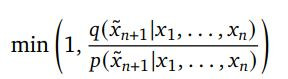這一章將介紹 演算法層面最佳化 (Algorithm-level Optimization) ,這其中最知名的即為Speculative Decoding。 ⚙️✨

(圖源: 自製)
噢不......這章介紹的就是LLM推理加速中的Starburst Stream------Speculative Decoding!它的演算法設計非常厲害,在大量推論需求下減少個20秒可能都不是問題! ⏱️🔥
Speculative decoding是Google和DeepMind幾乎同時發表的技術,主要是用在推理加速的部分,目標是讓LLM可以在一次推理需要的時間內產生更多的tokens。它不一定是專用在LLM上,但是用在LLM中效果超好,大概可以加速2-2.5倍的時間。
下面這部分的內容來自vLLM開發者的介紹,筆者這邊做了一些整理。
🧠💾 memory-boundedness
🧩🔄 不需要所有參數去產生每個token
🔮🤖 試著去預測大型語言模型的想法

(圖源: x,dataset改成question會更適合XD,因為不需要所有參數去產生每個token)
📝🏗️ Draft Construction
✅🔍 Draft Verification
也許大家可能會先去看李宏毅的圖解yt影片,但筆者當時看了只覺得很神奇,有點混亂,反而是看了用公式解說的yt再去看論文+圖解yt比較懂,所以這邊決定放公式講解筆記 🧮🖋️,但如果喜歡看圖片的讀者可以看李宏毅yt影片XD
總之現在有一個較小、速度超快的draft model,和一個比較大的目標模型。
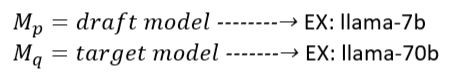
接下來我們選擇一次預測多少tokens K。
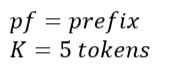
這邊會先超快速地跑autoregressive的draft model K 次,得到 x1~x5。
(按照順序來跑)
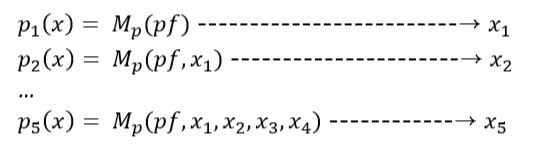
再用draft model產生的 K 個tokens平行計算,各自去跑一回合target model K+1 次。
(平行計算)
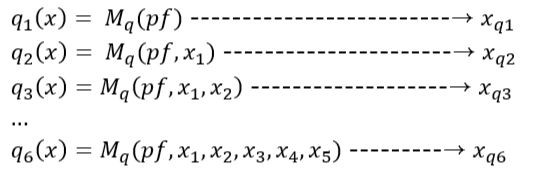
然後在這個過程中,就可以放棄一次只能一個token一個token慢慢產生的autoregressive邏輯,target model可以同時用draft model的 x1、x1 + x2、...、x1 + x2 + x3 + x4 + x5 去平行計算(當然這時算力就跟著增加啦),生成自己下一步的答案,得到第1~6個token正確解答probability distribution,一邊用draft model產生的probability distribution去對答案,並對錯誤的那一個token重新做sample。
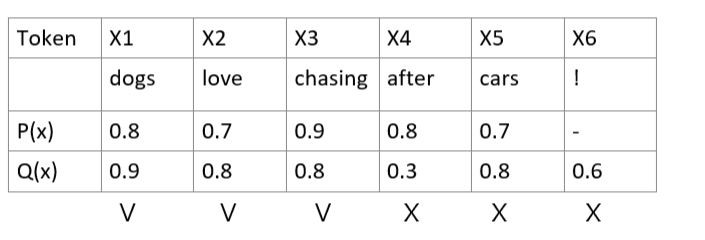
Rejection sampling檢查的規則如下,這是yt影片整理的簡單版本:
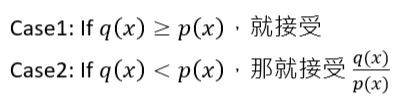
🔍 實際上這邊在論文裡面的描述是:
但如果q(x) >= p(x),則q(x)/p(x) >= 1,所以還是會被接受,可以被簡化成Case 1的公式。因為這一段在那個yt影片中沒有被提到,機率部分也講得不太好懂,筆者這邊搭配論文補充一下。
因為 x3 的0.8/0.9=0.8888是接受的,而 x4 的0.3/0.8=0.375是不接受的,所以 x4 和後面的 x5 就被否決了。(0.8888是會有88.88%的機率接受它,因為這時會從 U[0, 1] 的uniform distribution生成一個隨機數字 r,如果 r 大於0.8888才會拒絕,這邊假設它小於0.8888,x3 被接受,同理假設 x4 被拒絕。)
那這樣 x4 要怎麼辦呢?接下來必須再sample它一次,這次要從target model的 q(x) 去sample,而非draft model。
但嚴格來說不是從 q(x) 去sample,是 (q(x)-p(x))+ 這個範圍。
那一塊範圍代表什麼呢?
回去看兩個條件,Case 1就是右下角的三角形,Case 2是左下角的三角形,在遇到Case 2左下角的三角形時,要從 (q(x)−p(x))+ 去sample,也就是右上角的紅色區塊。

(圖源: yt截圖)
最後也是最重要的是,兩個模型必須要有相同的詞彙表才能做這件事。
雖然剛剛在上面看對答案看起來很久,但其實對答案的時間都只是在原本生成一個token的一回合autoregressive之中的時間而已,所以即使最差的狀態,每一回合也會有1個token可以用,速度不會變慢。
最好的狀態我們可以全部接受5個tokens,還成功產生了第6個token,所以會用生成一個token的時間去得到K+1的tokens,直接賺爛了。 🎊👑💵
Speculative Decoding的想法很簡單,是利用將模型參數載入的算力空白時間,將Memory Bound過渡到Compute Bound,是一個用算力換取時間的方法,當然不一定每個任務和模型都適用,可以依據自己的任務去做調整。而vLLM有支援,使用起來效果超級好的,體驗很棒,再撐一下就要到實作的部分啦。
🔍 最後簡單總結一下:
- 推理更快速 🚀
- GPU算力會因此增加在target model的平行計算上 📈
下一章就往 資料面最佳化 (Data-level Optimization) 最後衝刺了! 🏃💨
Accelerating Large Language Model Decoding with Speculative Sampling (DeepMind)
https://arxiv.org/pdf/2302.01318

(圖源: 網路)