前一篇文章提過要盡可能地將數據收集完整,但現實情況中往往會有不完美的情況,導致直接影響到數據的質量,從而對後續的建模分析產生不利影響。高質量的數據是模型訓練的基礎,如果輸入的訓練數據存在許多噪音和不一致,即使採用了最先進的算法和模型,最終的結果也很難令人滿意。資料探勘 (Data Mining) 能幫助我們觀察數據的本質屬性和隱藏規律。通過可視化、統計分析、相關性分析等技術,我們能夠全面理解數據,發現異常點、缺失值模式等潛在問題,為後續的數據清理做好準備。
資料探勘的目標是深入瞭解數據的本質特徵,發現潛在的規律、趨勢和關聯,為接下來的數據清理和模型建構做好充分準備。它主要包括:
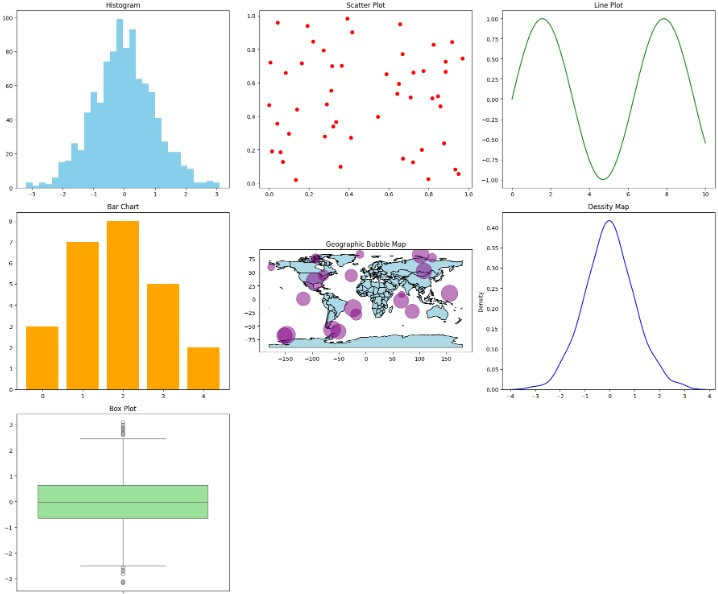
[筆者自行用 google colab 隨機生成數據點並繪製以上提到的資料視覺化的圖
google colab 連結]
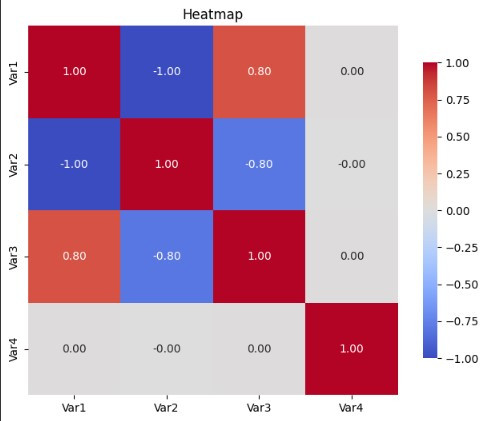
[筆者自行使用隨機數字生成 Heatmap圖,google colab]
在進行相關係數分析時,需要特別注意特徵之間是否有多重共線性 (Multicollinearity) 問題,也就是特徵與特徵之間如果存在過度高度相關,可能會導致模型過度依賴這些特徵,從而增加它們的權重。如果這些特徵對模型有負面影響,這種過度的權重會反而削弱模型的穩定性和解釋性。
Q1-1.5*IQR 或大於 Q3+1.5*IQR 的數據點被視為潛在異常值。[Note: Q1:前 25% 的數據,Q2:中位數,Q3:前 75% 的數據,IQR:Q3-Q1 的數值]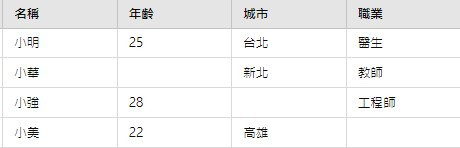
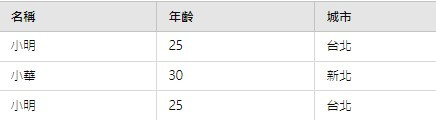
通過資料探勘,我們能夠充分掌握數據的質量和特性,發現潛在的問題和不足。下一步就是解決觀察到的問題並進一步的做數據清理,以確保後續模型訓練和預測結果的準確性。無論是分析數據分布還是識別異常數據,這些資料探勘工作都能夠幫助我們更好地理解和利用數據,為數據的進一步處理和分析做好充分準備。下一篇我們將會提供數據清理的方法。

