RAG(檢索增強生成)是一種將預訓練(Pre-training)的大型語言模型 (LLM) 與外部資料結合的技術,使 LLM 能夠生成更準確、與情境更貼合的回應。試想我們有一個非常聰明的機器人 GPT,但他對某些專業領域的知識可能不太了解,那我們該怎麼讓他更聰明呢?沒錯,答案就是「OpenBook」!相信大家在求學時期都考過OpenBook的考試,雖然有時候書上並沒有直接的解答😭,但在這裡我們必須提供正確的資料給 LLM ,否則生成的內容可能會像我們考試沒讀書時一樣慘不忍睹。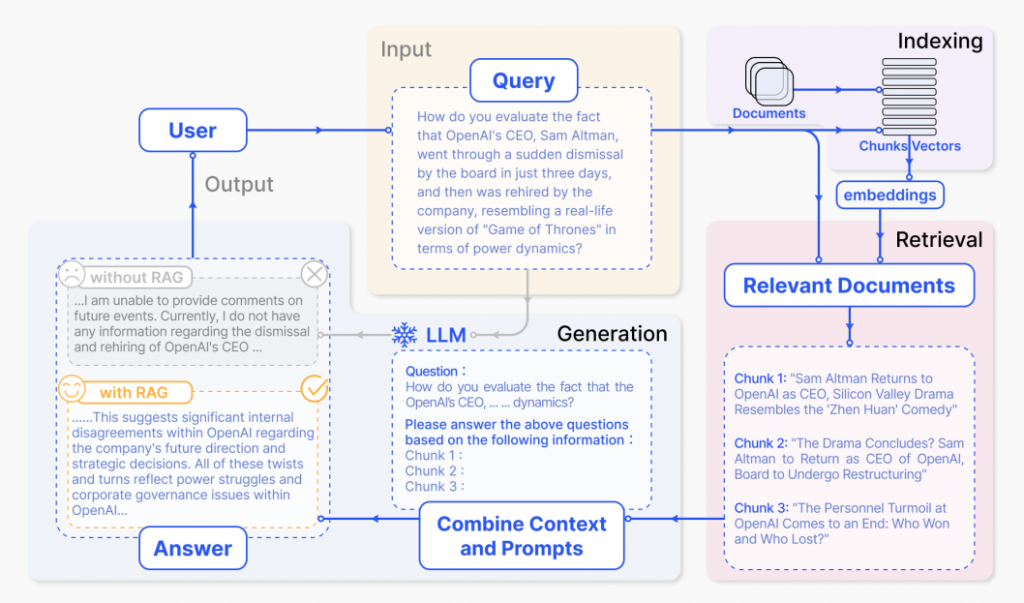
Pre-training 階段是訓練大型語言模型(LLM)的第一步,此階段的目的是讓模型學習如何處理語言,理解文本的結構和內容。在這個階段 LLM 主要依賴於大量的文本數據來進行語言學習。 Pre-training 在RAG技術中旨將大量「外部」知識與模型「內部」的語言知識進行結合,如 Llama、Mistral 等模型。(這邊的概念像是幫助 LLM 具備基礎知識,需要花費大量的運算資源。)
優點👍:
挑戰💪:
如何有效地將外部資料整合進模型的學習過程中,是一個關鍵問題。如果外部資料品質不佳,可能會對訓練產生干擾。
花費成本高,需要大量運算資源、資料訓練。
Fine-tuning 階段是在模型經過 Pre-training 後,針對具體任務更進一步訓練。這通常涉及到特定的應用場景,比如問答系統(QA)、文本生成等。 Fine-tuning 在 RAG 技術中可以幫助 LLM 在過程中獲取與任務相關的特定資訊。(例如在醫療問答系統中,模型不僅需要知道一般的醫療知識,還需要檢索最新的醫療研究結果來回答問題。這樣的微調可以幫助模型應對更加專業和精確的需求。)
優點👍:
挑戰💪:
如何平衡 Fine-tuning過程中的內部知識和外部檢索來的資料,是一個難點。如果依賴外部資料過多,可能會使模型忽略自身的知識。
Inference 是指模型在實際應用中的表現階段,即模型如何根據使用者的「問題」來產生「答案或解決方案」。Inference 是最早獲得廣泛研究的部分,因為模型需要能夠在處理複雜問題時,及時從外部資料庫檢索到相關資料來補充它的生成過程。這個階段是RAG技術發展的最初焦點,因為語言模型在推理階段經常會遇到知識不足或過時的問題。通過RAG技術,模型可以實時檢索相關的文件或文章來幫助回答問題。(像是ChatGPT這類模型,在面對一個與近期事件有關的問題時,它可能無法直接回答,因為它的知識來源於過去的訓練數據。但如果搭配RAG技術,ChatGPT 可以即時檢索與問題相關的最新新聞文章,然後用這些資料來生成答案。)
優點👍:
挑戰💪:
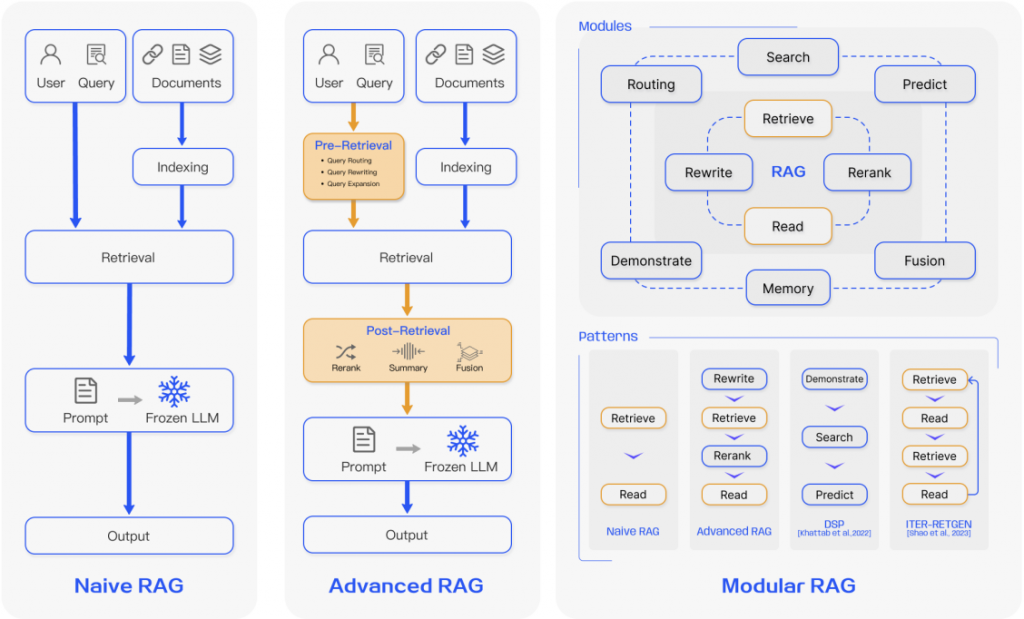
RAG 技術隨著語言模型的發展逐漸演化,並可劃分為三個主要發展階段:Naive RAG(初級RAG)、Advanced RAG(進階RAG) 和 Modular RAG(模組化RAG)。每個階段都在處理 LLM 的局限性,如資訊檢索、生成準確性和整合外部資料的方式上,展現了不同的技術進展。以下是對這三個主要階段的詳細介紹:
Naive RAG 是最早的檢索增強生成技術,主要關注於基礎的檢索和生成流程,將外部資料庫中的內容檢索後,直接與模型的輸入結合,來生成答案。這個階段的技術著重於基本的架構設計。
優點👍:
缺點👎:
檢索問題:檢索結果的精確度可能不足,檢索回來的段落不一定與問題完全相關,導致模型生成出錯誤或不相關的答案。
生成問題:有時即使檢索到的段落與問題相關,模型也可能生成不準確或不連貫的答案,甚至發生「幻覺」現象(即模型生成與實際事實不符的內容)。
整合困難:檢索到的段落有時資訊過多或重複,難以有效整合,生成的結果可能出現冗餘或不一致。
Advanced RAG 對 Naive RAG 的不足進行改進,專注於優化「檢索」和「生成」階段,並引入了更多技術來提升檢索準確性和生成品質。這一階段的研究逐漸從單純的檢索和生成,發展到在檢索前後都進行「優化操作」。
預檢索優化(Pre-retrieval Optimization):在檢索之前,進階RAG會進行各種優化操作,如:
後檢索優化(Post-retrieval Optimization):在檢索到資料後,進階RAG會進行後處理,比如:
優點👍:
缺點👎:
系統變得更加複雜,優化過程需要更多的計算資源和時間。
對於非常複雜或多變的任務,進階RAG可能依然不足以應對,需要更靈活的技術。
Modular RAG 是目前最先進的RAG技術,它不僅對檢索和生成過程進行了細緻的改進,還引入了「模組化設計」,允許系統針對不同任務使用不同的模組來靈活處理問題。這使得RAG技術變得更加靈活、提升擴展性。
引入新模組:模組化RAG允許添加特定功能的模組來增強檢索和生成過程,比如:
模組替換與重組:Modular RAG 打破了傳統 RAG 中「檢索-生成」的單線流程,允許模組之間進行多次交互,如:
優點👍:
缺點👎:
大部分功能都需要客製化,難以用一種解決方案應付所有領域的問題。
| RAG階段 | 使用場景 | 原因 |
|---|---|---|
| 初級RAG(Naive RAG) | 需求不高,基礎問答或資料檢索。 | 適合簡單檢索、成本低、流程直觀,不需進行複雜的資料處理。 |
| 進階RAG(Advanced RAG) | 需要精確檢索,處理專業問題。 | 提供了更好的檢索準確度,適合知識密集型的專業任務,優化檢索與生成過程,提升結果的相關性和準確性。 |
| 模組化RAG(Modular RAG) | 複雜任務、多模態資料需求。 | 具有高度靈活性,適合多步驟檢索、多模態資料整合,能處理更加複雜和動態的應用場景,並可根據需求定製檢索模組。 |
生成式 AI 的爆發帶動了大型語言模型(LLM)的迅速發展,這些模型在生成文本、回答問題、對話等方面表現出色。然而隨著需求的複雜化和對準確、即時知識的要求增高,語言模型的局限性也逐漸顯現出來,如幻覺、知識過時等。 RAG 技術的出現通過結合外部資料,為 LLM 注入了實即時、精確的知識,使其能更好地處理知識密集型任務。從 Naive RAG 到 Advanced RAG 再到 Modular RAG ,AI 發展的速度超乎我們想像, RAG 已成為生成式AI 不可或缺的一部分。(筆者每天都在 Modular RAG 地獄之中,各種千奇百怪的需求一一出現,我們一起在 AI 領域努力🔥🔥🔥)
參考文獻:"Retrieval-Augmented Generation for Large Language Models: A Survey"


 iThome鐵人賽
iThome鐵人賽