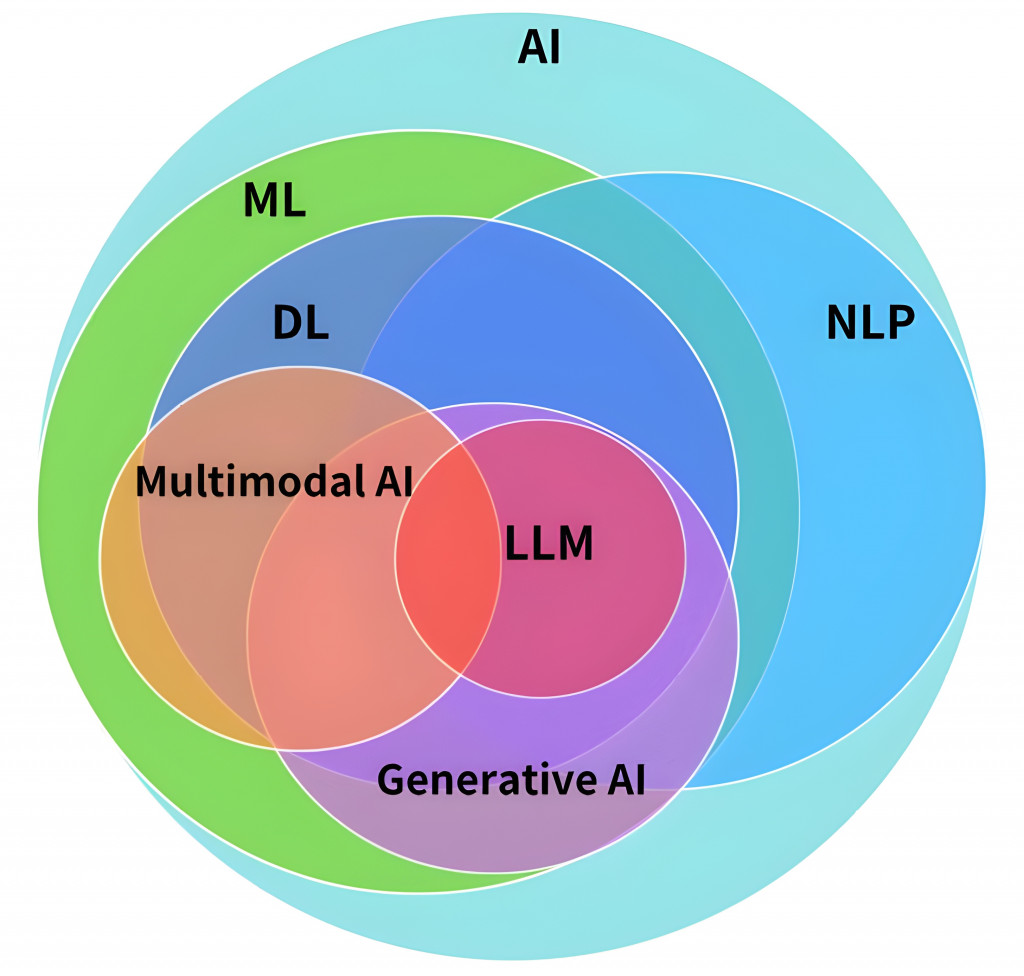
在生成式AI百家爭鳴的今日,大家會很常聽到機器學習、深度學習、生成式AI、大語言模型、RAG、Fine-tuning等很多和AI相關的名詞,簡單釐清大語言模型和其他人工智慧技術之間的關係:
在正式談大語言模型前,先了解一下「基礎模型(Foundation Model)」 。
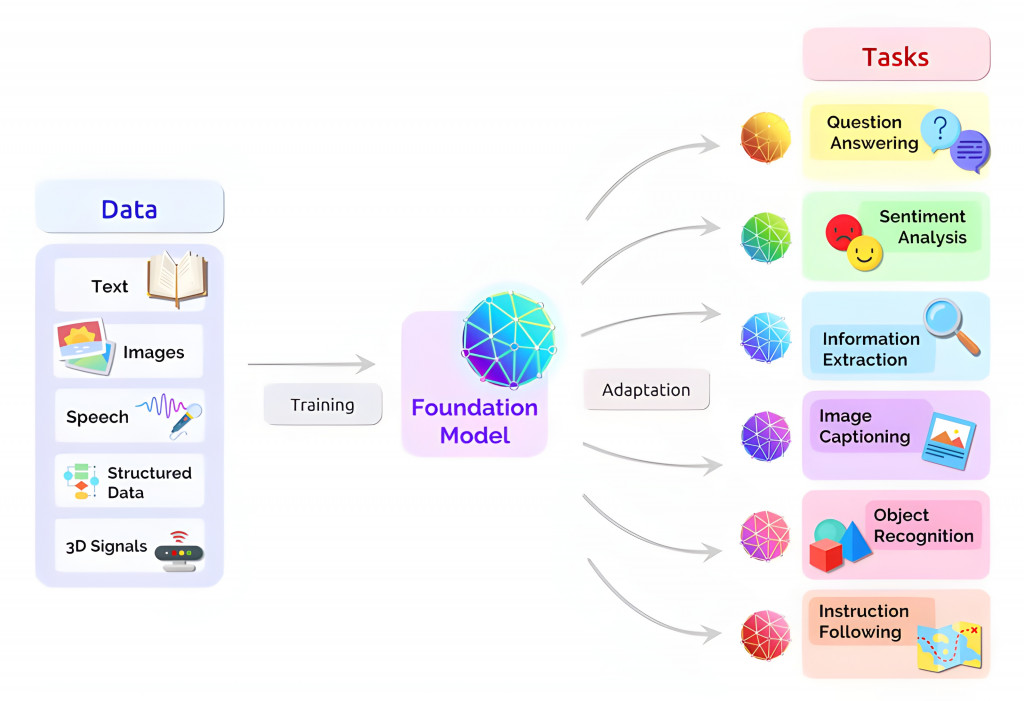
基礎模型Foundation Model是生成式AI的形式之一,這些模型從一個或多個人類語言的輸入 (prompts) 中產生輸出。相較於傳統的機器學習一次只能完成一種任務,Foundation Model基於複雜的神經網路,通常在大量的原始數據上進行預訓練,目標是建立一個通用的知識基礎,可以被應用到多種不同的任務中。包含自然語言處理、計算機視覺等多個領域。
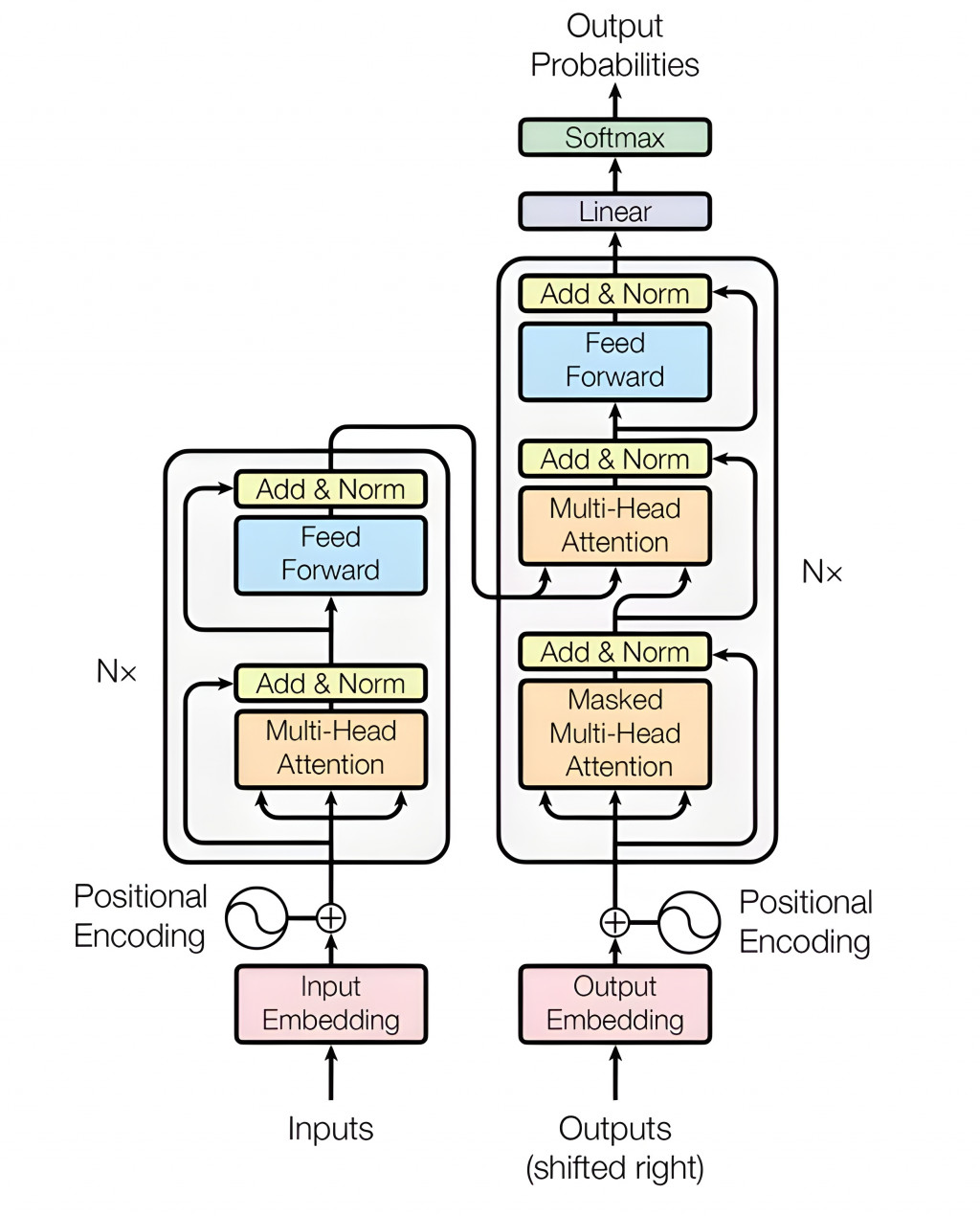
LLM 的發展與 Transformer 架構密切相關。Transformer 是 2017 年由 Google 提出的一種革命性模型架構,最初主要用於處理序列數據(如文本和語音),後來也擴展到其他領域如計算機視覺。其核心創新是自注意力機制,能夠有效學習序列中各元素之間的關聯。Transformer 架構為許多基礎模型提供了技術基礎,推動了包括 LLM 在內的眾多 AI 創新應用的發展。
大語言模型(LLM)是在海量人類語言數據上訓練的基礎模型(Foundation Model)。「Large」在LLM中通常指兩個方面:一是超大規模的訓練數據集,有時可達PB級;二是模型參數的數量,通常達到數十億個。這些參數代表模型從訓練中學到的知識和能力。在模型名稱中常見的'xxB'中的'B'即表示參數數量有多少十億(billion)個。一般來說,參數越多,模型包含的知識越豐富,解決問題的能力也越強。然而,隨著技術的進步,「Large」的定義也在不斷演變。除了基於Transformer的模型外,新型架構如Mamba也在探索解決長序列處理等挑戰。目前,各大科技公司和研究機構都推出了自己的LLM,如Google的Gemini、OpenAI的GPT系列、Anthropic的Claude、Cohere的Command等,推動了LLM技術的快速發展和廣泛應用。
雖然市面各廠家已經有推出了很多的Foundation Model,但要像市面上看到的AI工具將這些語言模型的能力落地應用在實務場景,讓AI可以變成一個工具我們就需要一些方法來調整語言模型,包含Prompt Engineering、RAG、Fine-tuning、Pre-training,簡單說明一下這四種方法:
Prompt Engineering: 設計有效的提示(prompts)來幫助模型更好地理解問題並生成準確的回應。這些技巧直到今天也不斷在被研究與開發,常見如:
以及一些常見的進階技巧:
RAG (Retrieval-Augmented Generation): 通過從多種資料來源中檢索額外資訊,建立知識庫並使用如向量資料庫(Vector Database,一種專門用於存儲和檢索向量數據的數據庫),提供更準確且符合當前情境的內容做為參考,補足模型的知識盲區。可以透過Embedding Model(將文本轉換為數值向量的模型)將文本轉為向量數值,並儲存到向量資料庫快速相似性檢所,特別適合需要最新或專門知識的情況。
Fine-tuning: 需要準備特定領域或任務的資料集,基於現有的LLM進行微調,並進行模型效能的評估。相較於RAG單純進行檢索,Fine-tuning能夠內化知識,提供更靈活的回答。這種方法使模型能夠學習特定領域知識或特定風格,在特定任務上表現更佳。
Pre-training: 簡單來說就是重頭訓練或接續現有模型來繼續訓練。我們可以準備訓練數據,拿開源的模型來繼續Training;甚至從無到有自己建構一個Foundation Model來訓練也可以,但這通常會比較困難。
但由於本系列主軸在於開發LLM應用,因此training model的部分,相信本屆鐵人賽一定有大大寫出乾貨滿滿的文章,故在此不多做解釋。
這四種方法在成效、成本、時間和效果等都有不同的考量,需要根據實際應用場景的需求和資源來使用,如下圖:
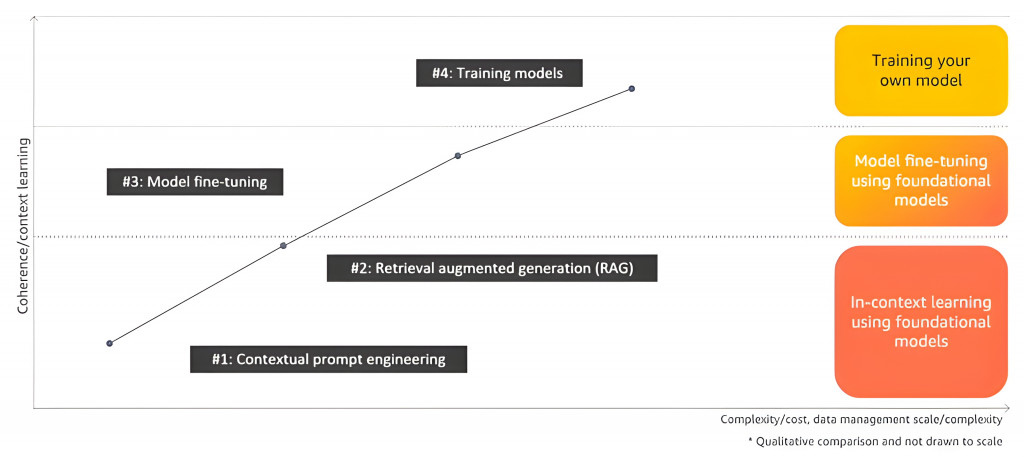
而我們也可以嘗試混合這些方法來讓語言模型達到更好的回應。例如,可以將RAG與Prompt Engineering結合,或在Fine-tuned模型上應用精心設計的prompts,以達到更好的效果。
https://blog.miarec.com/contact-centers-ai-definition
https://cloud.google.com/use-cases/multimodal-ai?hl=en
https://zh.wikipedia.org/zh-tw/自然语言处理
https://blogs.nvidia.com/blog/what-are-foundation-models/
https://aws.amazon.com/tw/what-is/foundation-models/?nc1=h_ls
https://www.cloudskillsboost.google/paths/118/course_templates/539/video/499889?locale=zh_TW
https://aws.amazon.com/tw/what-is/large-language-model/
https://aws.amazon.com/tw/what-is/prompt-engineering/
https://www.oracle.com/tw/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/

