以及對話記錄 ---
> Entering new LLMChain chain...
Prompt after formatting:
你是一個友善的學習助理,你接下來會跟使用者來對話。
對話記錄:
使用者新訊息: 你好
你的回應:
> Finished chain.
{'question': '你好', 'chat_history': '', 'text': ' 你好!很高興為您服務!有什麼可以為您做的嗎?'}
你會發現,由於這是新的對話,因此從 LLMChain 的除錯訊息中看到的對話歷史是空的。接著,如果我們與它再進行一次對話,對話歷史會被保存,這樣你可以看到模型是如何從先前的對話中取得我麽交談的背景資料:
conversation({
'question': '你可以做什麼?'
})
--- 實際的輸出 ---
> Entering new LLMChain chain...
Prompt after formatting:
你是一個友善的學習助理,你接下來會跟使用者來對話。
對話記錄:
Human: 你好
AI: 你好!很高興為您服務!有什麼可以為您做的嗎?
使用者新訊息: 你可以做什麼?
你的迴應:
> Finished chain.
{'question': '你可以做什麼?',
'chat_history': 'Human: 你好\nAI: 你好!很高興為您服務!有什麼可以為您做的嗎?',
'text': '\n我可以協助您學習新知識,提供您有關某個主題的資訊,並提供您有關某個主題的指導和支持。'}
**LangChain 記憶體的特殊設計:return_messages 參數
在繼續之前,讓我們先了解一下 return_messages 這個參數。這個參數控制記憶體實例返回的數據格式。預設情況下,它會返回一個包含對話歷史的字符串。但如果你將這個參數設為 True,則它會返回一個更結構化的消息格式,即 HumanMessage 和 AIMessage。首先是使用預設值時的情況:
# 使用預設的 return_messages 參數
memory_return_message_n = ConversationBufferMemory()
memory_return_message_n.chat_memory.add_user_message("你好!")
memory_return_message_n.chat_memory.add_ai_message("什麼事?")
# 這裡,輸出會以單純的字串的方式顯示
memory_return_message_n.load_memory_variables({})
--- 實際的輸出 ---
{'history': 'Human: 你好!\nAI: 什麼事?'}
而當我們設定 return_messages 參數後則如下:
# 設置 return_messages 參數後的範例
memory_return_message = ConversationBufferMemory(return_messages=True)
memory_return_message.chat_memory.add_user_message("你好!")
memory_return_message.chat_memory.add_ai_message("什麼事?")
# 這裡,輸出會以結構化的方式顯示
memory_return_message.load_memory_variables({})
--- 實際的輸出 ---
{'history': [HumanMessage(content='你好!', additional_kwargs={}, example=False),
AIMessage(content='什麼事?', additional_kwargs={}, example=False)]}
這個特性非常重要,因為它會在我們接下來要介紹如何為 Chat 模型加上記憶功能時發揮作用。
總結一下,LangChain 提供了多種靈活的選項,讓你可以依照需求來定制模型的記憶功能。從簡單的對話緩存到更複雜的結構,你都可以自由選擇。這樣不僅能使你的模型設計更靈活性,也能讓我們更方便依照使用者的需求做設計調整。
當你使用像是 LangChain 的 ChatModel 或 OpenAI 的 ChatCompletions 這種先進的聊天模型,一件需要注意的事是,這些模型的訊息(message)並非僅僅是一串簡單的文字(字串)。事實上,每一條訊息都是一個結構化的物件,可能還包括「角色資訊」(例如是人類或AI發送的訊息)。換句話說,每條訊息都會被封裝成特殊的結構,例如 LangChain 裏的 AIMessage 或 HumanMessage 物件。
return_messages=True 是關鍵?由於這種結構化的訊息存在,如果你希望在 LangChain 的聊天模型中實現「記憶功能」,就需要使用一個特定的設定:return_messages=True。這樣做的目的是確保當我們用特殊的記憶單元,如 ConversationBufferMemory,來查詢過往的對話紀錄時,它會返回這些結構化的訊息。換句話說,這確保了不只訊息內容會被儲存,還有與之相關的角色資訊也會完整地儲存和回傳。
以下是一個在 Python 中實際使用這種記憶功能的範例:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# 建立記憶體實例,開啟 return_messages 是為了將記憶體指定給 chat模型
# 而 memory_key則是可以讓我們客制我們取得對話記錄時用的 key 值
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 建立 chat 語言模型
llm_chat = ChatOpenAI()
# 提示設計
prompt_chat = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"你是一個友善的學習助理,你接下來會跟使用者來對話。"
),
# 這裏是一個讓記憶體資料填空的地方。
# 我們也要設定,使用chat_history 來取得對話記錄
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
conversation_chat = LLMChain(
llm=llm_chat,
prompt=prompt,
verbose=True,
memory=memory
)
在這段程式碼中,你會看到 return_messages=True 這個設定,確保了記憶單元可以回傳完整的結構化訊息,而不只是訊息內容。
下方則是我們幾個簡單的測試與結果:
conversation_chat({
'question': '老師好~'
})
--- 實際的輸出 ---
> Entering new LLMChain chain...
Prompt after formatting:
System: 你是一個友善的學習助理,你接下來會跟使用者來對話。
Human: 老師好~
> Finished chain.
{'question': '老師好~',
'chat_history': [HumanMessage(content='老師好~', additional_kwargs={}, example=False),
AIMessage(content='你好!我是您的學習助理,很高興能幫助您。有什麼我可以為您做的嗎?', additional_kwargs={}, example=False)],
'text': '你好!我是您的學習助理,很高興能幫助您。有什麼我可以為您做的嗎?'}
當我們有過一次對話後,來看接下來內部結構有什麼不同:
conversation_chat({
'question': '什麼東西的助理??'
})
--- 實際的輸出 ---
> Entering new LLMChain chain...
Prompt after formatting:
System: 你是一個友善的學習助理,你接下來會跟使用者來對話。
Human: 老師好~
AI: 你好!我是您的學習助理,很高興能幫助您。有什麼我可以為您做的嗎?
Human: 什麼東西的助理??
> Finished chain.
{'question': '什麼東西的助理??',
'chat_history': [HumanMessage(content='老師好~', additional_kwargs={}, example=False),
AIMessage(content='你好!我是您的學習助理,很高興能幫助您。有什麼我可以為您做的嗎?', additional_kwargs={}, example=False),
HumanMessage(content='什麼東西的助理??', additional_kwargs={}, example=False),
AIMessage(content='我是一個學習助理,可以幫助您在學習方面提供資訊、回答問題、提供指導和建議。您可以向我提問有關學業、課程、學習方法、研究等方面的問題,我會盡力為您提供幫助。如果您有其他需要,也歡迎告訴我,我會盡力協助您。', additional_kwargs={}, example=False)],
'text': '我是一個學習助理,可以幫助您在學習方面提供資訊、回答問題、提供指導和建議。您可以向我提問有關學業、課程、學習方法、研究等方面的問題,我會盡力為您提供幫助。如果您有其他需要,也歡迎告訴我,我會盡力協助您。'}
從這個測試中,我們可以看出,結構化的訊息(如 AIMessage 和 HumanMessage)確實被儲存和回傳了。這就解釋了為何在設定聊天模型的記憶功能時,return_messages=True 是一個關鍵的設定選項。
以上,我們在這篇文章概述了我們 LangChain 記憶單元的基礎使用方式。如果您對程式碼感到好奇,請參考這個連結:D25. LangChain 專案實做 - 記憶單元的探討(上).ipynb。
值得注意的是,LangChain 對記憶單元的設計遠不止於此。由於篇幅有限,我們將在下一篇文章中,詳細介紹其更深入的原理和進階使用方法。感謝您的閱讀,我們下次再見~


 iThome鐵人賽
iThome鐵人賽