有鑑於 Stable Diffusion XL 的好效果,我決定繼續用他試試。
我原本想要先試試文生圖看看效果,突然發現又重新載了模型,細看才發現兩者是有差異的,可以查看說明。
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
一樣先裝好 diffusers,接著試試他文生圖的效果。
pip install diffusers
import torch
from diffusers import AutoPipelineForText2Image
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
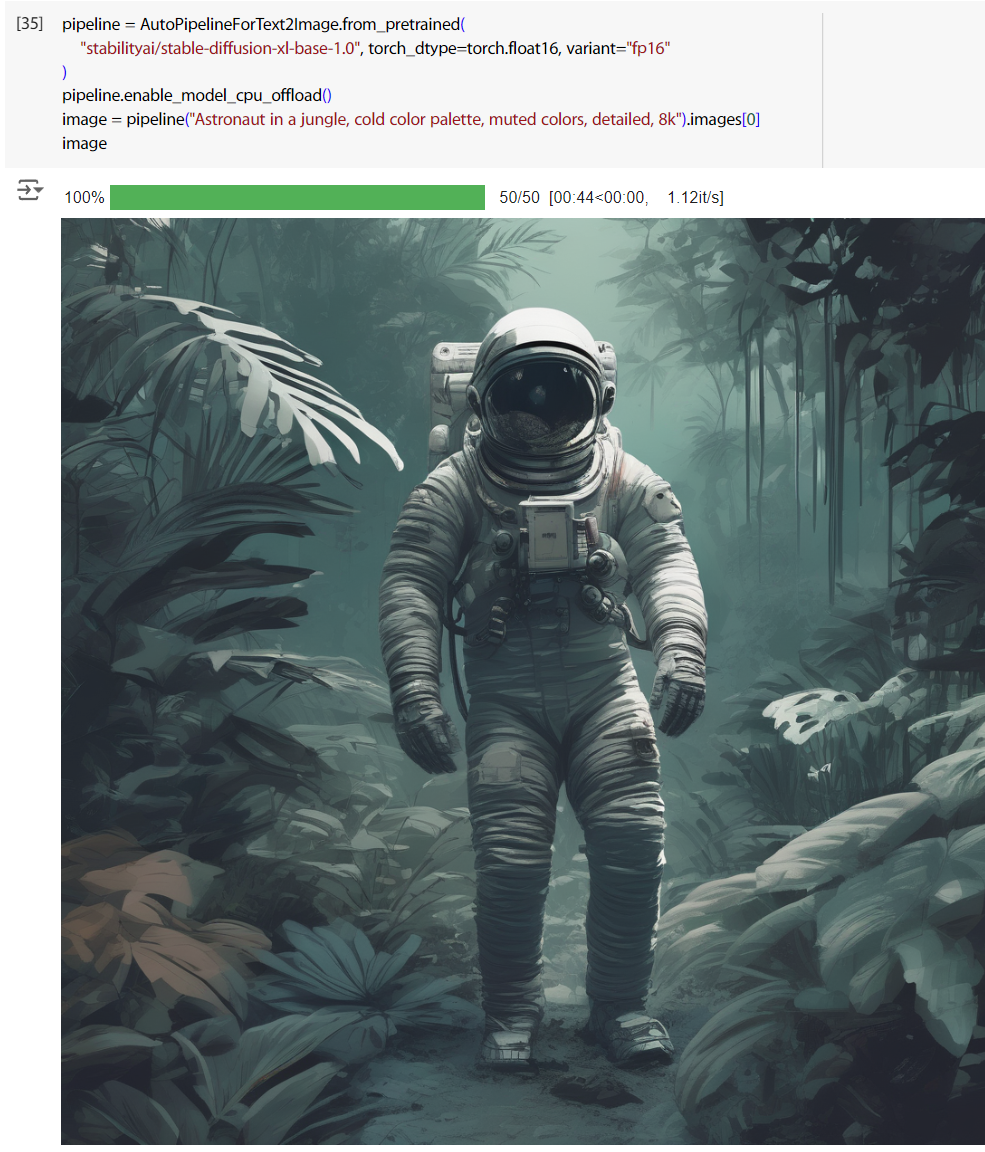
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k").images[0]
image
我們可以再加上 guiding_scale 參數,這可以調整他的 "creativity",越小越 creativity。嘗試一下看看效果,從左到右就是最有創意到最沒創意。
imageA = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
guidance_scale=0.5
).images[0]
imageB = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
guidance_scale=3.5
).images[0]
imageC = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
guidance_scale=7.5
).images[0]
make_image_grid([imageA, imageB, imageC], rows=1, cols=3)

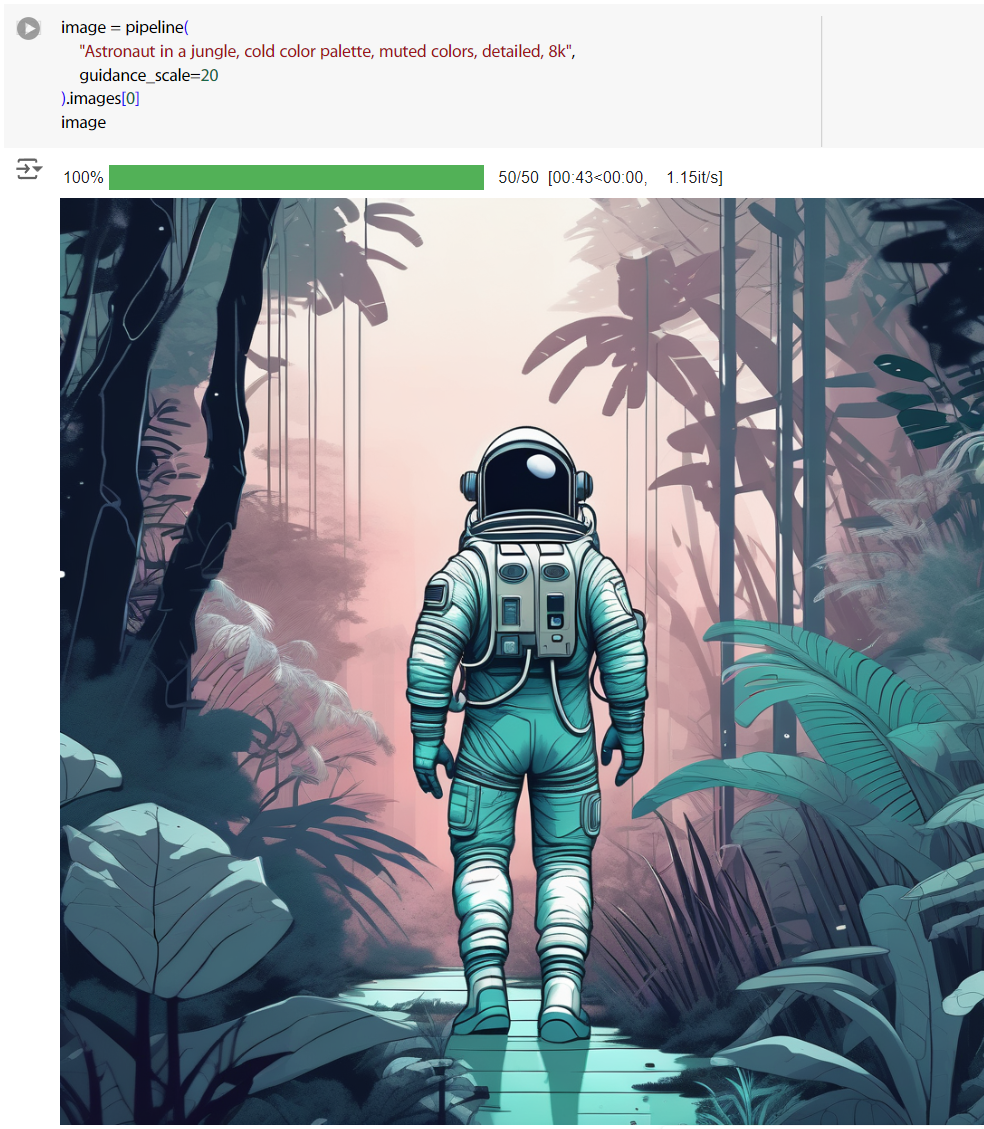
要注意調太高容易會有 artifacts,應該是翻成偽影? 直接調到 20,看起來頭跟腳的方向有點不正常。
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
guidance_scale=20
).images[0]
image
加上 negative_prompt 參數,避免出現不想生成的內容。height,width 可以設定大小,不過 Stable Diffusion XL 生成的影像最小是 512x512。
image = pipeline(
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
negative_prompt="tree,flower,red",
height=768,
width=512,
guidance_scale=3.5
).images[0]
image

另一個有趣的用法是 Inpainting,給一個 mask,只改動 mask 範圍內的影像。
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipelineForInpainting = AutoPipelineForInpainting.from_pipe(pipeline)
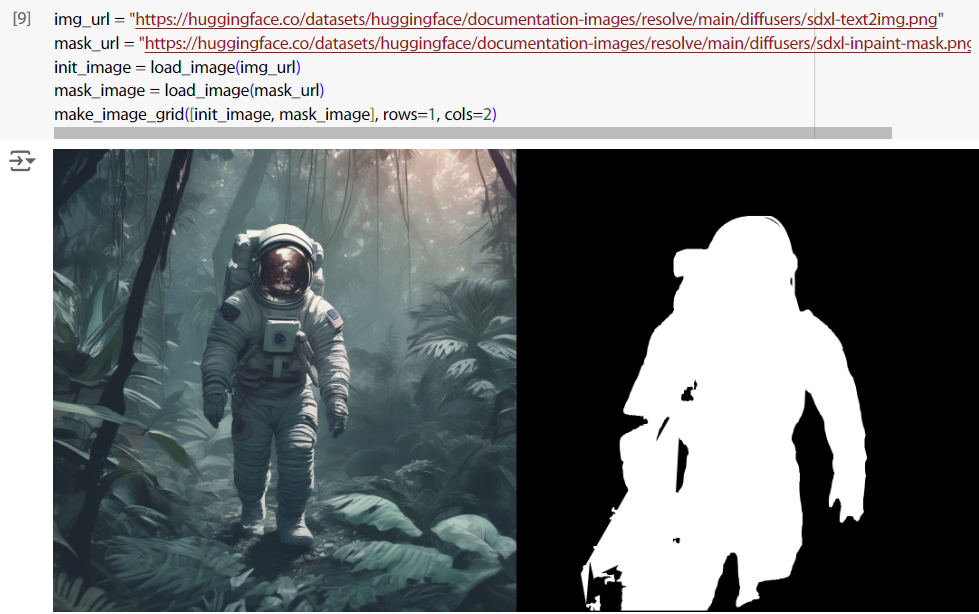
讀兩張測試用圖,右圖就是 mask,目標是更改 mask 範圍中的影像。
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
mask_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint-mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
make_image_grid([init_image, mask_image], rows=1, cols=2)
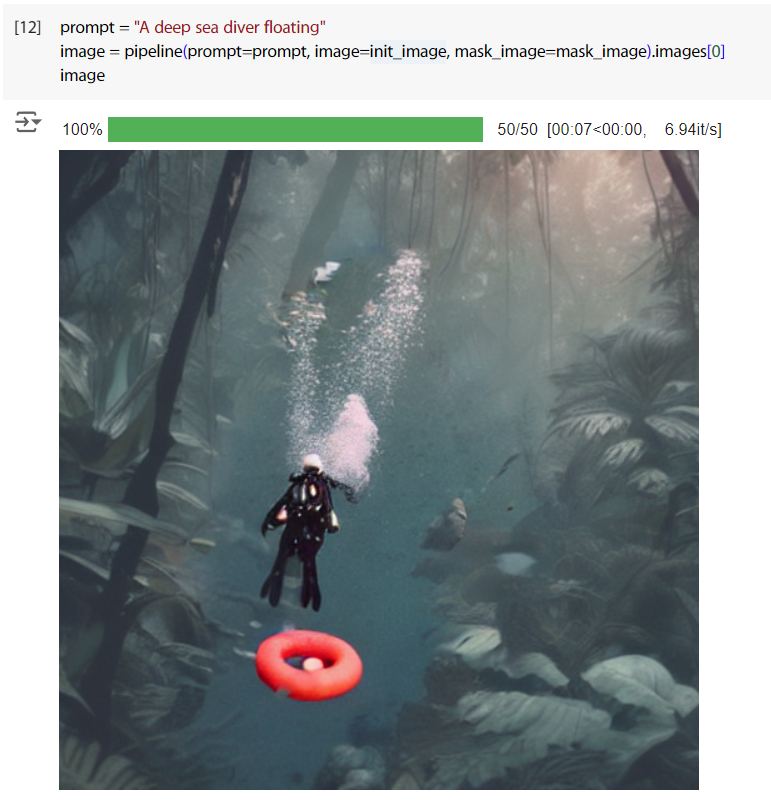
下 prompt 試試,成功的只改動了 mask 範圍內的影像。
prompt = "A deep sea diver floating"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
image
這邊使用的 AutoPipelineForInpainting.from_pipe,文件上是說要避免重新分配記憶體。
https://huggingface.co/docs/diffusers/api/pipelines/auto_pipeline#diffusers.AutoPipelineForInpainting
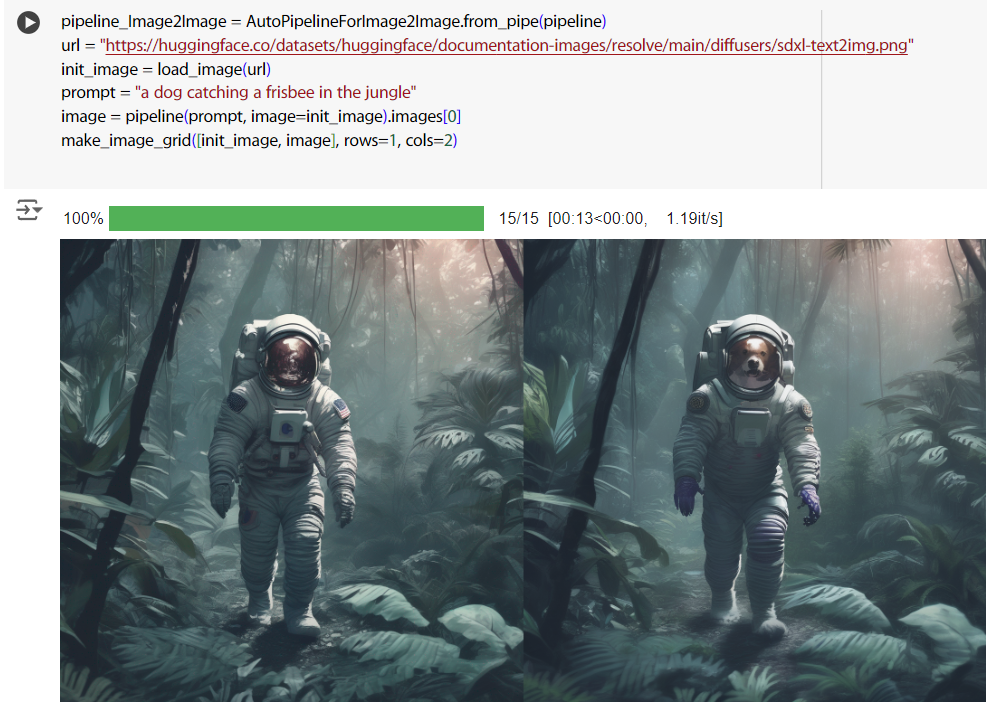
from_pipe 這方法 AutoPipelineForText2Image、AutoPipelineForImage2Image也都有,例如說像這樣,一樣拿 Text2Image 的 pieline 來用。
https://huggingface.co/docs/diffusers/api/pipelines/auto_pipeline#diffusers.AutoPipelineForText2Image
https://huggingface.co/docs/diffusers/api/pipelines/auto_pipeline#diffusers.AutoPipelineForImage2Image
pipeline_Image2Image = AutoPipelineForImage2Image.from_pipe(pipeline)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
init_image = load_image(url)
prompt = "a dog catching a frisbee in the jungle"
image = pipeline(prompt, image=init_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
AutoPipelineForInpainting 看文件的描述,也可以使用 from_pretrained。但我實際上使用 from_pretrained 來讀取時,雖然可以成功建立 pipeline,生成影像時卻會不斷運行,且沒有任何輸出。原本想說是我選錯 model,因為他有分 base 跟 refiner,但調整過後也不見好轉,得再研究研究。

