上一章中介紹了量化,它將模型從高精度轉換成低精度,來進行模型壓縮的動作,這一章會繼續介紹其他的模型壓縮方法! 🚀📉

(圖源: DALL·E)
知識蒸餾從傳統NLP的研究中已經被廣泛使用,它是一種透過教師模型(Teacher Model)將知識傳遞給學生模型(Student Model)的方法。
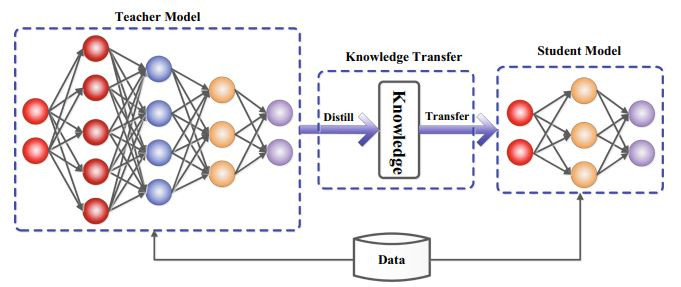
(圖源: 論文 (Gou et al., 2021),這篇是非常經典的KD survey論文)
Teacher Model通常是性能優異的大模型,而Student Model則相對較小,但經過訓練後往往可以表現出和教師模型接近的能力。 🎓➡️🎒
在傳統知識蒸餾中最成功的例子是⚙️ DistilBERT。
它將BERT壓縮了40%,同時保留了97%的語言理解能力,速度還提高了60%。
在LLM相關的KD研究中,主要分為兩種形式:白盒知識蒸餾(White-box KD)和黑盒知識蒸餾(Black-box KD)。
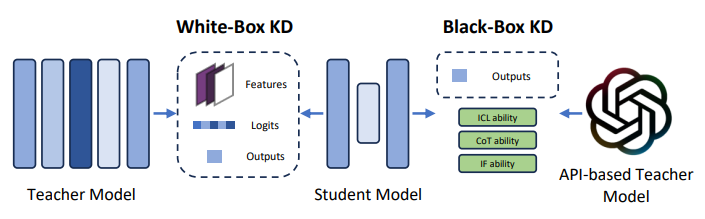
(圖源: 論文 (Zhou et al., 2024))
⚪📦 White-box KD
⚫📦 Black-box KD
李宏毅教授的yt課程有一堂也是在講這個的。
【生成式AI】窮人如何低資源復刻自己的 ChatGPT
剪枝技術也是模型壓縮中非常常見的一種方法,它透過移除「不重要或不必要」的權重和神經元,來減少模型的計算量和儲存需求。
剪枝的策略有多種,主要分成是:
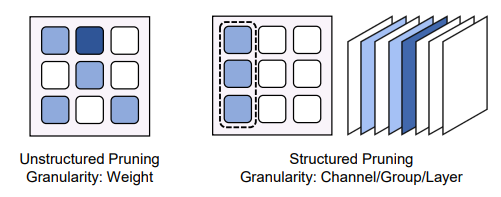
(圖源: 論文 (Zhou et al., 2024))
而剪枝後的模型通常會搭配再訓練來恢復部分性能,這個過程正是fine-tuning。 🔄🔧
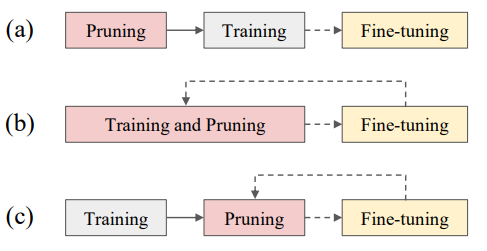
(圖源: 論文 (Wang et al., 2024),三種剪枝的流程)
在上圖這篇survey論文當中提到,雖然剪枝在CNN中可以有明顯的效果,但是跟量化和蒸餾等其他壓縮技術相比,它對於LLM的效果並不穩定 📉。剪枝效果下降的主要原因是在LLM微調過程中模型參數較多造成的計算成本較高,導致難以達到預期的效果。
Nvidia blog對稀疏性有一個比喻,那就是🧱 疊疊樂遊戲,在不毀掉積木塔的前提下抽出最多不必要的積木。
稀疏性就像是數字版本的疊疊樂,研究人員會在神經網路中盡可能的多抽出多餘的參數,同時又不破壞LLM的超高精度。
具體來說,稀疏化是透過讓 模型參數或結構變得更加稀疏(即大多數值為零) 的方式來達到壓縮和加速的效果。稀疏化可以於減少模型的記憶體需求,同時加速模型的推理過程,尤其是在配合專門的硬體時效果更好。 ⚡📊
這邊找了幾個例子:
🔍 Sparse Attention
📜 Longformer
在這個章節,介紹了蒸餾、剪枝、稀疏化這三種模型壓縮的方式,透過這些方式也可以各自減少模型的大小並加快計算速度,不過這三種都包含著一個訓練的過程,對應用來說比較不實用。雖然整體而言偏學術一些,不過也是挺有趣的,就像是在料理模型,可以用各式各樣的方法來料理它的所有部分,而每一種料理方式都各自有非常多細節和變化在其中。 📚🛠️
下一章要來介紹推理加速技術中更快更有趣的 演算法層面最佳化 (Algorithm-level Optimization)!

(圖源: DALL·E)
A Survey on Efficient Inference for Large Language Models
https://arxiv.org/pdf/2404.14294
Model Compression and Efficient Inference for Large Language Models: A Survey
https://arxiv.org/pdf/2402.09748

