我們這次實戰所使用的資料集依然是先前介紹過的MNIST手寫數字資料集,可以從Pytorch提供的API直接下載。
1. 利用MLP架構
- 這邊我們使用單純的nn.linear架構建立一個Autoencoder模型:
# Define the Autoencoder model
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(1 * 28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 1 * 28 * 28),
nn.Tanh() # Output values between -1 and 1 (suitable for images)
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# Initialize the Autoencoder model
model = Autoencoder()
- 整個模型架構如下圖所示:
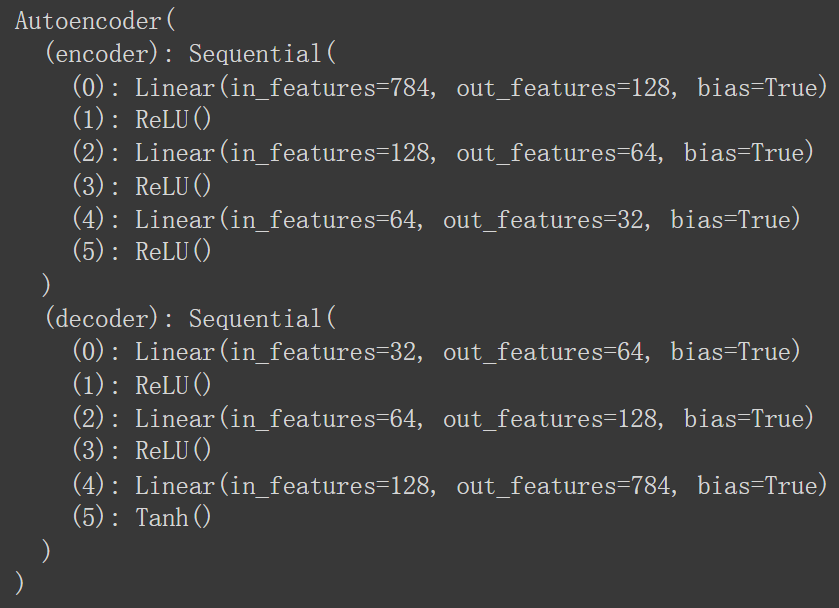
- 可以看到在Encoder的部分是從高維度逐步學習到低維度特徵,而Decoder則相反,是從低維度特徵學習到高維度特徵,符合Autoencoder的設計概念。
- 接著,建立好模型之後,我們就可以開始訓練了:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch.optim as optim
# Hyperparameters
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# Data preprocessing and loading
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5), (0.5))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# Define the Autoencoder model
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(1 * 28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 1 * 28 * 28),
nn.Tanh() # Output values between -1 and 1 (suitable for images)
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# Initialize the Autoencoder model
model = Autoencoder()
# Loss and optimizer
criterion = nn.MSELoss() # Mean Squared Error (MSE) loss
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, _) in enumerate(train_loader):
# Flatten the images
images = images.view(-1, 1 * 28 * 28)
# Forward pass
outputs = model(images)
loss = criterion(outputs, images)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
print('Training finished.')
- 最後,我們可以利用下方的程式碼輸出原始圖片以及經過模型還原後的圖片:
# Test the autoencoder
model.eval()
with torch.no_grad():
for images, _ in train_loader:
outputs = model(images.view(-1, 1 * 28 * 28)).view(-1, 1,28,28)
break
# Display original and reconstructed images
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
for i in range(5):
axes[0, i].imshow(images[i].cpu().numpy().transpose(1, 2, 0))
axes[0, i].set_title('Original')
axes[0, i].axis('off')
axes[1, i].imshow(outputs[i].cpu().numpy().transpose(1, 2, 0))
axes[1, i].set_title('Reconstructed')
axes[1, i].axis('off')
plt.show()
- 運行結果應該會如下圖一樣,訓練好的模型已經能很好的根據輸入圖片還原出一張極度相似的圖片出來:
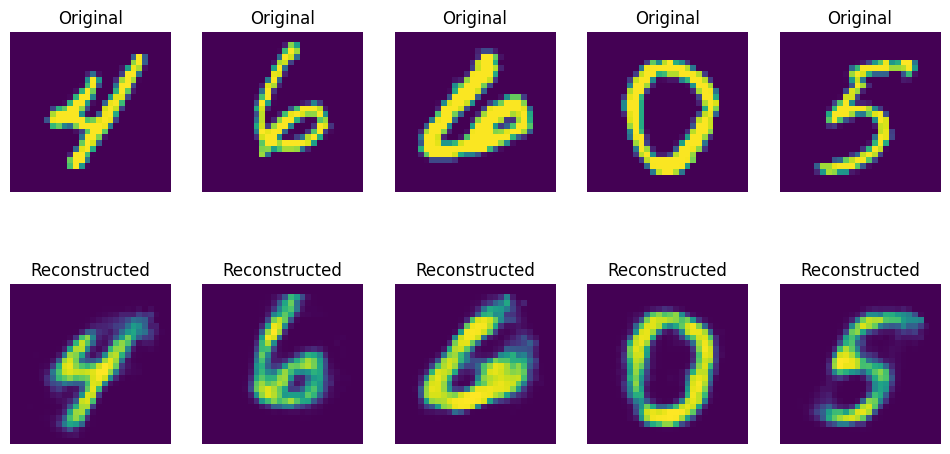
- 註:因為有經過歸一化處理,所以圖片不是資料集中黑白色的樣子。
2. 利用CNN架構
- 除了全部都使用線性層以外,當然也可以通過捲積層來實現Autoencoder架構,我們使用下方程式碼就可以建構這樣的模型:
# Define the Autoencoder model with Conv2d layers and a bottleneck (nn.Linear)
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU()
)
self.bottleneck = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 4 * 4, 256), # Bottleneck layer with reduced dimensionality
nn.ReLU(),
nn.Linear(256, 64 * 4 * 4), # Bottleneck layer with reduced dimensionality
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2, padding=1, output_padding=0),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=2, output_padding=1),
nn.Tanh() # Output values between -1 and 1 (suitable for images)
)
def forward(self, x):
x = self.encoder(x)
x = self.bottleneck(x)
x = self.decoder(x.view(x.size(0), 64, 4, 4)) # Reshape for decoding
return x
# Initialize the Autoencoder model
model = Autoencoder()
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# Hyperparameters
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# Data preprocessing and loading
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5), (0.5))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# Define the Autoencoder model with Conv2d layers and a bottleneck (nn.Linear)
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU()
)
self.bottleneck = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 4 * 4, 256), # Bottleneck layer with reduced dimensionality
nn.ReLU(),
nn.Linear(256, 64 * 4 * 4), # Bottleneck layer with reduced dimensionality
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2, padding=1, output_padding=0),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=2, output_padding=1),
nn.Tanh() # Output values between -1 and 1 (suitable for images)
)
def forward(self, x):
x = self.encoder(x)
x = self.bottleneck(x)
x = self.decoder(x.view(x.size(0), 64, 4, 4)) # Reshape for decoding
return x
# Initialize the Autoencoder model
model = Autoencoder()
# Loss and optimizer
criterion = nn.MSELoss() # Mean Squared Error (MSE) loss
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, _) in enumerate(train_loader):
# Forward pass
outputs = model(images)
loss = criterion(outputs, images)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
print('Training finished.')
- 並且也可以通過輸出結果視覺化的觀察一下模型訓練的好壞:
# Test the autoencoder
model.eval()
with torch.no_grad():
for images, _ in train_loader:
print(images.shape)
outputs = model(images).view(-1, 1,28,28)
break
# Display original and reconstructed images
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
for i in range(5):
axes[0, i].imshow(images[i].cpu().numpy().transpose(1, 2, 0))
axes[0, i].set_title('Original')
axes[0, i].axis('off')
axes[1, i].imshow(outputs[i].cpu().numpy().transpose(1, 2, 0))
axes[1, i].set_title('Reconstructed')
axes[1, i].axis('off')
plt.show()
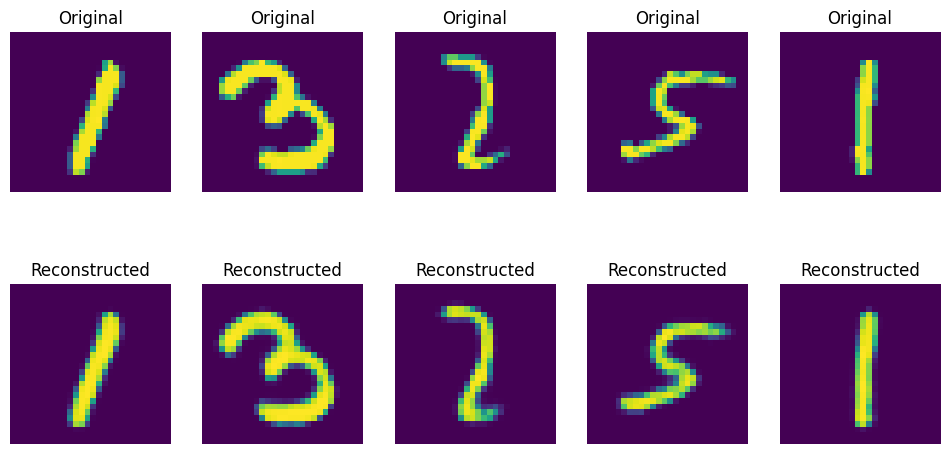
- 輸出結果如下圖所示;



 iThome鐵人賽
iThome鐵人賽