在上一篇文章中,我們詳細示範了如何在 LLMChain 中使用 LLM 和 Chat 語言模型來加入記憶功能。我們也瞭解了對話系統訊息的儲存結構。今天,我們將進一步深入 LangChain 的記憶單元內部實做,並探討其進階使用方式,如何使用 VectorStoreRetrieverMemory 來使用向量資料庫做歷史記錄的儲存與檢索。
LangChain 的基本記憶體儲存結構即為 ChatMessageHistory。這是一個封裝了 HumanMessage 和 AIMessage 訊息的輕量級儲存單元。在大多數情況下,我們不直接使用它,除非我們想在 Chain 執行單元之外獨立設計對話功能。其基本的界面及使用方法如下:
from langchain.memory import ChatMessageHistory
# 建立 ChatMessageHistory 實例
history = ChatMessageHistory()
# 增加使用者訊息
history.add_user_message("你好!")
# 增加 AI 助理的訊息
history.add_ai_message("什麼事?")
history.messages
--- 實際的輸出 ---
[HumanMessage(content='你好!', additional_kwargs={}, example=False),
AIMessage(content='什麼事?', additional_kwargs={}, example=False)]
從上述例子可以看出,ChatMessageHistory 內部主要是存放了 HumanMessage 和 AIMessage 的物件清單。此外,這個資料結構也被用於如 ConversationBufferMemory 或 ConversationBufferWindowsMemory 這類的對話記憶體儲存。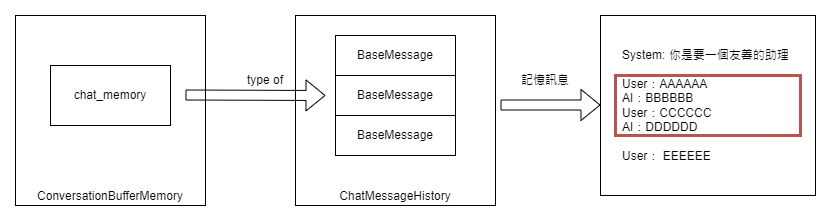
值得注意的是,AIMessage、HumanMessage 甚至 SystemMessage 都是 BaseMessage 的特殊例子。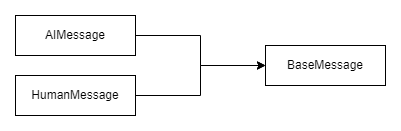
在深入探討 LangChain 的基本對話記憶體元素之後,我們再次回到了 LLMChain。你可能好奇,這樣的高層次元件是如何與 ConversationBufferMemory 這類的記憶體進行互動的。要回答這個問題,首先我們要了解記憶體單元的兩個核心界面。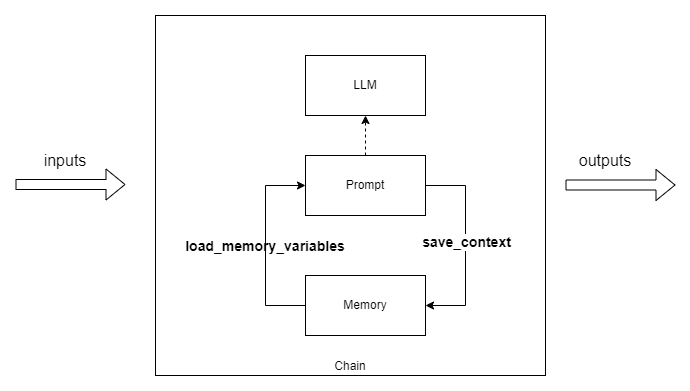
事實上,所有的記憶體類別都會支援兩個主要界面:save_context 和 load_memory_variables。其中,save_context 主要負責更新記憶體中的上下文資訊,而 load_memory_variables 則提供了一個取得記憶體內資料的途徑。下面是一個簡單的 ConversationBufferMemory 使用範例:
from langchain.memory import ConversationBufferMemory
# 建立 ConversationBufferMemroy 實例
memory_buffer = ConversationBufferMemory()
# 更新上下文資訊
memory_buffer.save_context({"input": "你好!"}, {"output": "什麼事?"})
memory_buffer.save_context({"input": "沒什麼事!"}, {"output": "你很無聊耶!"})
# 查詢記憶體中的資料
memory_buffer.load_memory_variables({})
--- 實際的輸出 ---
{'history': 'Human: 你好!\nAI: 什麼事?\nHuman: 沒什麼事!\nAI: 你很無聊耶!'}
從上述範例中,我們可以看到,我們使用了 save_context 兩次,也就表示進行了兩次的對話。而當我們使用 load_memory_variables 時,實際上也像是 LLMChain 內部在取得記憶體內容時的動作一樣。此外,你可能注意到 load_memory_variables 中有一個空的字典值(dictionary)參數,這其實是因為 ConversationBufferMemory 並不提供特定的查詢方式。而這個空的字典只是作為一個冗餘參數。接下來,在「使用 Vector Store 作為儲存後端的記憶單元」的部分,我們會詳細介紹這個參數如何用於特定資料的查詢。
讓我們探討 ConversationBufferWindowMemory 類別,直譯為「局部窗口對話記憶體」。這樣命名的原因在於,它的主要功能是限制在一個局部窗口內保存的對話資訊。由於 token 的運算資源有限且需消耗費用,甚至如果語言模型是我們自己架設的,同樣需要大量的運算資源,因此我們不能讓歷史對話資料無窮無盡地累積。
為了應對這個問題,我們可能會選擇一個直觀且簡單的解決方案:只保存最近的 k 條訊息。雖然這個策略可能聽起來有些粗糙,但這種「窗口」的方式在實際應用中常常是非常有效的。現在,我們來看一下如何限制儲存的訊息數量。在建立 ConversationBufferWindowMemory 的時候,要特別留意傳入的 k 值:# 建立 ConversationBufferWindowMemory 實例,這裏 k=1 代表僅儲存最近一條訊息
from langchain.memory import ConversationBufferWindowMemory
# 建立 ConversationBufferWindowMemory 實例, k=1 即限制一條訊息
memory_buffer_window = ConversationBufferWindowMemory(k=1)
# 更新上下文資訊
memory_buffer_window.save_context({"input": "你好!"}, {"output": "什麼事?"})
memory_buffer_window.save_context({"input": "沒什麼事!"}, {"output": "你很無聊耶!"})
# 取得記憶體內儲存的資訊
memory_buffer_window.load_memory_variables({})
--- 實際的輸出 ---
{'history': 'Human: 沒什麼事!\nAI: 你很無聊耶!'}
從上述範例中可以看到,只需設定 k = 1,無論進行多少次對話,記憶單元僅保存最後的對話資料。
最後,我想要跟大家分享一個稍微進階的記憶類別——使用 Vector Store 作為儲存後端的記憶單元。
還記得我們之前在 [D24] LangChain 專題實做 - 「例句學習」教材生成 這篇文章中,談到使用 TransformChain 來取得向量資料庫內,和使用者問題相似的資料嗎?實際上,我們也可以參考 VectorStoreRetrieverMemory 這樣的方法,設計我們的 LLMChain 來擷取背景資料。
值得特別提及的是,VectorStoreRetrieverMemory 不僅能夠從向量資料庫中檢索相似度資料,它還會在對話過程中將我們的對話記錄保存到向量資料中。請參考下方的範例及測試案例。
# 下方是建立向量資料庫的部分
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import VectorStoreRetrieverMemory
db_chroma = Chroma(embedding_function=OpenAIEmbeddings())
retriever = db_chroma.as_retriever(search_kwargs=dict(k=1))
memory_vs = VectorStoreRetrieverMemory(retriever=retriever, return_messages=True)
# 這裏是模擬我們已經有三個對話記錄
memory_vs.save_context({"Human": "我最喜歡的食物是披薩"}, {"AI": "這樣很棒!"})
memory_vs.save_context({"Human": "我最喜歡的運動是游泳"}, {"AI": "很高興你跟我說分享你的嗜好。"})
memory_vs.save_context({"Human": "我不喜歡欺騙"}, {"AI": "瞭解"})
# 使用 load_memory_varialbes 取得使用者問題相似度的歷史資料
print(memory_vs.load_memory_variables({"prompt": "我該看什麼運動節目?"}))
--- 以下是檢索得到的內容 ---
{'history': 'Human: 我最喜歡的運動是游泳\nAI: 很高興你跟我說分享你的嗜好。'}
接下來的程式碼展示了如何設計提示訊息和建立 ConversationChain:
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0) # Can be any valid LLM
_DEFAULT_TEMPLATE = """
你是一個友善的對話機器人,下面歷史記錄是我們曾經的對話。
Human 是我,AI 是你。請根據歷史記錄中的資訊來回覆我的新問題。
歷史記錄:
{history}
Human:{input}
AI:
"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_memory_vs = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory_vs,
verbose=True,
output_key='AI'
)
然後,透過以下的測試,大家可以更直觀地理解它的實際運作方式:
conversation_with_memory_vs.predict(input="你好,我的名字是 Ted。你今天如何?")
--- 實際的回應 ---
> Entering new ConversationChain chain...
Prompt after formatting:
你是一個友善的對話機器人,下面歷史記錄是我們曾經的對話。
Human 是我,AI 是你。請根據歷史記錄中的資訊來回覆我的新問題。
歷史記錄:
Human: 我最喜歡的食物是披薩
AI: 這樣很棒!
Human:你好,我的名字是 Ted。你今天如何?
AI:
> Finished chain.
你好 Ted,我今天很好,謝謝你問。你今天有什麼新鮮事嗎?
從第一句打招呼可以看出,雖然我們的記憶單元找到了與主題不太相關的最相似對話記錄,但我們的語言模型聰明地選擇忽略了它。接著,我們嘗試詢問一些之前問過的問題:
conversation_with_memory_vs.predict(input="你知道我喜歡什麼食物嗎?")
--- 實際的回應 ---
> Entering new ConversationChain chain...
Prompt after formatting:
你是一個友善的對話機器人,下面歷史記錄是我們曾經的對話。
Human 是我,AI 是你。請根據歷史記錄中的資訊來回覆我的新問題。
歷史記錄:
Human: 我最喜歡的食物是披薩
AI: 這樣很棒!
Human:你知道我喜歡什麼食物嗎?
AI:
> Finished chain.
是的,你最喜歡的食物是披薩。
關於喜歡的食物的問題,回答得相當不錯,不是嗎?我們注意到模型成功檢索到了我們之前提及喜歡披薩的對話,而語言模型也巧妙地利用這段背景資訊給出了恰當的回答。那麼,關於喜歡的運動呢?
conversation_with_memory_vs.predict(input="我最喜歡什麼運動?")
--- 實際的回應 ---
> Entering new ConversationChain chain...
Prompt after formatting:
你是一個友善的對話機器人,下面歷史記錄是我們曾經的對話。
Human 是我,AI 是你。請根據歷史記錄中的資訊來回覆我的新問題。
歷史記錄:
Human: 我最喜歡的運動是游泳
AI: 很高興你跟我說分享你的嗜好。
Human:我最喜歡什麼運動?
AI:
> Finished chain.
答案完全正確。接下來,是否我們新的對話也已被記錄了呢?讓我們透過下面的測試來看看:
conversation_with_memory_vs.predict(input="我叫什麼名字?")
--- 實際的回應 ---
> Entering new ConversationChain chain...
Prompt after formatting:
你是一個友善的對話機器人,下面歷史記錄是我們曾經的對話。
Human 是我,AI 是你。請根據歷史記錄中的資訊來回覆我的新問題。
歷史記錄:
input: 你好,我的名字是 Ted。你今天如何?
AI: 你好 Ted,我今天很好,謝謝你問。你今天有什麼新鮮事嗎?
Human:我叫什麼名字?
AI:
> Finished chain.
你叫 Ted,對吧?
經過上述的實際測試,我們可以明確看到 ConversationChain 加上 VectorStoreRetrieverMemory 的強大功能。不僅可以方便地儲存和檢索之前的對話記錄,還可以大幅度減少在格式化提示訊息時背景資料的數量負擔。
總之,這次我們對 LangChain 的記憶單元進行了全面的介紹。儘管 LangChain 提供的記憶模組不止於此,但只要大家掌握了上述的核心觀念,相信對於其他記憶模組的學習和應用會更加得心應手。
想要深入研究程式碼的朋友,可以參考這裡的連結: D26. LangChain 專案實做 - 記憶單元的探討(下).ipynb
感謝大家的閱讀,我們下次見~


 iThome鐵人賽
iThome鐵人賽