這一章將介紹LLM在GPU上平行化使用的方法,這章內容比較少,但標題很長XD
如果運算上有什麼資源不夠的,沒有什麼是一個GPU不能解決的,如果有的話,那就再來一個。
------BY 筆者 🎉
一般我們會透過使用更多的GPU在多個設備上分配計算工作,來做LLM的訓練或推理服務 🖥️🚀。而model parallelization主要分成兩種方式,透過將模型的tensors或layers分散在多個GPU上來最小化模型的記憶體使用 📉,不過使用上同時也多了設備之間傳輸的時間 ⏱️。
在這些方法當中並不是一次只能選擇一個,如果你的GPU夠多,是可以一起搭配使用的。它們在vLLM中的數量設定公式是:你有幾張GPU = tensor-parallel-size * pipeline-parallel-size
在Tensor Parallelism的狀況下,模型張量可以依照矩陣的row或colums去做分割,分別放在不同的GPU上,而不是全部的張量都在同一個GPU上,GPU們再各自對自己分割的部分去做平行矩陣乘法運算,在每層計算後進行跨GPU之間的數據交換。
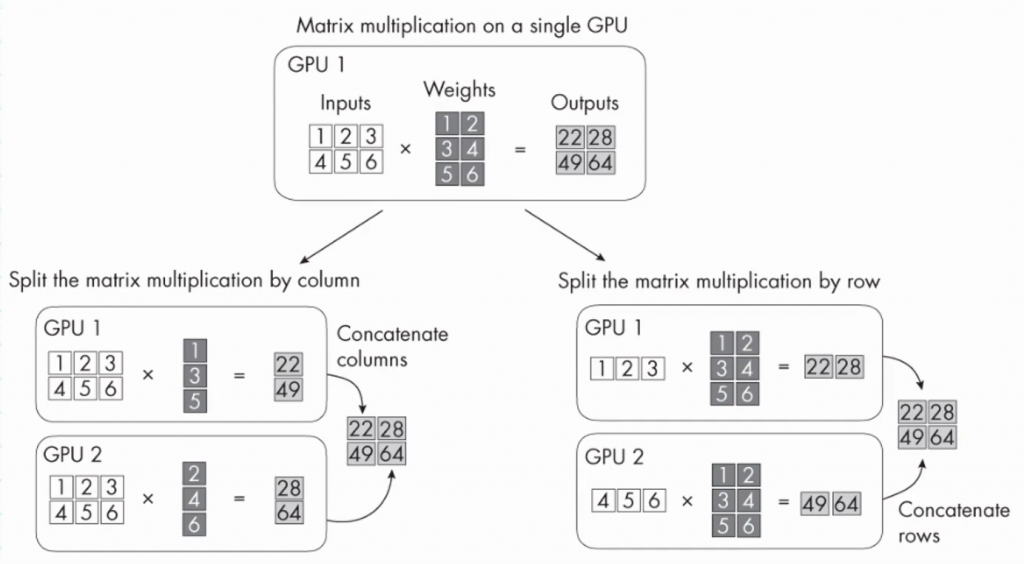
(圖源: youtube截圖)
emoji解說:代表將tensors拆分並分配到不同的GPU上。
2024/12補:目前後續實作的vllm使用的是Megatron-LM’s tensor parallel algorithm。
在Pipeline Parallelism的狀況下,模型會被分成很多layer groups,每個GPU分別去處理其中一組layer group,這可以最大化減少每個GPU的記憶體需求。但因為layer dependencies,會像是流水線一樣一個GPU計算完傳到下一個GPU,大部分的GPU在沒計算的時間是空閒的。
使用的時機是如果你擁有更大的模型像是400B,一張GPU絕對裝不下的時候,也許可以考慮使用Pipeline Parallelism,他是將模型的不同層或部分分配到不同的GPU上,讓每個GPU負責模型的一部分計算。這樣就可以提高GPU的利用率和計算效率,通常會用到的時候是你的模型超級大的時候。
emoji解說:代表分階段處理計算,如同管線作業。
假設你有一個包含4層的神經網路模型,你有兩張GPU,一次只選一個方法的狀況。
將模型的每一層張量分割成兩部分,第一部分分配到第一個GPU上,第二部份分配到第二個GPU上。每個GPU都同時處理同一層不同部分的運算任務,然後同步結果,這樣可以均衡利用每個GPU的運算能力。
將模型的前兩層分配到第一個GPU上,後兩層分配到第二個GPU上。第一個GPU計算前兩層,然後將中間結果傳遞給第二個GPU計算後兩層。
如果第一層運算時間較短,第二層運算時間較長,那麼第一張GPU可能會等待第二張GPU完成其運算任務,然而這樣整體運算時間可能就會增加。
在訓練模型的時候,可能會有一個狀況是GPU的記憶體不夠,但資料量卻非常大。這時選擇將資料拆成很多batches送到不同GPU當中平行訓練,最後再將各個GPU計算得到的梯度進行整合(平均),從而更新模型的權重。不過前提是這邊每個GPU需要可以容納下一個模型才行。
如果以上筆者的介紹都是文字,寫得太難懂,推薦可以看這一個有圖片的yt介紹,應該會比較好理解一些。
Model Parallelism vs Data Parallelism vs Tensor Parallelism | #deeplearning #llms
emoji解說:代表將資料分配到多個GPU平行處理。
現在學會了幾種常見的model parallelization方法,這些方法的主要目的是在GPU的記憶體無法容納整個模型,或在擁有多個GPU的情況下,透過計算任務分散到各GPU上,平衡GPU們的工作負載,減少一些compute bound和memory bound的限制,提升整體系統的效率。
上一章雖然說到Ray可以幫助管理和自動調度計算資源,但Ray並不會自動配置最佳的平行化方式,所以還是要先理解如何在GPU上配置模型!
雖然想在這一章放上實作內容做明顯的比較,但是有些名詞是後面理論才會提到的,只能往後移到後續章節了。

(圖源: 自製,靈感參考)
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
https://arxiv.org/pdf/2401.00625

