接下來想來試試用產圖,Gemini 現在可以畫圖了(用中文指令會沒反應,得用英文)。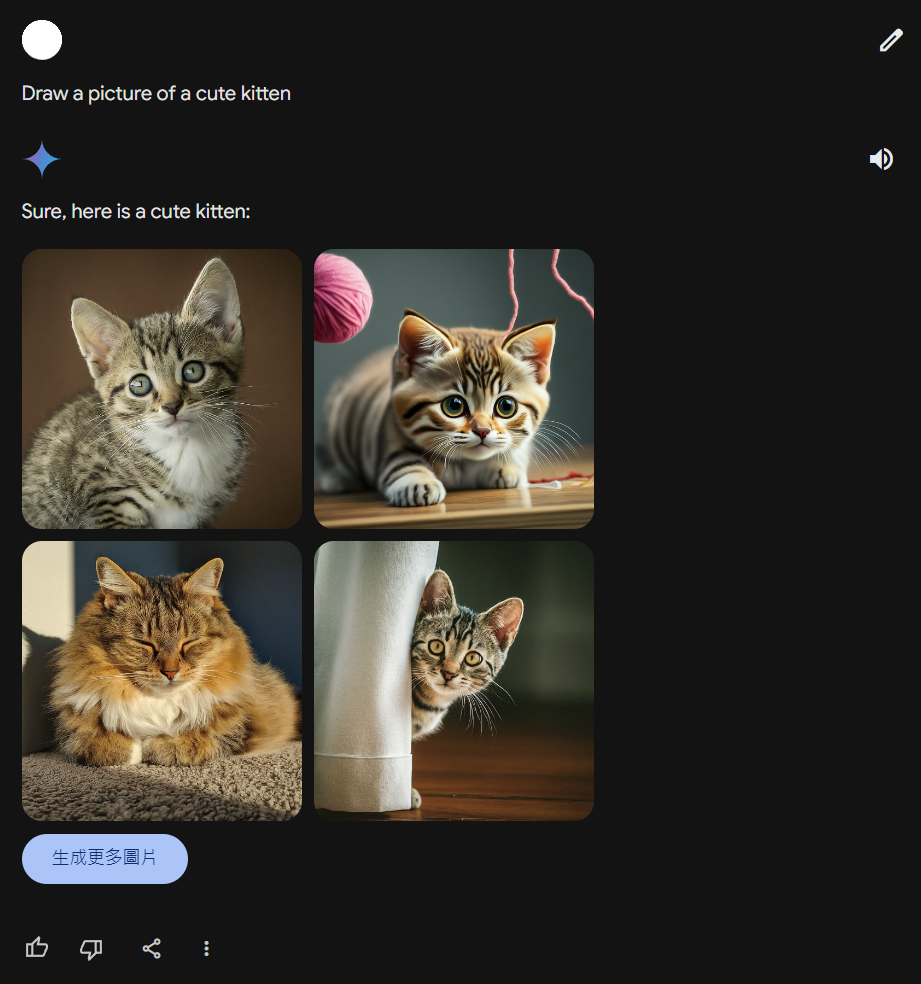
我想著 API 肯定也可以用了吧,找了半天發現他只開放在 Vertex AI 上,得另外計價,而且要用還得要填表申請,猶豫了很久決定先不試,直接去用我已經買了 plus 的 ChatGPT。
https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/imagen-api
https://cloud.google.com/vertex-ai/generative-ai/docs/image/overview#feature-launch-stage
https://cloud.google.com/vertex-ai?hl=zh-TW#pricing
於是我開啟 API 頁面看,發現他特別提示了 API 帳單跟 ChatGPT 是分開的,我這才意識到他是 open ai API,本來就不一樣,想的太美了。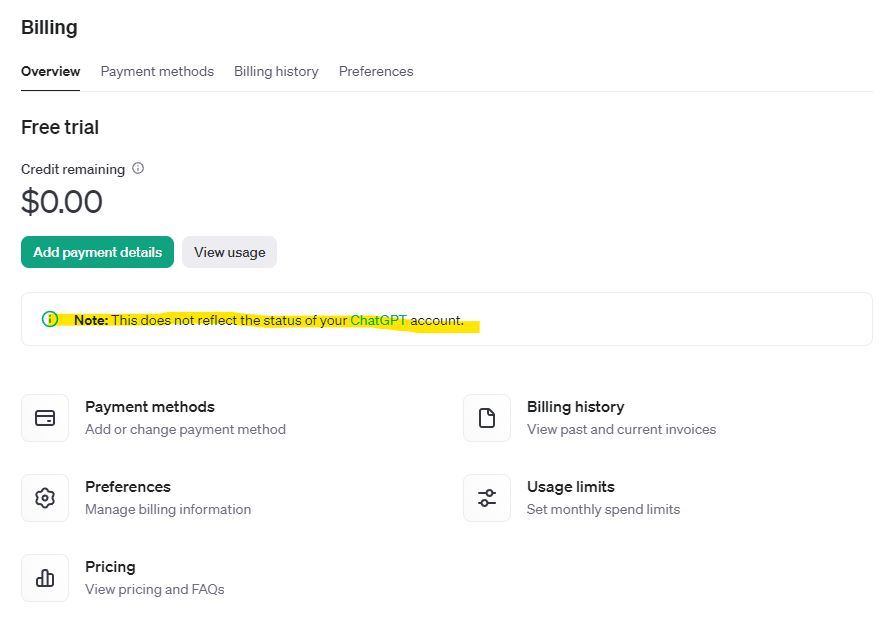
猶豫再三,決定還是先找個開源的模型試試,免費的測完再去玩付費的。想著去年試過的 stable diffusion 效果還不錯,乾脆再把他架起來試試,於是上網搜尋一下目前發展到甚麼地步。
https://platform.stability.ai/pricing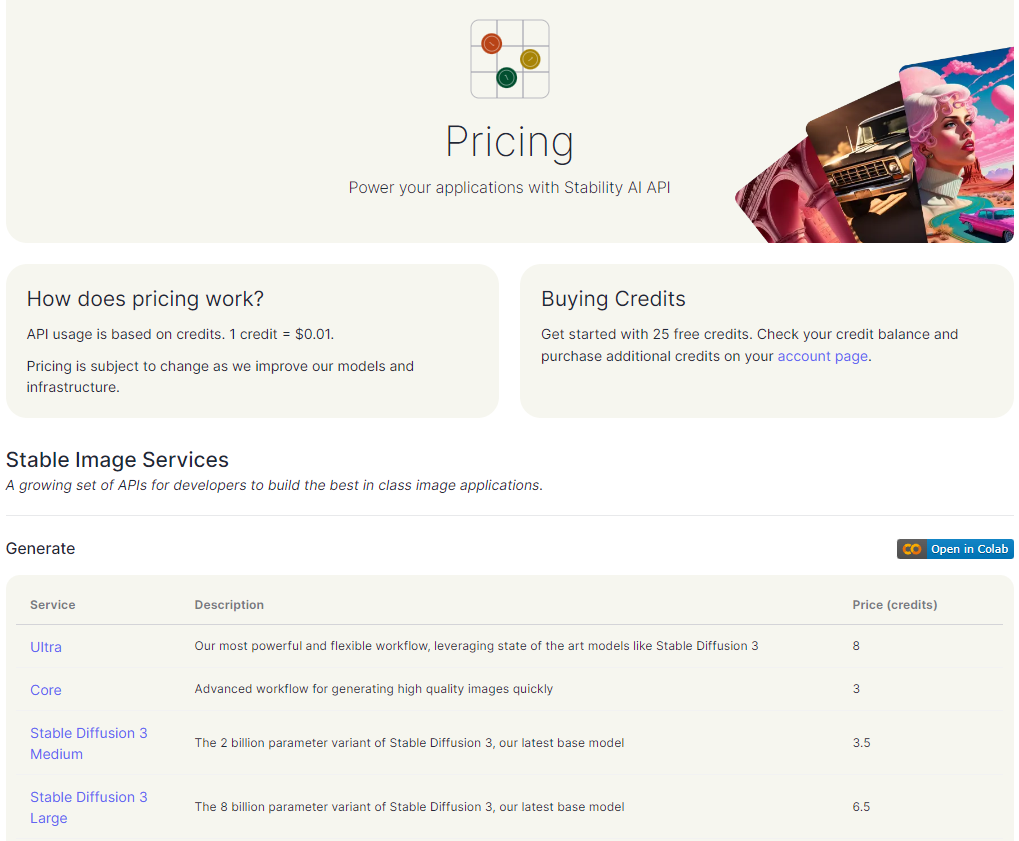
發現發展到要收費了...
不過還好舊版本的模型有開源,從開源版本中選了效果不錯的 Stable Cascade 來試試。
Stable Cascade 有發佈在 huggingface 上,那要測就很單純了,甚至連範例程式都寫好了。
https://huggingface.co/stabilityai/stable-cascade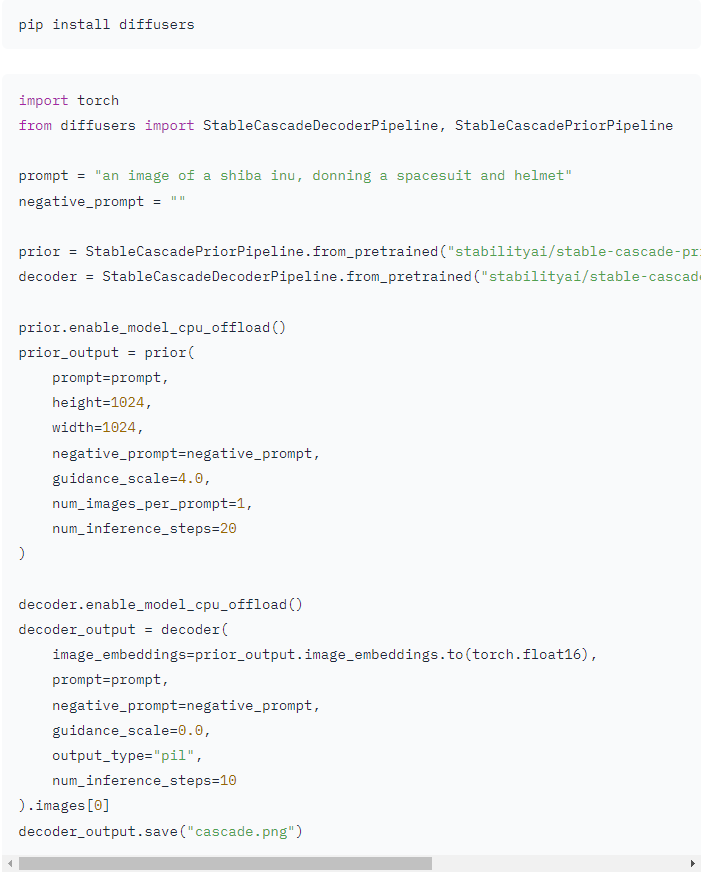
這次一樣到 colab 架,選一個有 GPU 的環境,我跟之前一樣選了 T4 GPU。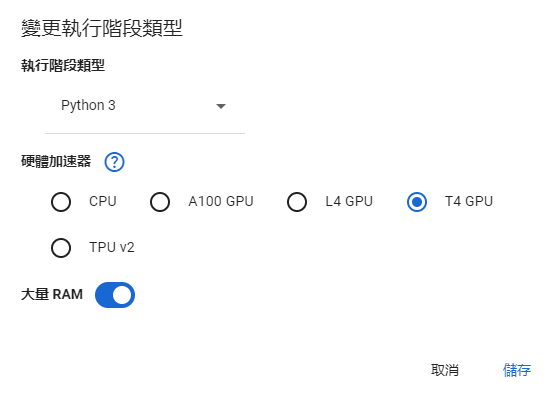
照著做就行了,先把 huggingface 的 library,diffusers 裝起來。
pip install diffusers
Collecting diffusers
Downloading diffusers-0.30.0-py3-none-any.whl.metadata (18 kB)
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.10/dist-packages (from diffusers) (8.2.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from diffusers) (3.15.4)
Requirement already satisfied: huggingface-hub>=0.23.2 in /usr/local/lib/python3.10/dist-packages (from diffusers) (0.23.5)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from diffusers) (1.26.4)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from diffusers) (2024.5.15)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from diffusers) (2.32.3)
Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from diffusers) (0.4.4)
Requirement already satisfied: Pillow in /usr/local/lib/python3.10/dist-packages (from diffusers) (9.4.0)
Requirement already satisfied: fsspec>=2023.5.0 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub>=0.23.2->diffusers) (2024.6.1)
Requirement already satisfied: packaging>=20.9 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub>=0.23.2->diffusers) (24.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub>=0.23.2->diffusers) (6.0.2)
Requirement already satisfied: tqdm>=4.42.1 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub>=0.23.2->diffusers) (4.66.5)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub>=0.23.2->diffusers) (4.12.2)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.10/dist-packages (from importlib-metadata->diffusers) (3.20.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->diffusers) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->diffusers) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->diffusers) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->diffusers) (2024.7.4)
Downloading diffusers-0.30.0-py3-none-any.whl (2.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.6/2.6 MB 29.6 MB/s eta 0:00:00
Installing collected packages: diffusers
Successfully installed diffusers-0.30.0
之前測試時有時候會發現環境沒有切換正確,所以我會先確認一下 torch 版本,還有 GPU 是不是能被使用的。不然等下載模型完才發現,又得刷新環境重來,會浪費時間。
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
print(torch.__version__)
print(torch.cuda.is_available())
2.3.1+cu121
True
把模型下載下來。
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", variant="bf16", torch_dtype=torch.bfloat16)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", variant="bf16", torch_dtype=torch.float16)
給 prompt 讓模型生成影像。
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
negative_prompt = ""
prior.enable_model_cpu_offload()
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder.enable_model_cpu_offload()
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.to(torch.float16),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save("cascade.png")
可以把圖打開看看效果,還算順利。
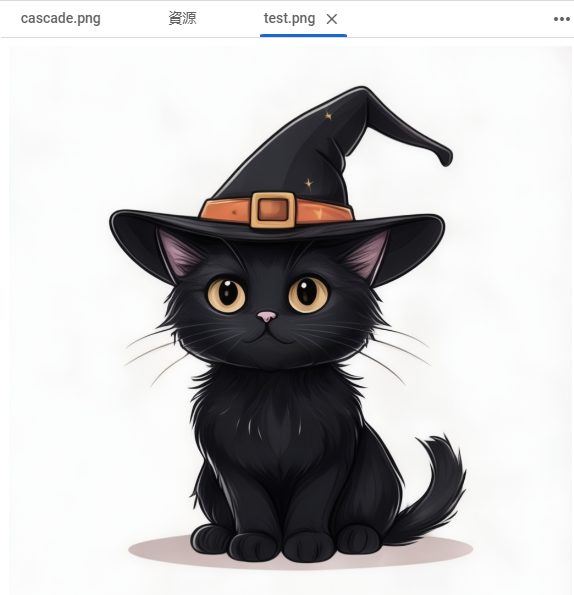
換個 prompt 試試,效果不錯。
prompt = "cute black cat, Wearing a wizard hat. Cartoon."