
Paper link | Note link | Code link | NeurIPS 2020
這項研究開發了一個檢索增強生成(RAG)模型,以解決語言模型的限制。它結合了預訓練的語言模型和維基百科的密集向量索引,使用神經檢索器來提高特定任務的表現並減少錯誤信息。
儘管大型語言模型經過廣泛訓練,展現了令人印象深刻的表現,但它們在知識密集型或特定任務上仍面臨限制。本研究旨在提出一種架構,通過檢索增強生成來微調這些模型。
如今,預訓練語言模型可能會產生幻覺,即包含看似真實但實際上是虛假或誤導的信息。
最近,將參數記憶與非參數(即檢索基礎)記憶結合的混合模型在解決這些問題方面顯示出了潛力。兩項研究,REALM 和 ORQA,使用了帶有可微分檢索器的遮蔽語言模型,顯示在開放域抽取式問答中取得了改善的結果。

這項研究構建了RAG模型,其中
這些模組在一個概率模型中結合,並進行端到端的訓練。
目的:根據查詢 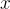 返回文本段落的(前K名截斷的)分佈。
返回文本段落的(前K名截斷的)分佈。
它使用最大內積搜索來計算具有最高先驗概率的前K名文檔。
Backbone model: BERT base
它可以為每個目標標記選擇不同的潛在文檔並相應地進行邊際化。
這使得生成器在生成答案時能夠從多個文檔中選擇內容。
它使用相同的檢索文檔來生成完整的序列。
目的:根據前一個標記 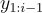 的上下文、輸入
的上下文、輸入 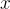 和檢索到的段落
和檢索到的段落  來生成標記。
來生成標記。
Backbone model: BART
它仍然被視為自回歸序列到序列生成器。
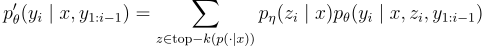
它無法通過單次束搜尋來解決。
Thorough Decoding: 對每個文檔 執行束搜尋,使用 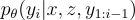 來評分假設。如果某個假設
來評分假設。如果某個假設 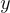 在所有束中都沒有出現,則對每個文檔 進行額外的前向傳播,以估算其概率,並與
在所有束中都沒有出現,則對每個文檔 進行額外的前向傳播,以估算其概率,並與 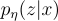 相乘後在束中求和。
相乘後在束中求和。
Fast Decoding: 為了避免對長輸出序列進行大量的前向傳播,對於在束搜尋中未從 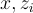 生成的假設
生成的假設 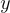 ,使用了近似
,使用了近似 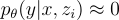 。這簡化了在生成候選集
。這簡化了在生成候選集 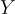 後的過程。
後的過程。
這項研究評估了四個任務:
下方展示在問答方面與其他比較方法來說有些許成效

下方生成文字生成有降低幻覺發生,? 表示事實上不正確的回答,* 表示部分正確的回答。

