
Python 的 Pandas 是一個強大的資料分析工具包,讓你能夠輕鬆地處理和分析結構化數據。以下是一個基本的 Pandas 教學:
如果你還沒有安裝 Pandas,你可以通過 pip 來安裝它:
pip install pandas
在你的 Python 程式中,你需要先導入 Pandas:
import pandas as pd
s = pd.Series([1, 3, 5, 7, 9])
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
df = pd.DataFrame(data)
總結來說,Series 是一維的,用於存儲單一列的數據,而 DataFrame 是二維的,用於存儲多列數據,它們都支持大量的操作和數據處理功能,是 Python 中處理結構化數據的強大工具。
每個字典代表一行,字典的鍵是列名,值是數據值。
data = [
{'姓名': '小明', '年紀': 24, '工作': '工程師'},
{'姓名': '小華', '年紀': 30, '工作': '設計師'},
{'姓名': '小天', '年紀': 28, '工作': '老師'}
]
df = pd.DataFrame(data)
df
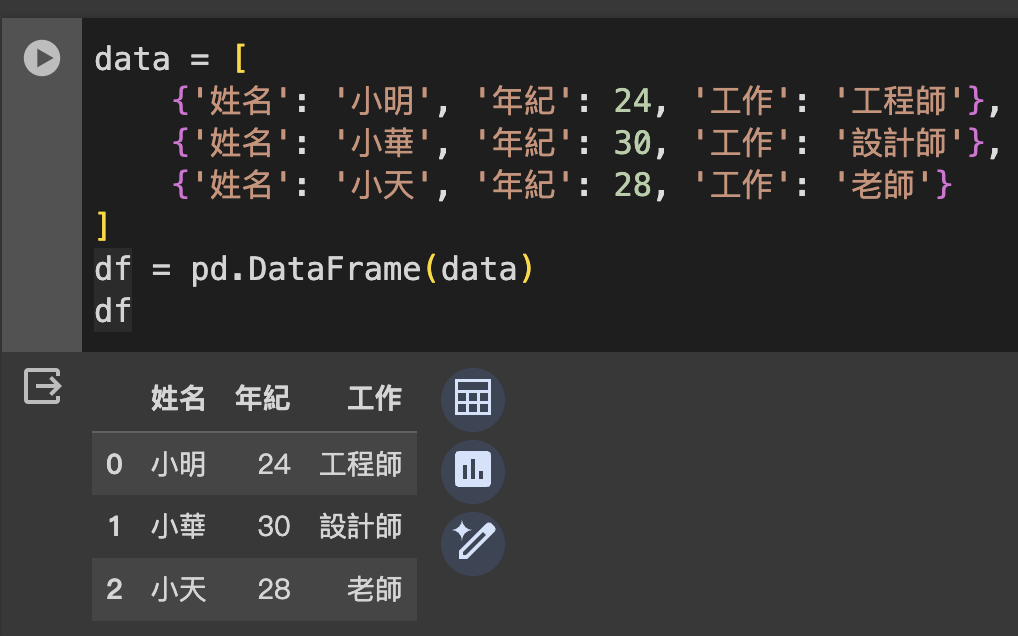
字典的鍵是列名,值是列的數據,以列表或Series形式。
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [24, 30, 28],
'job': ['Engineer', 'Designer', 'Teacher']
}
df = pd.DataFrame(data)
df
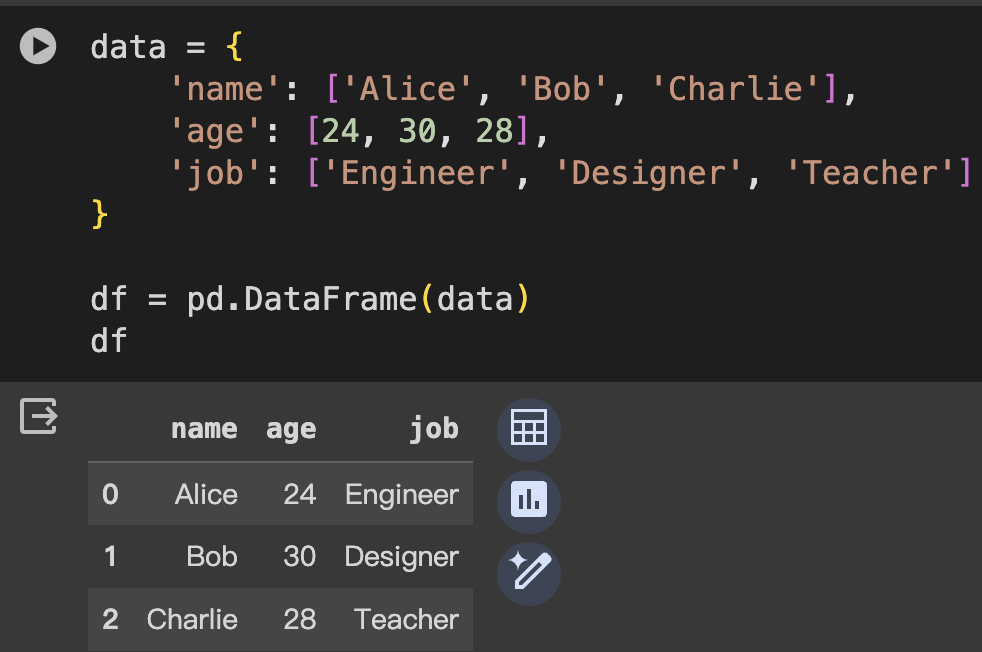
直接通過傳遞一個列表的列表來創建,並且可以指定列名。
rows = [
['Alice', 24, 'Engineer'],
['Bob', 30, 'Designer'],
['Charlie', 28, 'Teacher']
]
col_names = ['name', 'age', 'job']
df = pd.DataFrame(rows, columns=col_names)
df
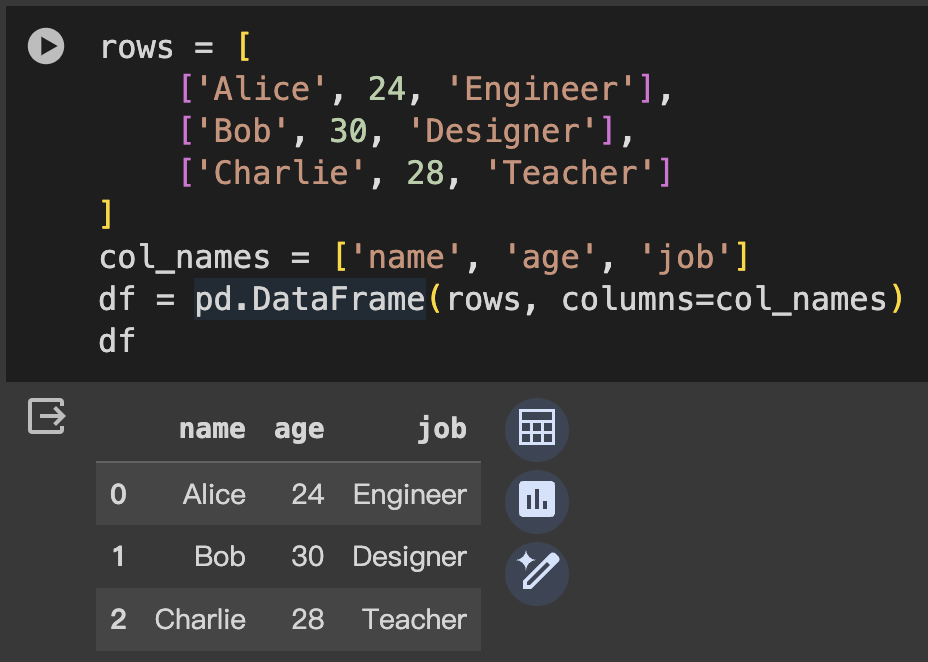
每個 Series 代表一列。
s1 = pd.Series([1, 2, 3])
s2 = pd.Series(['Alice', 'Bob', 'Charlie'])
s3 = pd.Series([24, 30, 28])
df = pd.DataFrame({'id': s1, 'name': s2, 'age': s3})
df
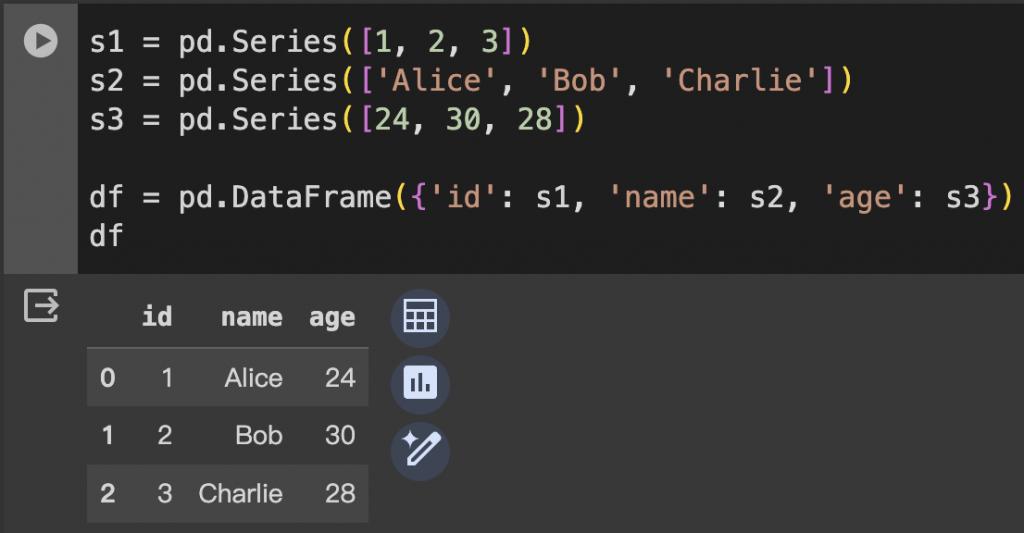
這些範例涵蓋了從不同數據結構創建 DataFrame 的常見情況。根據你的具體需求,你可以選擇最適合你數據格式的方法。
在使用 Pandas 的 DataFrame 時,了解其數據型態(data types)和常見屬性是非常重要的。以下是一些基本的型態和屬性介紹:
DataFrame 中的每一列(Series)可以有不同的數據型態。常見的數據型態包括:
int64: 整數型float64: 浮點數型object: 文本或混合型(通常是字符串)bool: 布林型(True 或 False)datetime64: 日期時間型timedelta[ns]: 表示兩個時間之間的差category: 分類型,用於表示有限的、通常是固定不變的可能值集合你可以用 dtypes 屬性查看 DataFrame 的每列數據型態:
df.dtypes
下面是一個展示如何使用這些屬性的例子:
# 創建一個簡單的 DataFrame
data = {
'Integers': [1, 2, 3],
'Floats': [0.1, 0.2, 0.3],
'Strings': ['apple', 'banana', 'cherry']
}
df = pd.DataFrame(data)
# 使用屬性
print("Data Types:\n", df.dtypes)
print("Shape:", df.shape)
print("Index:", df.index)
print("Columns:", df.columns)
print("Info:", df.info())
print("Describe:", df.describe())
print("Head:", df.head())
print("Size:", df.size)
print("Is Empty:", df.empty)
"""
Data Types:
Integers int64
Floats float64
Strings object
dtype: object
Shape: (3, 3)
Index: RangeIndex(start=0, stop=3, step=1)
Columns: Index(['Integers', 'Floats', 'Strings'], dtype='object')
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Integers 3 non-null int64
1 Floats 3 non-null float64
2 Strings 3 non-null object
dtypes: float64(1), int64(1), object(1)
memory usage: 200.0+ bytes
Info: None
Describe: Integers Floats
count 3.0 3.00
mean 2.0 0.20
std 1.0 0.10
min 1.0 0.10
25% 1.5 0.15
50% 2.0 0.20
75% 2.5 0.25
max 3.0 0.30
Head: Integers Floats Strings
0 1 0.1 apple
1 2 0.2 banana
2 3 0.3 cherry
Size: 9
Is Empty: False
"""
透過熟悉這些型態和屬性,你可以更有效地操作和分析 DataFrame 中的數據。

在 Pandas 中,取得 DataFrame 中的特定欄位(列)數據可以使用多種方法。以下是一些常見的方法:
直接使用列名作為索引可以取得該列的數據。
# 假設 df 是一個 DataFrame
column_data = df['ColumnName']
. 操作符如果列名是一個有效的 Python 變量名,也可以使用 . 來訪問列。
column_data = df.ColumnName
loc 和 ilocloc[]: 基於列的欄位名稱取得列。iloc[]: 基於列的整數位置(index)來取得列。data = [
{'姓名': '小明', '年紀': 24, '工作': '工程師'},
{'姓名': '小華', '年紀': 30, '工作': '設計師'},
{'姓名': '小天', '年紀': 28, '工作': '老師'}
]
df = pd.DataFrame(data)
"""
姓名 年紀 工作
0 小明 24 工程師
1 小華 30 設計師
2 小天 28 老師
"""
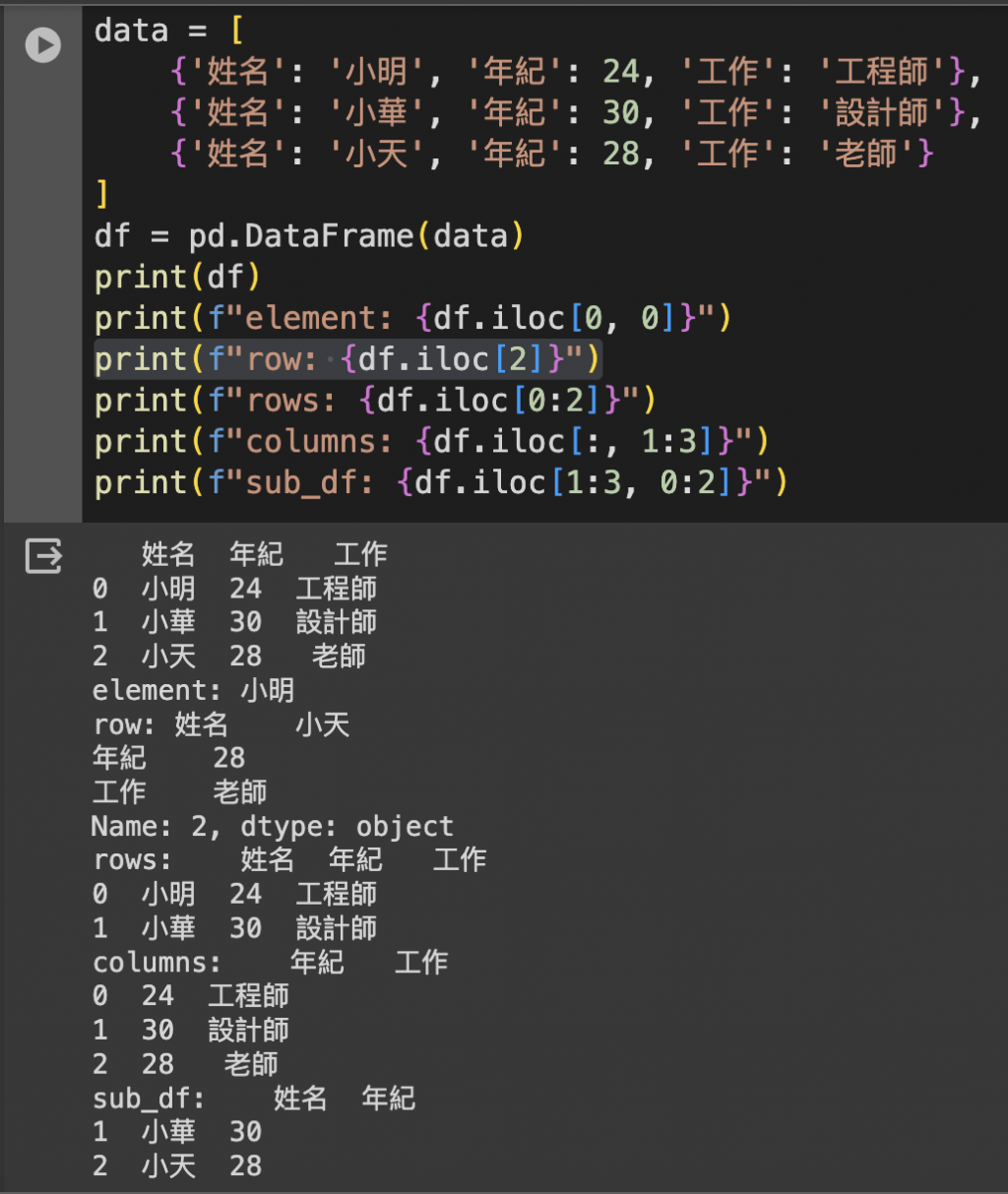
ilociloc 是基於整數位置的索引,允許通過給定的位置(行數和列數)來訪問 DataFrame。
DataFrame.iloc[行位置, 列位置]
# 單個元素
element = df.iloc[0, 0] # 第一行第一列的元素
# element: 小明
# 某一行
row = df.iloc[2] # 第三行的所有列
# 姓名 小天
# 年紀 28
# 工作 老師
# 某幾行
rows = df.iloc[0:2] # 前兩行的所有列
# 姓名 年紀 工作
# 0 小明 24 工程師
# 1 小華 30 設計師
# 某幾列
columns = df.iloc[:, 1:3] # 所有行的第二和第三列
# 0 24 工程師
# 1 30 設計師
# 2 28 老師
# 特定行列
sub_df = df.iloc[1:3, 0:2] # 第二到第三行和第一到第二列的子集
# 姓名 年紀
#1 小華 30
#2 小天 28
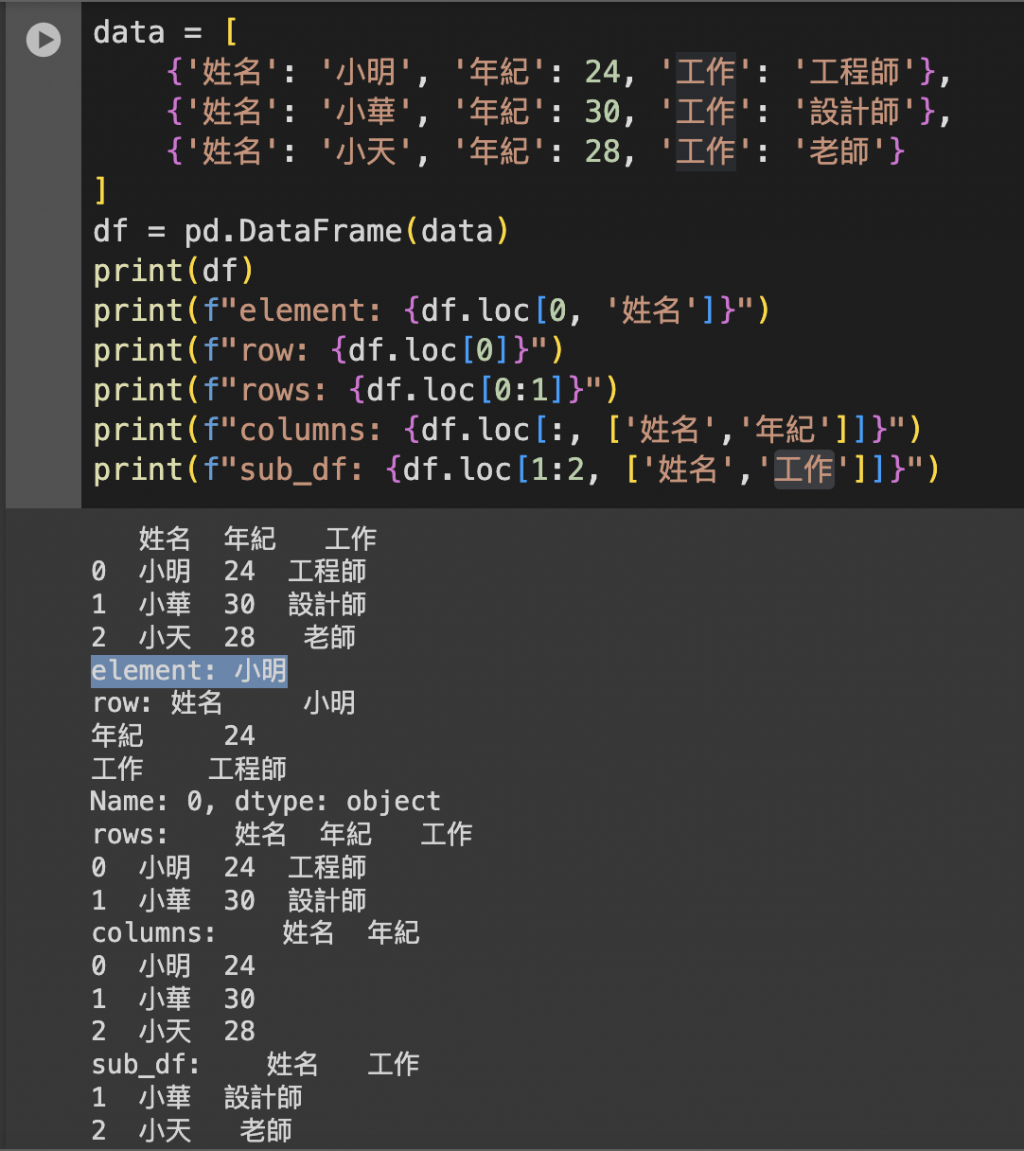
locloc 是基於標籤名稱的索引,允許通過行標籤和列名稱來訪問 DataFrame。
DataFrame.loc[行標籤, 列標籤]
pythonCopy code
# 單個元素
element = df.loc[0, '姓名'] # 標籤為 0 的行和名為 '姓名' 的列
# element: 小明
# 某一行
row = df.loc[0] # 標籤為 0 的行
# row:
# 姓名 小明
# 年紀 24
# 工作 工程師
Name: 0, dtype: object
# 某幾行
rows = df.loc[0:1] # 0 到 1 的行
#rows:
# 姓名 年紀 工作
#0 小明 24 工程師
#1 小華 30 設計師
# 某幾列
columns = df.loc[:, ['姓名', '年紀']] # 所有行的 '姓名' 和 '年紀'
#columns:
# 姓名 年紀
#0 小明 24
#1 小華 30
#2 小天 28
# 特定行列
sub_df = df.loc[1:2, '姓名':'工作'] # 特定範圍的標籤行列
#sub_df:
# 姓名 工作
#1 小華 設計師
#2 小天 老師
loc 和 iloc 的時注意:iloc 在進行切片時不包含結束位置,而 loc 包含結束位置。loc 特別有用。loc 可以與布林條件配合使用,選擇符合特定條件的行列。iloc 或 loc 通常更高效。但對於較大的區域或者整個行列的操作,使用條件選擇或直接列名可能更好。理解 iloc 和 loc 的差異和適用情境,可以幫助你更加高效和準確地訪問和操作 DataFrame 中的數據。
增加 DataFrame 中的數據可以通過多種方式進行,包括增加列(欄位)和增加行。以下是一些常見方法:
直接賦值:如果列不存在,這將創建一個新列。
df['new_column'] = [value1, value2, value3, ...]
使用 .assign():這個方法會返回一個新的 DataFrame,不改變原來的 DataFrame。
df = df.assign(new_column=[value1, value2, value3, ...])
.append():添加一行或者另一個 DataFrame 的多行。這會返回一個新的 DataFrame,不改變原來的 DataFrame。new_row = {'column1': value1, 'column2': value2, ...}
df = df.append(new_row, ignore_index=True)
如果添加的是另一個 DataFrame 的多行,可以直接將其作為 .append() 的參數。
pd.concat():合併兩個 DataFrame。這也是增加多行數據的有效方法。new_df = pd.DataFrame(...) # 新的 DataFrame
df = pd.concat([df, new_df], ignore_index=True)
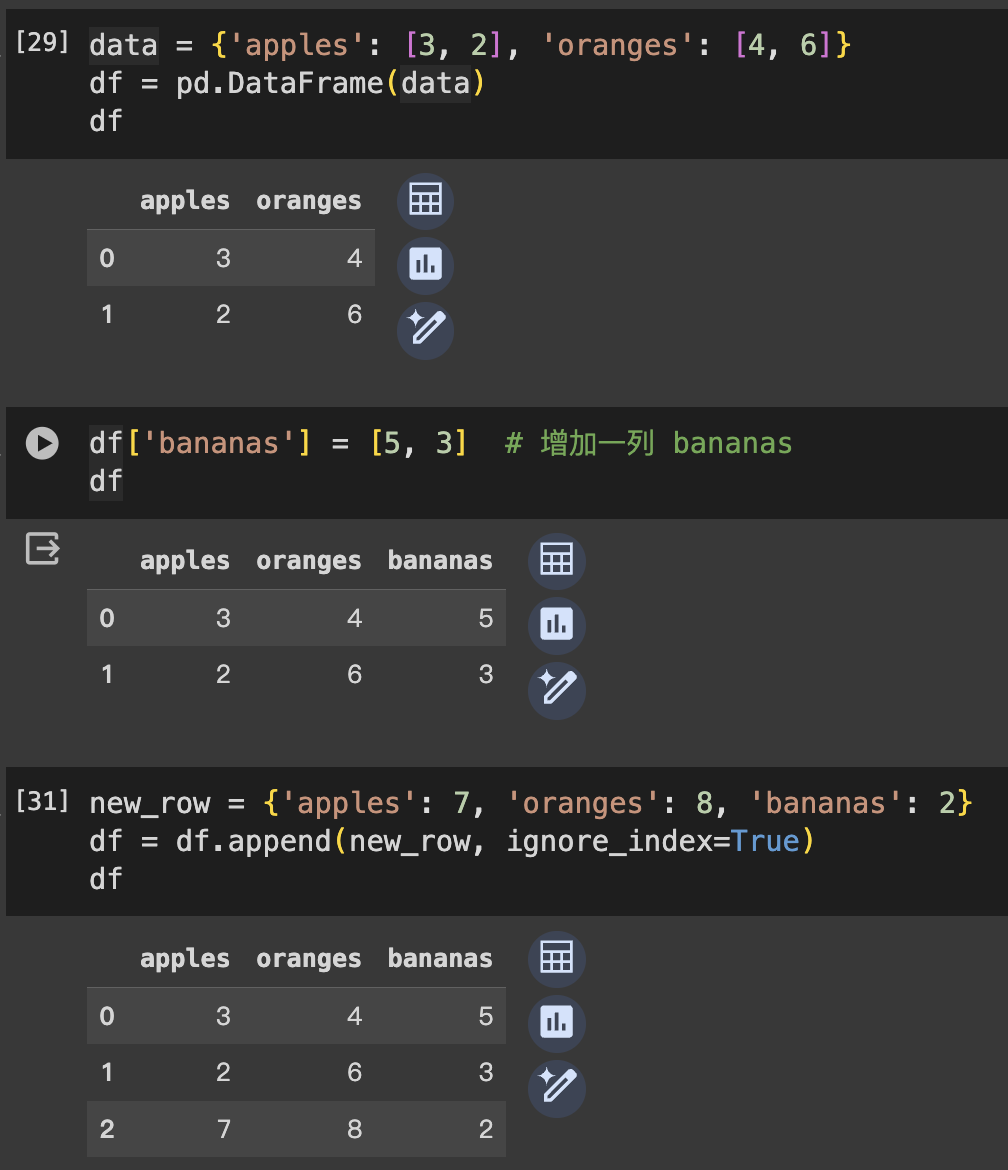
假設我們有以下的 DataFrame,代表一些水果的庫存:
data = {'apples': [3, 2], 'oranges': [4, 6]}
df = pd.DataFrame(data)
df['bananas'] = [5, 3] # 增加一列 bananas
print(df)
new_row = {'apples': 7, 'oranges': 8, 'bananas': 2}
df = df.append(new_row, ignore_index=True)
print(df)
使用這些方法,你可以輕鬆地根據需要擴展 DataFrame。记得在實際操作中,根據具體情況選擇最合適的方法。
資料清洗是數據分析中的一個重要步驟,它涉及到修正或刪除錯誤、不完整、不相關或不準確的數據。在大多數情況下,原始數據並不完美,需要經過一系列的處理才能用於分析或建模。以下是一些常見的資料清洗步驟:
重複的數據會導致分析結果的偏差。
# 去除重複數據
df = df.drop_duplicates()
缺失值可以用多種方式處理:
# 刪除含有缺失值的行
df = df.dropna()
# 刪除含有缺失值的列,
# 設置 axis 參數為 1 或 'columns' 可以刪除含有缺失值的列。
df = df.dropna(axis=1)
# 或者
df = df.dropna(axis='columns')
# 只刪除全部為 NaN 的行或列
df_cleaned = df.dropna(how='all')
# 刪除非缺失值少於 2 個的行
df_cleaned = df.dropna(thresh=2)
可選參數
dropna() 還提供了一些可選參數,以便更靈活地處理缺失值:
how: 'any'(默認)表示只要有缺失值就刪除,'all' 表示當所有值都是缺失值時才刪除。
thresh: 設置一個閾值,只有非缺失值的數量小於這個數時才刪除。
subset: 在一個行或列的子集上應用這些規則。
# 使用固定值填充
df = df.fillna(value)
# 使用平均值填充
df = df.fillna(df.mean())
# 使用中位數填充
df = df.fillna(df.median())
# 使用眾數填充
df = df.fillna(df.mode().iloc[0])
# 向前填充(使用前一個非缺失值填充)
df = df.fillna(method='ffill')
# 向後填充(使用後一個非缺失值填充)
df = df.fillna(method='bfill')
# 對特定列使用不同的填充值或方法。
df['column_name'] = df['column_name'].fillna(specific_value)
# 根據自定義函數或映射關係來填充缺失值。
df = df.apply(lambda x: x.fillna(x.mean()) if x.dtype.kind in 'biufc' else x.fillna('missing'))
範例:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': [1, np.nan, 3],
'B': [4, 5, np.nan],
'C': [np.nan, np.nan, np.nan]})
#使用固定值填充
df_filled = df.fillna(0)
#使用各列的平均值填充
df_filled = df.fillna(df.mean())
#向前填充
df_filled = df.fillna(method='ffill')
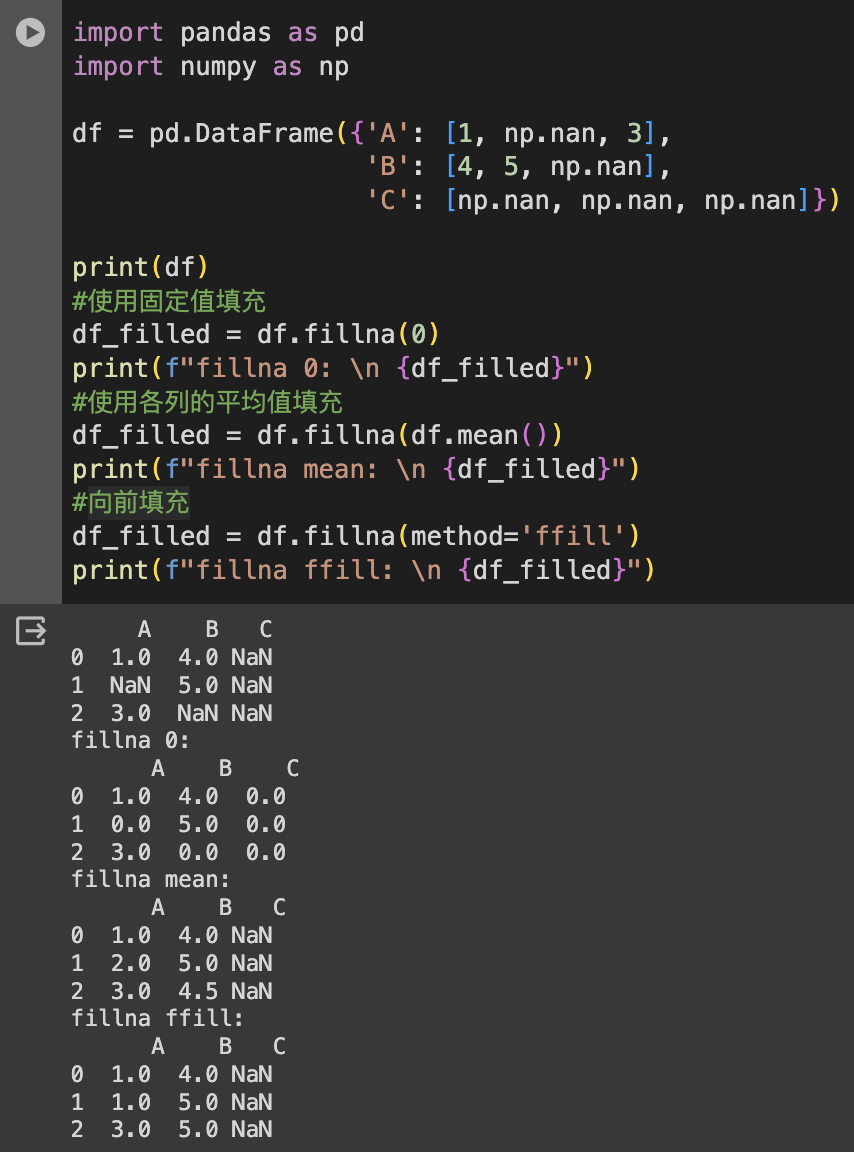
確保每列數據的類型正確。例如,將數字被錯誤地讀取為字符串,或將日期讀取為字符串等。
# 1. 轉換為字符串,使用 astype(str) 可將列轉換為字符串類型。
df['column'] = df['column'].astype(str)
# 2. 轉換為數值,使用 pd.to_numeric() 可將列轉換為數值型。
df['column'] = pd.to_numeric(df['column'], errors='coerce')
# errors='coerce' 會將無法轉換的值設為 NaN。
# 3. 轉換為整數,使用 astype(int) 或 astype('int64') 可將列轉換為整數型。
df['column'] = df['column'].astype(int)
# 4. 轉換為浮點數,使用 astype(float) 可將列轉換為浮點型。
df['column'] = df['column'].astype(float)
# 5. 轉換為日期時間,使用 pd.to_datetime() 可將列轉換為日期時間型。
df['column'] = pd.to_datetime(df['column'])
# 6. 轉換為類別型,使用 astype('category') 可將列轉換為類別型,適用於有限且重複的字符串。
df['column'] = df['column'].astype('category')
範例:
df = pd.DataFrame({'A': ['1', '2', '3'],
'B': ['1.1', '2.2', '3.3'],
'C': ['2021-01-01', '2021-01-02', '2021-01-03'],
'D': ['apple', 'banana', 'cherry']})
df['A'] = df['A'].astype(int) # 字符串轉整數
df['B'] = df['B'].astype(float) # 字符串轉浮點數
df['C'] = pd.to_datetime(df['C']) # 字符串轉日期
df['D'] = df['D'].astype('category') # 字符串轉類別型
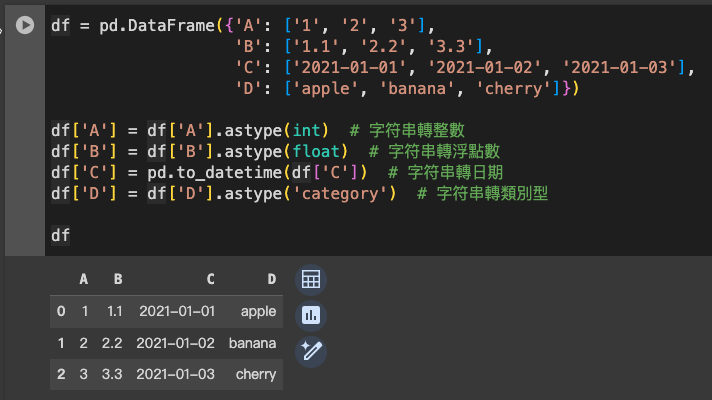
通過這些方法,你可以根據分析需求對 DataFrame 中的數據類型進行轉換,以確保數據的準確性和適用性。
修正明顯的數據錯誤,比如負的年齡、錯誤的郵政編碼等。
# 1. 替換值,使用 replace() 函數可以替換 DataFrame 中的特定值。
df['column'] = df['column'].replace(錯誤值, 正確值)
# 2. 條件賦值,使用條件表達式對特定條件下的值進行修正。
df.loc[df['column'] > 閾值, 'column'] = 新值
# 3. 使用函數修正,對列應用自定義函數來修正錯誤的數據。
df['column'] = df['column'].apply(lambda x: 函數(x))
# 4. 正則表達式,對字符串類型的數據,可以使用正則表達式來修正。
df['column'] = df['column'].str.replace(正則表達式, 新值, regex=True)
# 5. 使用其他列的數據修正,基於同一行的其他列的數據來修正某列的錯誤值。
df['column'] = df.apply(lambda row: 函數(row), axis=1)
範例:
df = pd.DataFrame({'Age': [29, -1, 0, 25, 120],
'Salary': ['10000$', '9000$', '8000$', '7000$', '6000$'],
'Name': ['Alice', 'Bob', '', 'Charlie', 'David']})
# 修正年齡
df.loc[df['Age'] < 0, 'Age'] = df['Age'].median()
df.loc[df['Age'] > 100, 'Age'] = df['Age'].median()
# 修正薪水格式
df['Salary'] = df['Salary'].str.replace('$', '').astype(int)
# 修正空名字
df['Name'] = df['Name'].replace('', 'Unknown')
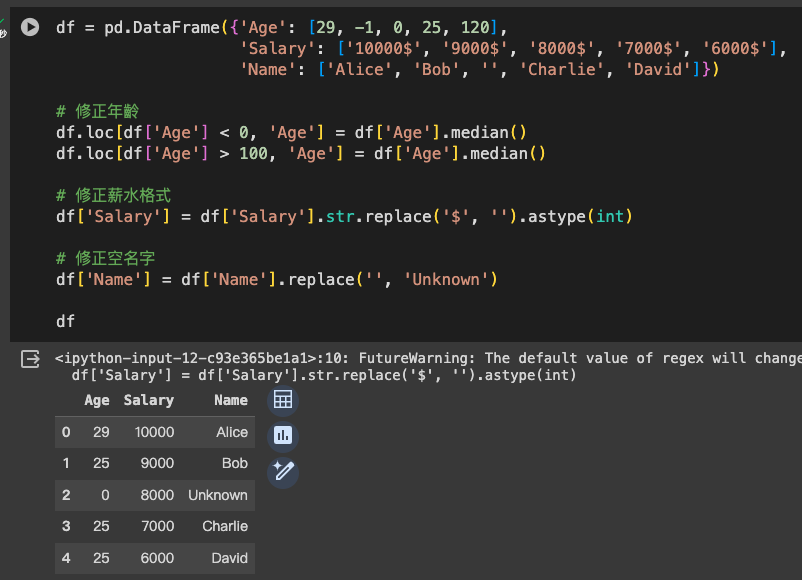
透過這些方法,你可以有效地修正 DataFrame 中的錯誤數據,提高數據質量,為後續的分析工作打下堅實的基礎。
在 Pandas 中,資料合併是將不同的數據集根據某些規則合併在一起。這類似於 SQL 或其他數據庫語言中的 join 操作。Pandas 提供了多種合併數據的方法,包括:
concat()pd.concat() 用於沿一個軸將多個對象堆疊在一起。它主要用於合併具有相同列的數據框架,或者相同行的情況。
pd.concat([df1, df2, ...], axis=0, join='outer')
objs: 一個序列或映射,包含你想要合併的 pandas 對象。axis: {0/'index', 1/'columns'}, 預設為 0。沿著哪個軸進行合併。join: {'inner', 'outer'}, 預設為 'outer'。如何處理除連接軸以外的軸上的索引。merge()merge() 類似於 SQL 中的 JOIN 操作,它可以讓你沿一個或多個鍵合併兩個數據框架。
pd.merge(left, right, how='inner', on=None)
left: 一個 DataFrame。right: 另一個 DataFrame。on: 用於連接的列名。必須在左右 DataFrame 對象中找到。how: {‘left’, ‘right’, ‘outer’, ‘inner’}, 預設為 'inner'。決定了合併的方式。join()join() 是在索引上合併。它是 merge() 的一個方便的方法,用於在列上合併,但通過索引來合併。
df1.join(df2)
join() 會將另一個 DataFrame 的列加入到一個 DataFrame 中,主要是基於索引。假設我們有兩個 DataFrame:df1 和 df2。
# 創建兩個 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
df2 = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
# concat
result1 = pd.concat([df1, df2], axis=1) # 沿著列合併
# merge
result2 = pd.merge(df1, df2, left_index=True, right_index=True, how='inner') # 基於索引進行內連接
# join
result3 = df1.join(df2) # df1 作為主DataFrame,將 df2 合併進來
print(result1)
print(result2)
print(result3)
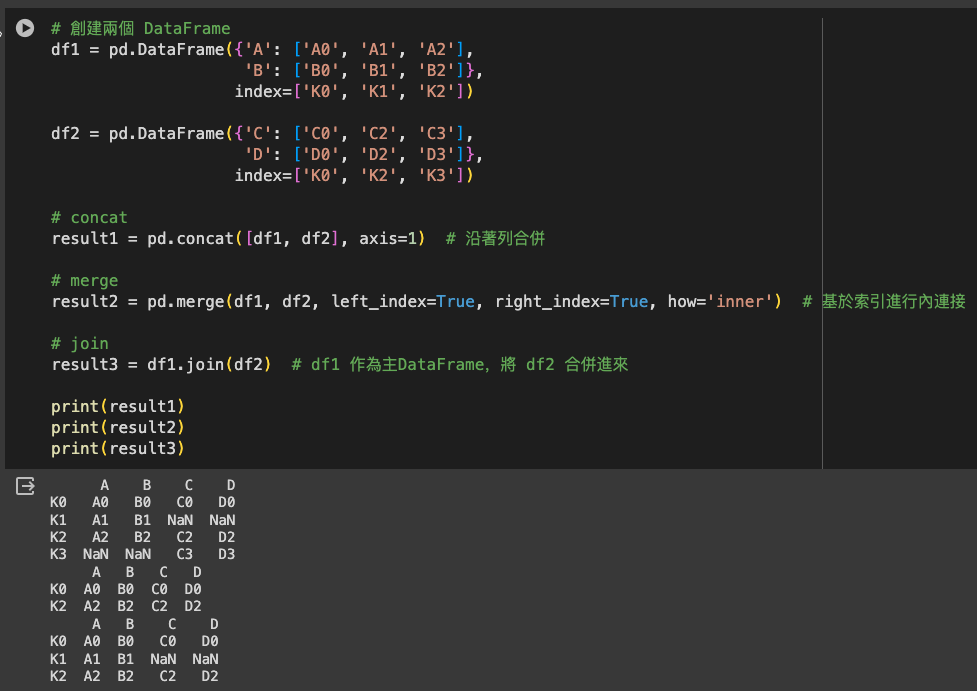
通過了解這些方法的不同用途和特點,你可以根據具體需求選擇最適合的資料合併方式。
在 Pandas 中,數據讀取是一個基本且常用的操作,用於將各種格式的數據文件讀入為 DataFrame。Pandas 支持多種數據源和文件格式,包括 CSV、Excel、SQL 數據庫等。以下是一些最常用的數據讀取方法:
CSV (Comma-Separated Values) 是一種常見的文件格式,用於存儲表格數據。
pd.read_csv(filepath_or_buffer, sep=',', ...)
filepath_or_buffer: 文件的路徑或類似的對象。sep: 字段分隔符號,默認為 ','。Excel 文件是辦公自動化中常見的數據存儲格式。
pd.read_excel(io, sheet_name=0, ...)
io: Excel 文件的路徑或文件對象。sheet_name: 要讀取的工作表名稱或索引,預設為第一個工作表。從 SQL 數據庫中讀取數據需要一個有效的 SQL 查詢和一個數據庫連接。
pd.read_sql(sql, con, ...)
sql: SQL 查詢字符串或SQLAlchemy Selectable。con: 數據庫連接對象。JSON (JavaScript Object Notation) 是一種輕量級的數據交換格式。
pd.read_json(path_or_buf, ...)
path_or_buf: JSON 文件的路徑或類似的對象。假設你有一個名為 "data.csv" 的 CSV 文件,以下是如何讀取它:
import pandas as pd
# 讀取 CSV 文件
df = pd.read_csv('data.csv')
# 現在 df 是一個 DataFrame 對象,包含了 CSV 文件中的數據
當讀取數據時,根據文件的特點和數據的結構,你可能需要設置額外的參數,如指定分隔符號、設定無數據時的填充值、選擇特定的列等。
掌握這些基本的數據讀取方法,可以幫助你靈活地從不同的數據源導入數據,為進一步的數據處理和分析打下基礎。
在 Pandas 中,DataFrame 提供了方便的方法直接使用 Matplotlib 庫繪制圖表,例如線圖、直方圖、散點圖等。這使得在探索性數據分析階段快速繪製圖形變得相當簡單。
plot() 方法Pandas 中的 .plot() 方法是基於 Matplotlib 開發的,它提供了多種參數來自定義圖表。
plot() 是一個通用的繪圖函數,用於創建各種類型的圖表,如線圖、柱狀圖、面積圖、散點圖等。kind 參數,可以改變圖表類型。例如,kind='line' 用於線圖,kind='bar' 用於柱狀圖。plot() 提供了豐富的參數用於自定義圖表,例如設置標題、軸標籤、顏色、大小等。以下是一些常用的 .plot() 參數及其介紹:
kind: 字符串,指定圖表的類型。常見的值包括 'line'(線圖)、'bar'(柱狀圖)、'barh'(橫向柱狀圖)、'hist'(直方圖)、'box'(箱形圖)、'kde' 或 'density'(核密度估計)、'area'(面積圖)、'pie'(餅圖)、'scatter'(散點圖)等。x, y: 用於指定作為 x 軸和 y 軸的列名。對於某些圖表類型(如散點圖)是必要的。figsize: 元組,指定圖表的大小,格式為 (寬度, 高度)。use_index: 布林值,默認為 True。決定是否使用 DataFrame 的索引作為 x 軸。title: 字符串,圖表的標題。grid: 布林值,指定是否顯示網格線。legend: 布林值,指定是否顯示圖例。style: 字符串或字符串列表,定義線條的風格(僅對線圖有效)。stacked: 布林值,對於柱狀圖和面積圖,決定是否堆疊數據。
subplots: 布林值,如果設為 True,則每列數據將畫在不同的子圖上。
layout: 元組,指定子圖的排列方式,格式為 (行數, 列數)。
sharex, sharey: 布林值,決定是否共享 x 軸或 y 軸。
colormap: 用於定義圖表顏色的 Colormap 對象或顏色映射名稱。
color: 指定線條或柱狀的顏色。
fontsize: 數字,指定軸標籤的字體大小。
用法:
df.plot(x='x_column', y='y_column', kind='line')
kind: 圖的類型,默认为 'line'。可以是 'line', 'bar', 'barh', 'hist', 'box', 'kde', 'area', 'pie', 'scatter', 'hexbin' 等。x, y: 分别表示横轴和纵轴的列名。最基本的 .plot() 使用,無需額外參數,默認創建線圖。
import pandas as pd
import numpy as np
# 創建示例數據
df = pd.DataFrame(np.random.randn(10, 2), columns=['A', 'B'])
# 繪製線圖
df.plot()
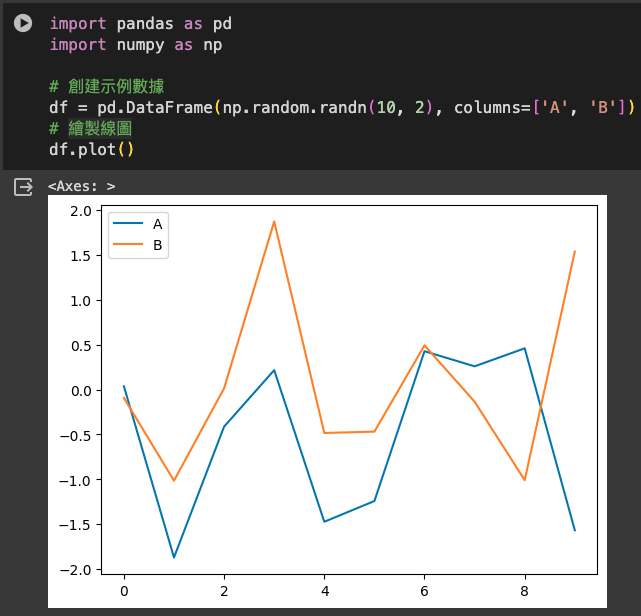
使用 kind 參數創建散點圖,並添加標題和軸標籤。
# 繪製散點圖
df.plot(x='A', y='B', kind='scatter', title='Scatter Plot', xlabel='Column A', ylabel='Column B')
x, y: 指定 x 軸和 y 軸的列。kind='scatter': 指定圖表類型為散點圖。title: 圖表的標題。xlabel, ylabel: x 軸和 y 軸的標籤。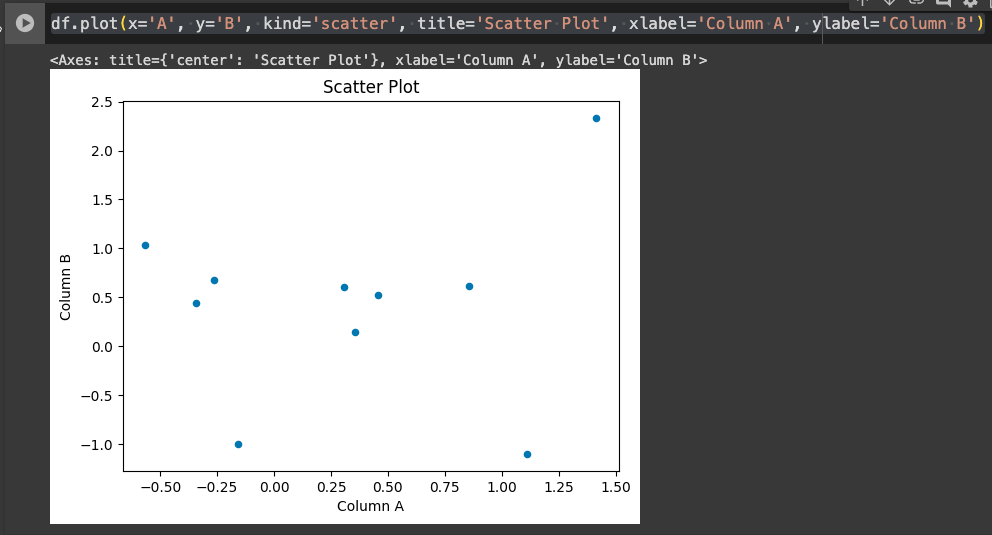
進階使用,創建帶有多個定制選項的柱狀圖。
# 增加一列作為示例
df['C'] = np.random.randn(10)
# 繪製柱狀圖
df.plot(kind='bar', stacked=True, color=['red', 'blue', 'green'], legend=True, title='Bar Chart')
kind='bar': 指定圖表類型為柱狀圖。stacked=True: 指定柱狀圖為堆疊式。color: 指定每列的顏色。legend: 是否顯示圖例。title: 圖表的標題。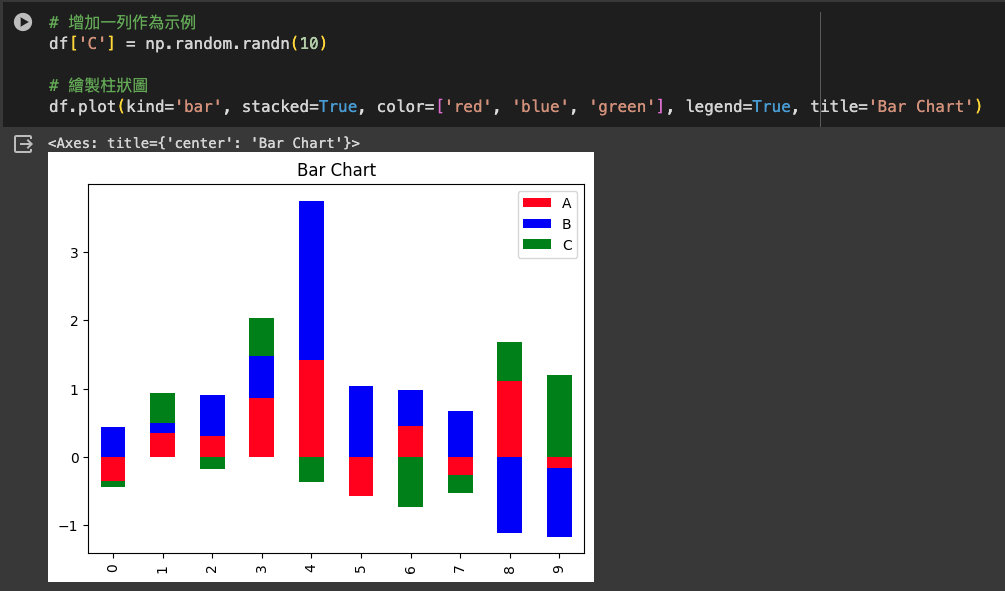
通過這些範例,你可以看到 .plot() 方法的多樣性和靈活性。根據你的數據和需求,可以進行多種自定義設置,創建各式各樣的圖表。
hist() 直方圖hist() 是專門用於繪製直方圖的函數。直方圖用於展示數據的分布情況,尤其是單個變量的分布。
hist() 會自動將數據分組(通常稱為「桶」或「bin」),並計算每個分組中的觀察次數。
雖然 plot() 也可以通過設置 kind='hist' 來繪製直方圖,但 hist() 提供了更專門化的選項,如自動分桶、密度估計等。
適用於需要快速理解單個變量的分佈特性時。
用法:
df['column'].hist(bins=10)
bins: 直方圖的條形數量,即分組數量。import pandas as pd
import numpy as np
# 創建示例數據
df = pd.DataFrame(np.random.randn(10, 1), columns=['A'])
df['A'].plot(kind='hist') # 繪製直方圖
df['A'].hist(bins=10) # 直接繪製直方圖,指定桶數為 10
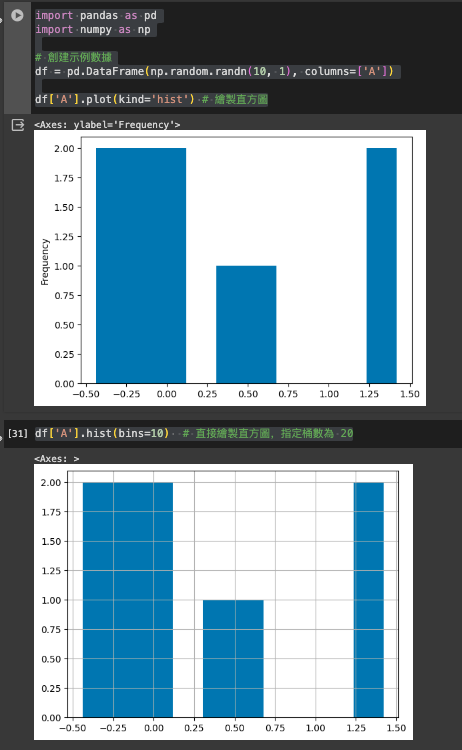
scatter() 散點圖.scatter() 專用於繪製散點圖,顯示兩個變量之間的關係。
它需要指定 x 和 y 軸的數據列,通常用於探索不同變量之間的關聯性或數據的分佈特徵。
用法:
df.plot(x='column1', y='column2', kind='scatter') # 使用 plot 方法繪製散點圖
# 或
df.plot.scatter(x='column1', y='column2') # 直接使用 scatter 方法
x, y: 分別表示橫軸和縱軸的列名。import pandas as pd
import numpy as np
# 創建示例數據
df = pd.DataFrame(np.random.randn(10, 2), columns=['column1', 'column2'])
df.plot(x='column1', y='column2', kind='scatter') # 使用 plot 方法繪製散點圖
# 或
df.plot.scatter(x='column1', y='column2') # 直接使用 scatter 方法
matplotlib 庫,因為 Pandas 的繪圖功能是建立在 Matplotlib 之上的。通過這些基本的繪圖方法,你可以快速對 DataFrame 中的數據進行視覺化,以幫助理解數據的特徵和關係。
以下是一個關於 Pandas DataFrame 常用繪圖方法的表格,包括每個方法的名稱、說明及範例:
| 圖表方法 | 說明 | 範例 |
|---|---|---|
| plot() | 繪製線圖或通過kind參數繪製其他圖表 | df.plot(x='x_column', y='y_column', kind='line') |
| hist() | 繪製直方圖,顯示單變量的分布情況 | df['column'].hist(bins=10) |
| scatter() | 繪製散點圖,觀察兩個變量之間的關係 | df.plot(x='x_column', y='y_column', kind='scatter') |
| bar() | 繪製柱狀圖,比較不同項目的大小 | df.plot(kind='bar') |
| box() | 繪製箱形圖,顯示數據的分布統計 | df.plot(kind='box') |
| area() | 繪製面積圖,通常用於表示累計數據 | df.plot(kind='area') |
| pie() | 繪製餅圖,顯示各部分佔比 | df.plot(kind='pie', y='column') |
在使用這些方法時,一般會需要指定 x 軸和 y 軸對應的列名(除了 hist() 和 pie() 等特殊情況)。此外,這些方法均可通過添加額外的 Matplotlib 參數進行自定義,例如設置圖表的大小、顏色、標題等。這些基本的繪圖方法可以幫助快速理解和呈現數據。
Pandas 是一個功能強大的數據處理工具,非常適合用於處理各類型的數據問題,成為數據處理的得力助手。雖然它的上手難度相對較高,但透過持續的練習和應用,可以逐步掌握其精髓。對於那些未來有志於使用 Python 進行人工智慧相關開發的學習者來說,Pandas 是一個不可或缺的模組。它不僅提升數據分析效率,也是構建高效 AI 模型的基石。
分享所學貢獻社會
[Python教學]開發工具介紹
[開發工具] Google Colab 介紹
[Python教學] 資料型態
[Python教學] if判斷式
[Python教學] List 清單 和 Tuple元組
[Python教學] for 和 while 迴圈
[Python教學] Dictionary 字典 和 Set 集合
[Python教學] Function函示
[Python教學] Class 類別
[Python教學] 例外處理
[Python教學] 檔案存取
[Python教學] 實作密碼產生器
[Python教學] 日期時間
[Python教學] 套件管理
[Python爬蟲] 網路爬蟲
[Python爬蟲] 分析目標網站
[Python爬蟲] 發送請求與解析網站內容
[Python爬蟲] Requests 模組
[Python爬蟲] Beautiful Soup 模組
[Python爬蟲] Selenium 模組
[Python爬蟲] Pandas模組
我們推出電子報拉,歡迎大家訂閱免費電子報,會接收到分享的程式文章,
透過閱讀文章,今天比昨天進步一點,每天的一小步,就是未來的一大步。
訂閱免費電子報
Facebook 粉絲頁 - TechMasters 工程師養成記
程式教育 - 工程師養成記
同步分享到部落格
 pellok
pellok
