今天來筆記一下 Jobs、CronJobs、 DaemonSet 各是怎樣的 Objects。
有些服務是要一直運行不中斷,但有些工作可能只需要執行一次、或是要定期執行,這時就可以使用 Job or CronJob 這兩種 Controller 來建立 Pods。
先來看 Job 的 spec -
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
這個 Job 會建立一個 Pod,pi 這個 container 會算圓周率的值,計算到小數點後 2000 位並印出。執行完這個工作就會結束這個 Pod。
其中 restartPolicy 在 Job template 只能設定 Never 或是 OnFailure。也就是從不重啟、失敗後才重啟,但不像 Pod 可以設定一直重啟 (Always)
backoffLimit 是指如果這個任務嘗試執行 4 次還是失敗的話,則 Job 被標記為失敗。預設會是 6 次。
再來 Job 也能夠指定要運行多個 Pod,可以用 completions 這個 field 來計算任務被完成幾次。預設會是 1 次。
apiVersion: batch/v1
kind: Job
metadata:
name: random-error-job-nopara
spec:
completions: 3
# parallelism: 1
template:
spec:
containers:
- name: random-error
image: kodekloud/random-error
restartPolicy: Never
例如這個範例使用的 image 會得到隨機性的錯誤,而 completions 設成 3 則是會建 3 個 Pods 來完成這個任務。另外還有一個參數是 parallelism ,預設會是 1。代表同時只會有一個 Pod 在跑。也就是說 Pod 會一直建立直到完成三次為止。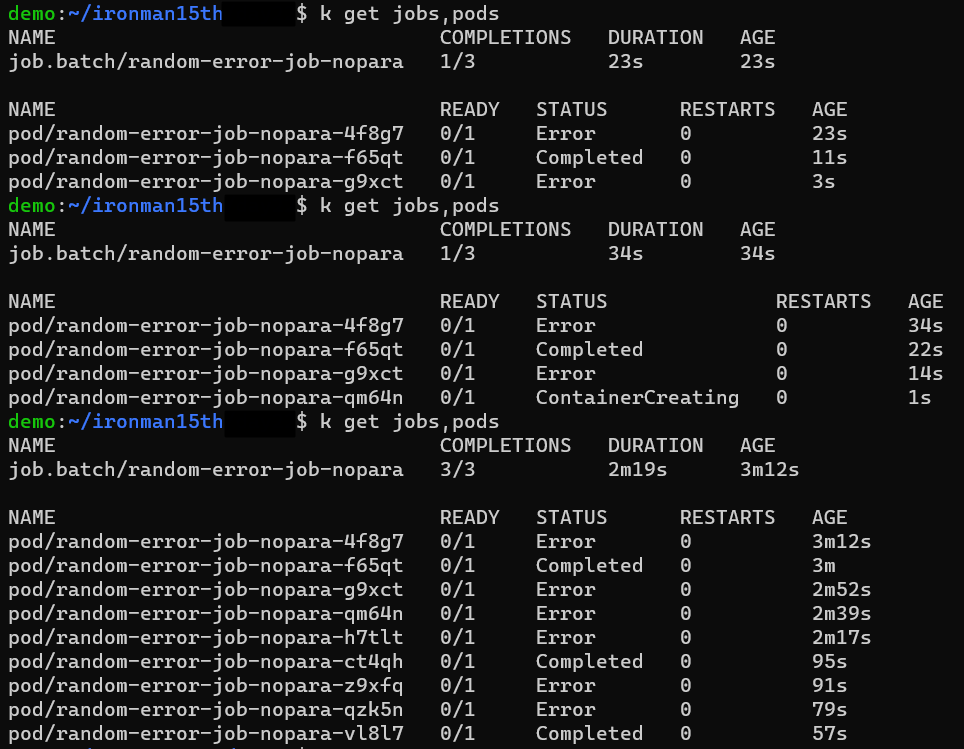
如果將 parallelism 設成 2,則一次會跑 2 個 Pods。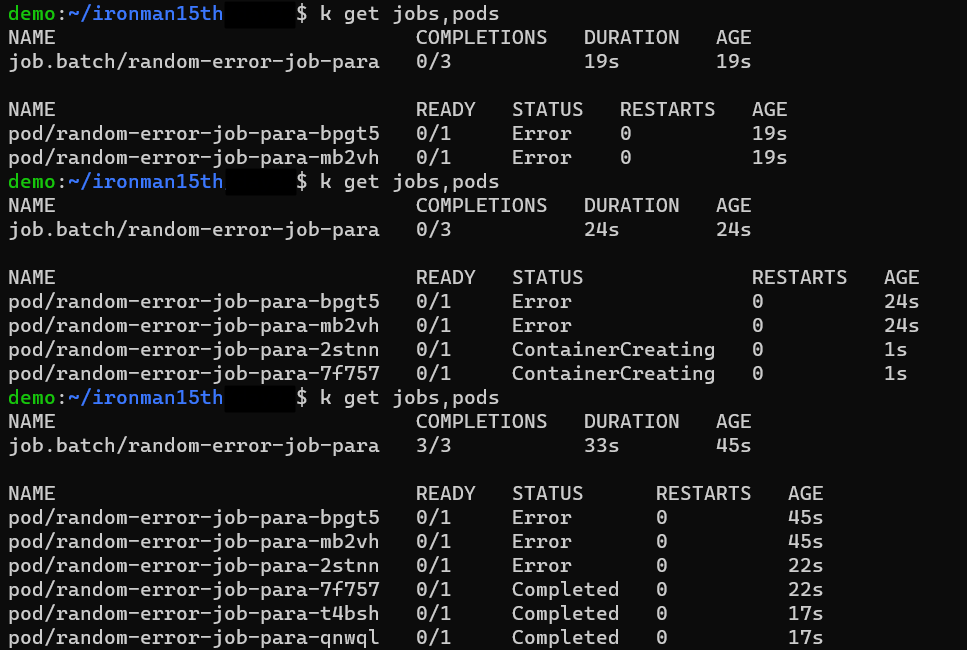
CronJob 則與 linux 的 CronJob 一樣,可以設置要定期執行的工作。
CronJob 的執行會透過 Job,然後再產生要工作的 Pod。因此 spec 上有 jobTemplate 與 template 需要設置 -
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
schedule 是必要參數。寫法跟 cronjob 相同 -
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │
# │ │ │ │ │
# * * * * * <command to execute>
這個 CronJob 設定每分鐘會執行一次,可以看到每過一分鐘會有一個 job 被建立,底下會控制 1 個 Pod 來執行任務 -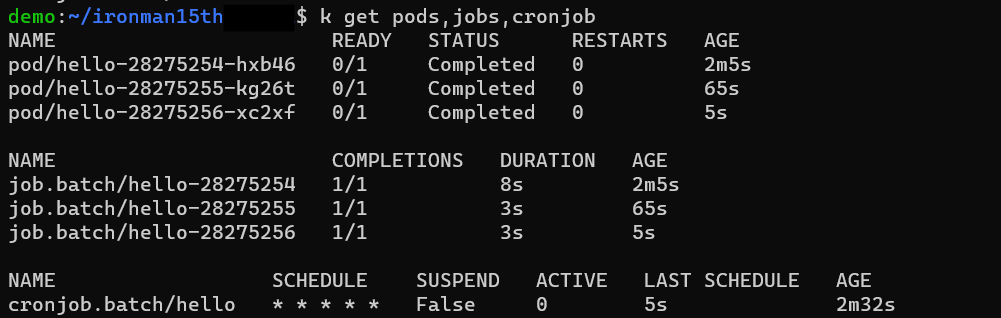
不過這時會有個問題,執行過的 Job 以及 Pod 會被自動移除嗎? CronJob spec 中還有個參數是 .spec.successfulJobsHistoryLimit & .spec.failedJobsHistoryLimit ,分別代表要 keep 多少個執行成功的 Job 以及失敗的 Job,預設會是 3 & 1。看下圖可以發現 hello-28275255 & hello-28275256 這兩個 Job 後來被清掉了,Cluster 中只會有 3 個完成的 Jobs。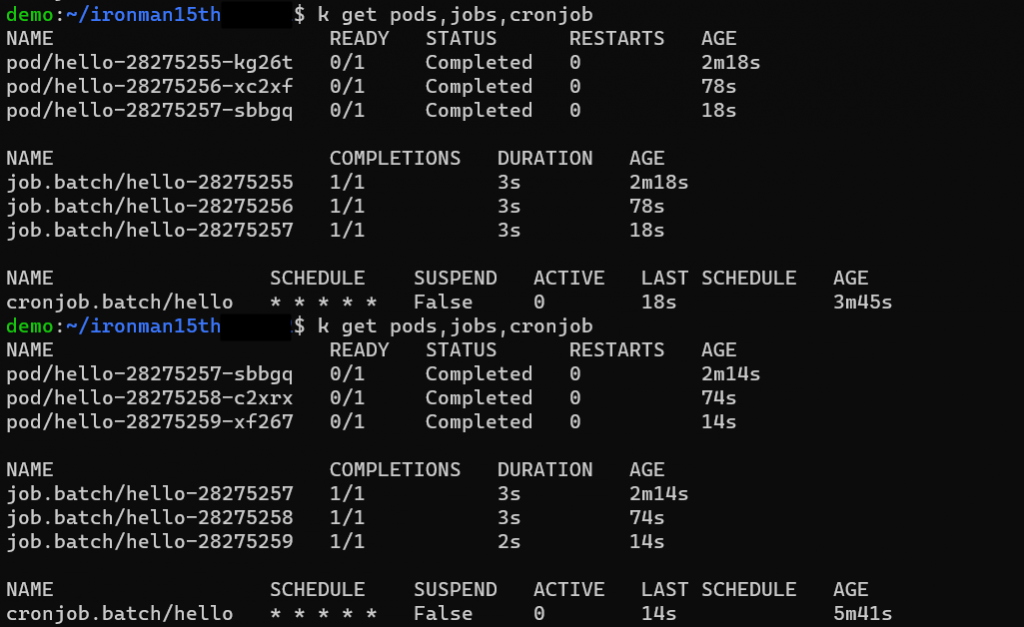
再回到 Job 的執行,有些工作如果只要執行一次,可能就不會用 CronJob 來控制。但要怎麼清除 Job? Kubernetes 有提供一個 TTL 機制,由 TTL-after-finished Controller 來清理結束的 Job。
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 10
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
這邊ttlSecondsAfterFinished: 10代表當 Job 完成任務後 10 秒會被清除。如果設成 0 則是 Job 執行完畢就被清除。而前面的例子沒有設置這個參數則 Job 完成後不會被 TTL controller 清除。建議如果要使用 Job 還是要設置 ttlSecondsAfterFinished ,避免太多的 Completed Pods 影響 Cluster performance。
DaemonSet 相似於 ReplicaSet,但 DaemonSet 的特性是會在 Cluster 中的每個 Node (也可以控制 Taints & Tolerations 來讓特定 Node 跑 daemon) 都跑一個 Pod。如果新的 Node 加入這個 Cluster,就會跑一個 DaemonSet 的 Pod 在上面;如果 Node 被移除,則這個 DaemonSet 控制的 Pod 也會被移除。
使用場景的話就是會需要每個 Node 都進行某個應用程式的時候,例如在每個 Node 上跑一個 Monitoring daemon。
例如透過 Prometheus 來監測 Cluster,每個 Node 會跑一個 Node Exporter -
Spec 寫法與 ReplicaSets 類似 -
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
DaemonSet 的更新策略有兩種:
Reference
https://kubernetes.io/docs/concepts/workloads/controllers/job/
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/job-v1/
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/cron-job-v1/
https://en.wikipedia.org/wiki/Cron


 iThome鐵人賽
iThome鐵人賽