有了前端的工具,那也不能少了能幫助我們讀取並且應用的文字生成工具 text-generation-webui,這專案前端頁面也是使用 Gradio 去建構的
點選Github專案連結後,依自己習慣,用指令 clone 或者下載 zip 都可以
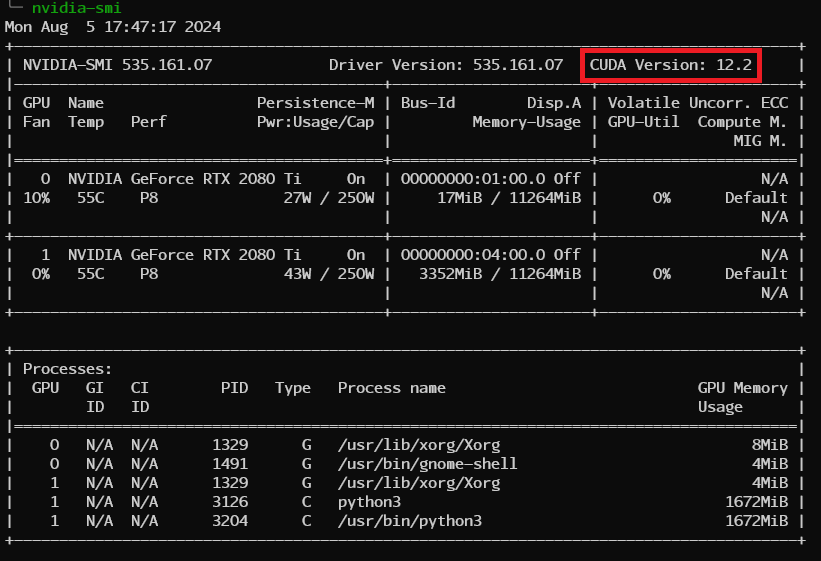
首先先確認自己的 Nvidia 驅動版本
在終端中輸入以下指令並且確認 Cuda 最高支援版本
nvidia-smi
可依自己的作業系統環境,如 Windows 或 Linux 參考官方的安裝文檔,進行操作,
如範例圖所示,上面顯示的版本為 "12.2",那麼 Cuda 的版本盡量不要高於 12.2
export PATH=/usr/local/cuda/bin:$HOME/.local/bin:$HOME/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
透過以下指令確認是否有讀到 Cuda 函式庫
nvcc -V
# output
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
為了不與系統環境混置,在使用此工具時,強烈建議使用虛擬環境
python3 -m venv venv
# Linux
source venv/bin/activate
# Windows
.\venv\Scripts\activate
再來安裝與系統 Cuda 版本,相符的 Pytorch
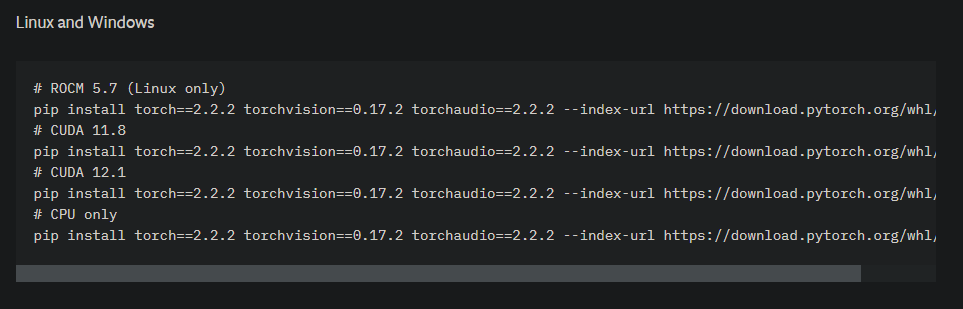
這邊由於官方是以 11.8 和 12.1 的兩個 Cuda 版本去編譯的,所以像我的 Cuda 版本是 12.1,就選擇 12.1 的 Pytorch 版本
所以先安裝完原作者提供的依賴套件後,再另外進行安裝 Pytorch
pip install -r requirements.txt
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
輸入以下指令即可開啟文字生成服務
python server.py --trust-remote-code

打開瀏覽器並且在網址列輸入127.0.0.1:7860,看到以下畫面代表前端已經就緒了
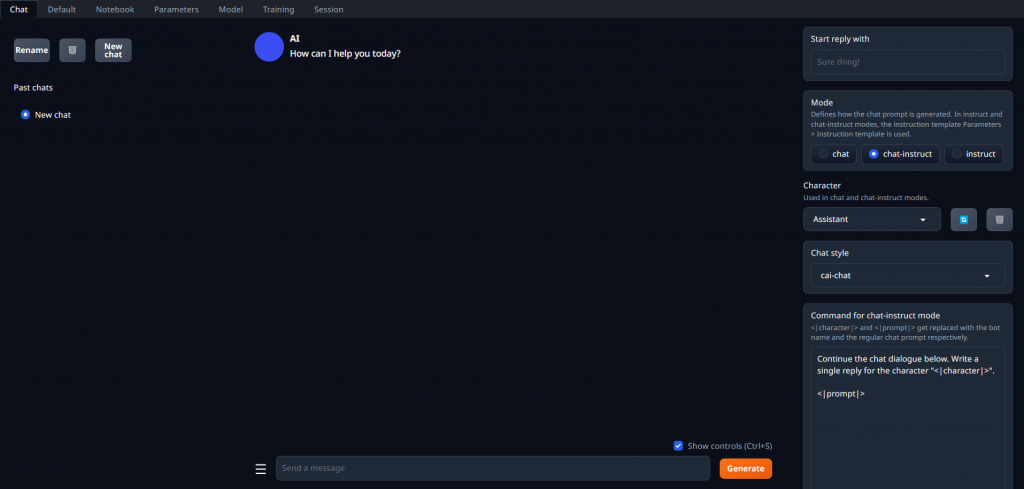
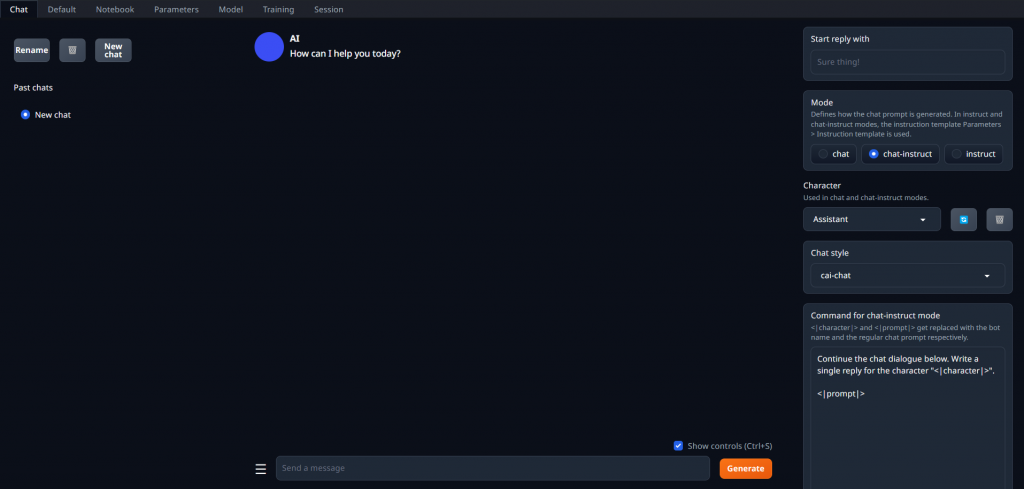
在 "Model" 頁面讀取完模型後,可在此分頁中與模型互動
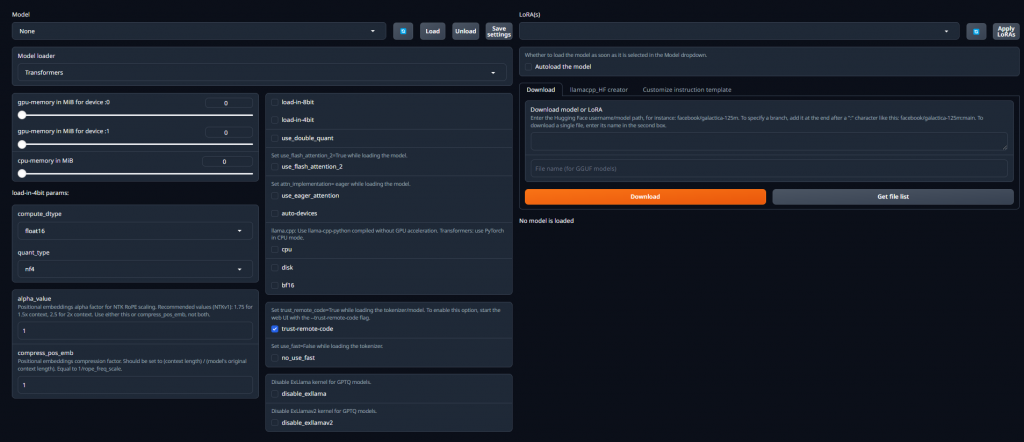
左邊可以在放入欲使用的大型語言模型後,選擇並且讀取它們
右邊則是可以選擇在 "Training" 頁面微調完的 lora 權重檔
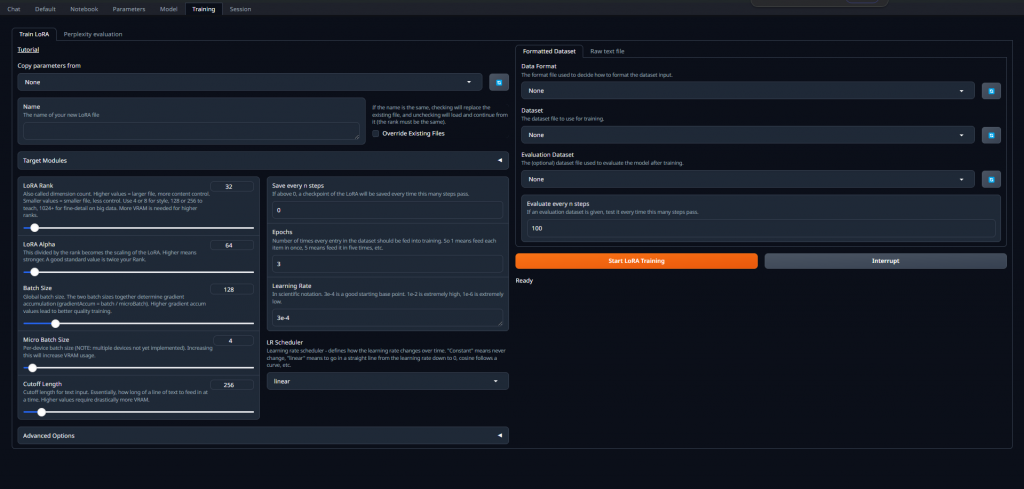
在這邊可以將自己準備好的資料集進行微調,資料格式可參考官方維基
在抱臉上存放了非常大量的模型權重檔,如大家常常聽到的 Llama、Mistral、Gemma 或者 GPT2 等等的,都可以在這個網站上下載
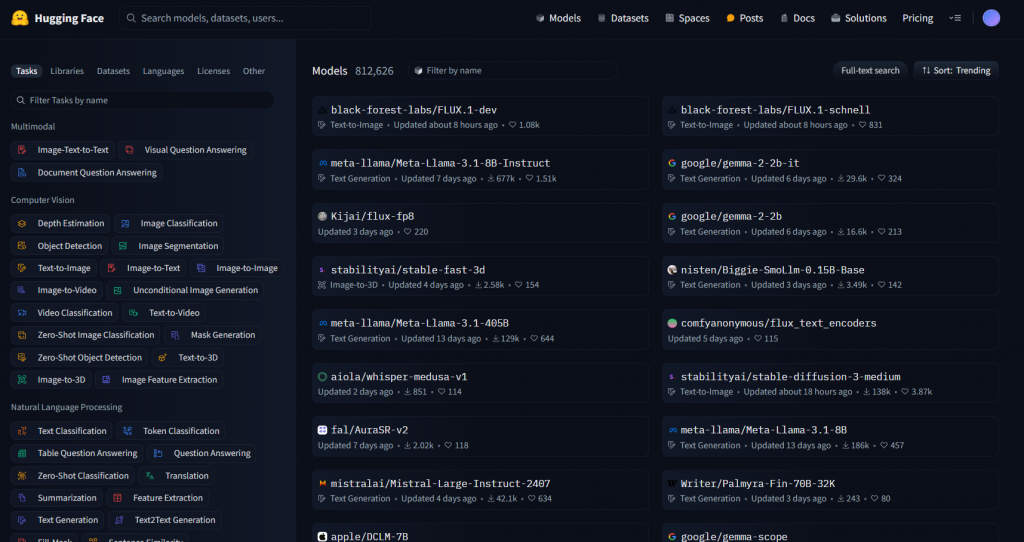
目前是最為推薦 Gemma-2-9b-it 這個語言模型,他是在眾多小型模型裡面,表現相對好的,所以我們要在文字生成工具的 "models" 資料夾底下下載這個模型
Acknowledge license就可以了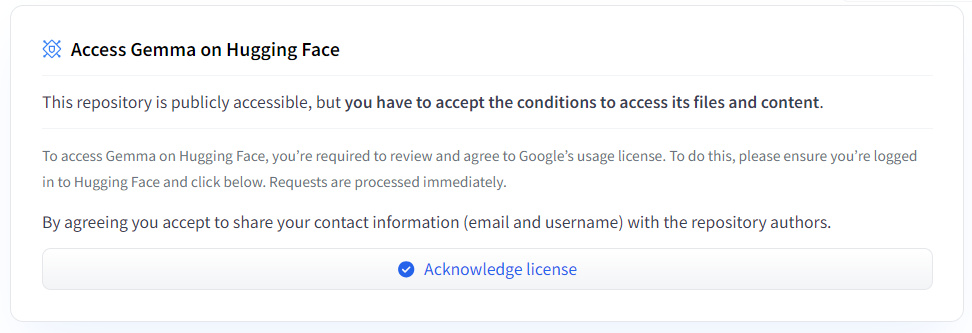
由於像這種大檔案的模型會用 lfs 的形式去儲存,所以我們也需要透過一些步驟去下載這些模型,詳細可參考官網
我們終端環境也需要登入 huggingface
右上角點擊個人頭貼後,點擊Settings
左側點擊Access Tokens後右側點選Create new token
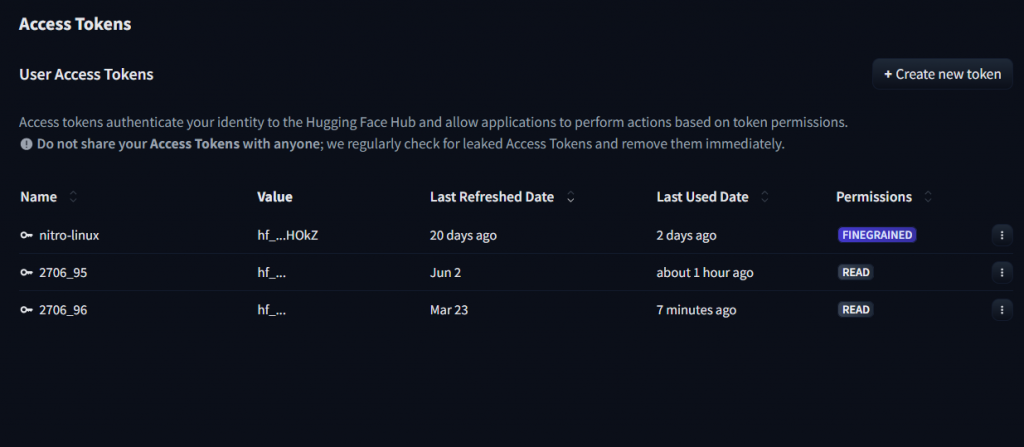
Type 這邊我們選擇 "Read" 名字則是依自己的喜好去取就可以了
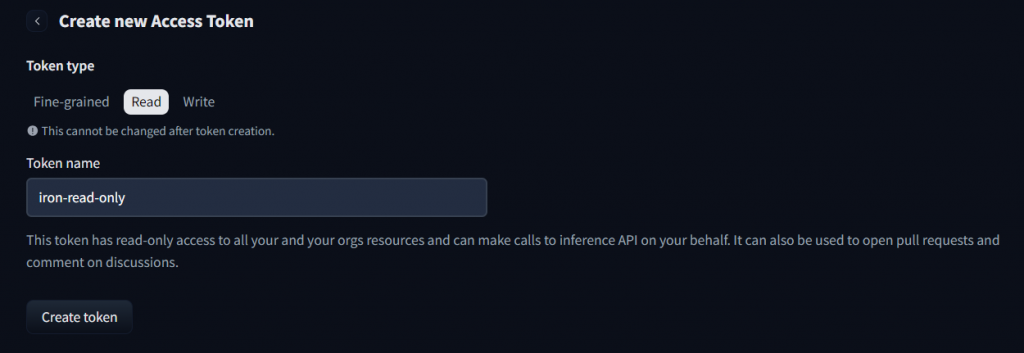
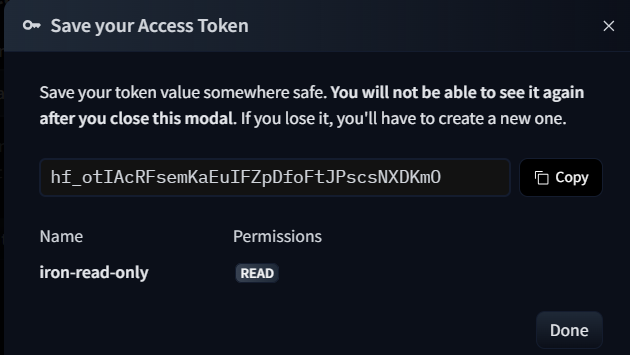
再點選Create token後會彈出一個畫面,這時複製畫面上的 "hf" 開頭的字串
終端的環境我們也要安裝 Python 套件
pip install huggingface-hub
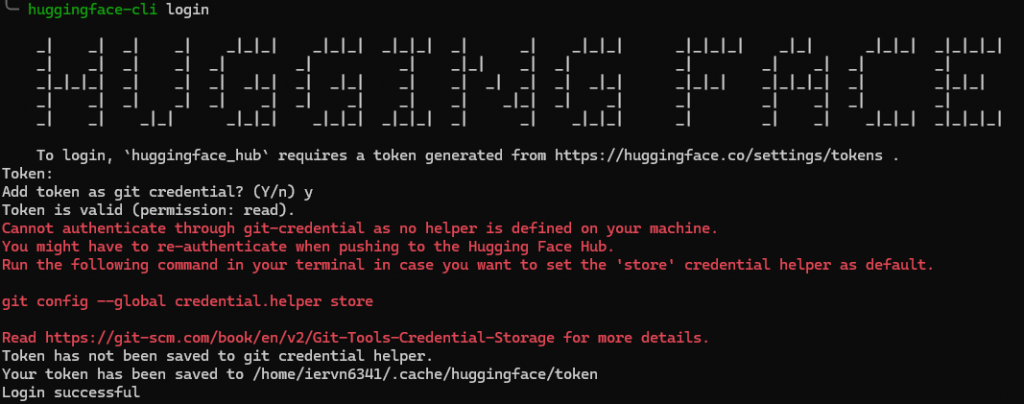
在終端中輸入huggingface-cli login後貼上剛剛複製的 Token 就可以了
切換到指定目錄底下就可以開始 clone 模型了~~
cd text-generation-webui/models
git lfs install
git clone https://huggingface.co/google/gemma-2-9b-it
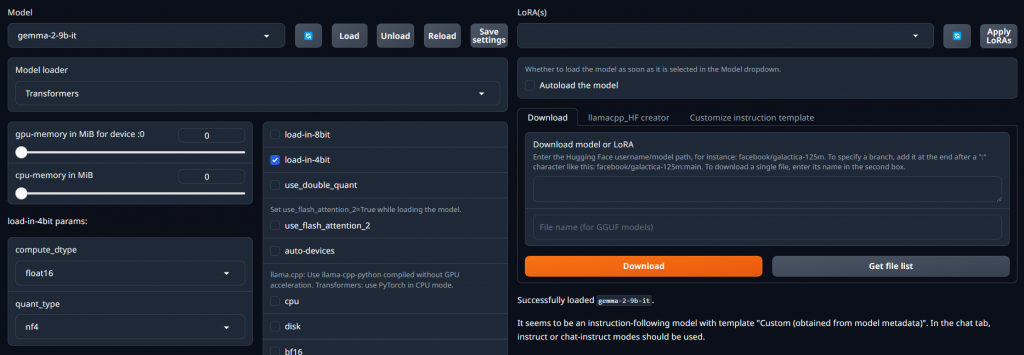
這時回到 Model 的頁面並且選擇 Gemm2-2-9b-it 後勾選load-in-4bit後再點 Load 就可以了
這時回到 Chat 的頁面並且測試問一個問題,有出現結果就可以了

