2023 iThome 鐵人賽
分享至
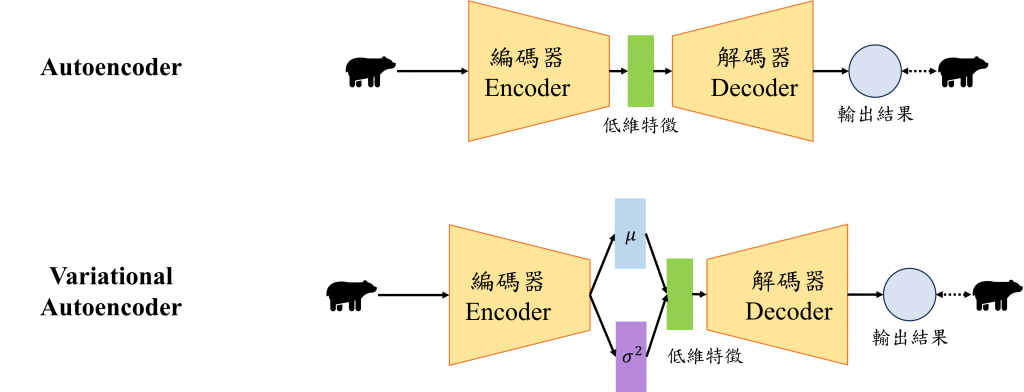
機率分布與抽樣在AI領域當中是很重要的概念,雖然沒有特別提出來說,可是很多概念都被我們當作前提假設隱藏在模型的設計背後,今天我們就利用VAE來看看機率分布與抽樣究竟會出現在什麼樣的地方。
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽