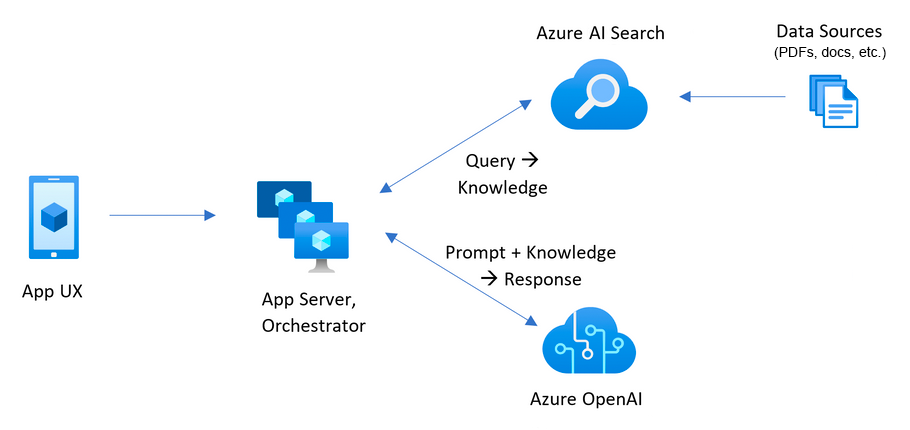
從Day2初次看到這張Azure聊天機器人架構圖,到現在經過了各種層面的認識之後,重新再看一次這張圖大家可能已經有不同的感想了。今天我們就進一步借用論文中更詳細的架構圖,來重新回顧一次具備向量檢索功能的聊天機器人背後的原理吧。
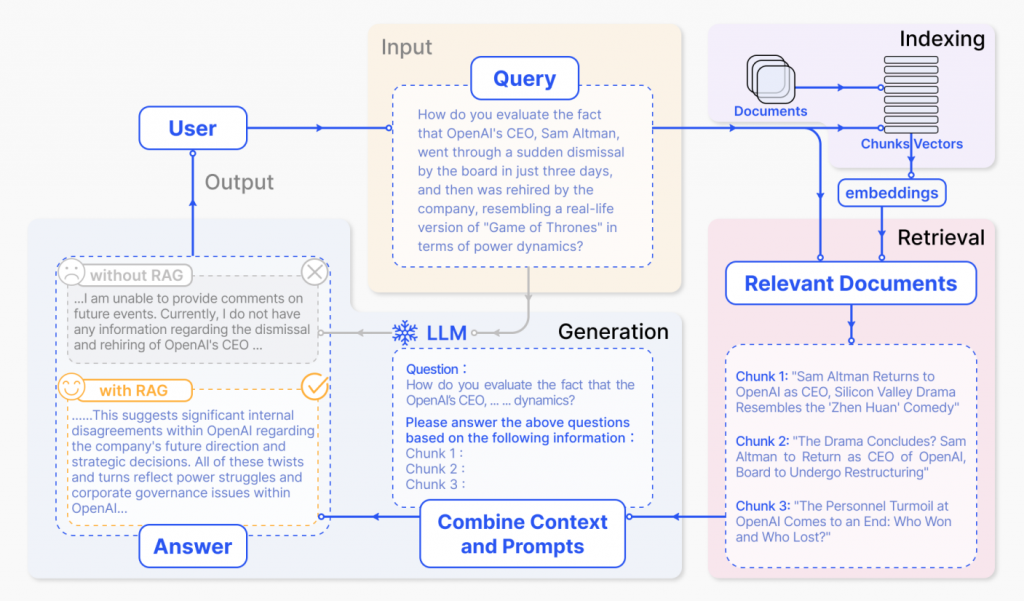
Gao, Yunfan et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” (2023).
使用者輸入一個查詢(Query)或問題,向聊天機器人提問。
事先連結不同的資料來源,將相關文件轉換為向量(embeddings)並儲存於向量資料庫供未來檢索。
當使用者的查詢內容進到系統後,也將其向量化並且拿來檢索向量資料庫內儲存的內容,找到相近的幾個配對結果。
透過LLM(大型語言模型)使用檢索到的內容來生成回覆,結合原本模型的能力加上RAG(檢索增強生成)的加乘,讓機器人有機會回答得更正確、詳細。
經過以上流程,將最終產出結果回傳給使用者,而使用者也能根據得到的輸出內容,再進一步提問下個問題。
回顧了聊天機器人的流程之後,我們明天來做個小結,分享筆者使用Azure聊天機器人的心得吧。
Gao, Yunfan et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” (2023).
azure-search-openai-demo
https://github.com/Azure-Samples/azure-search-openai-demo/#Running%20locally
打造客製化的 Chatbot:從 RAG 到 Langchain Agent 的實作 https://vocus.cc/article/66c5f6a5fd8978000106d3de
今天是周六,筆者坐在電腦前的位置卻是從早上九點到現在接近晚上十二點,幾乎都在認真,雖然有點忙也有點累,但是進入心流的專注狀態真的很很好的體驗。


 iThome鐵人賽
iThome鐵人賽