在客戶端透過API請求中,如果客戶端想要提升查找數據的精確性與效率?
而站在服務端的角度,透過認證與權限的設計來達到提升安全性的效果,那如果用戶的確具備對應的權限與身份,又有哪些方式能防止API被濫用?
又或是想要減輕服務端的壓力,都應該如何更近一步優化我們的API?
我們今天來探討在Django REST framework(DRF)中可以透過哪些方式來進行API的優化:流量限制、過濾與分頁
今日重點:
所謂的限制流量(限流),也就是如果單一客戶端的請求頻率超過了允許的限制,便會給予限制,實務上通常會返回一個429 Too Many Requests響應
而在DRF中,會根據幾種方式來找到API請求的來源,來判定客戶端的請求是否超出限制:
上述提到的DRF提供的限流類別,都是繼承了BaseThrottle ,我們來看一下他是具備什麼方法
class BaseThrottle:
"""
Rate throttling of requests.
"""
def allow_request(self, request, view):
"""
Return `True` if the request should be allowed, `False` otherwise.
"""
raise NotImplementedError('.allow_request() must be overridden')
def get_ident(self, request):
"""
Identify the machine making the request by parsing HTTP_X_FORWARDED_FOR
if present and number of proxies is > 0. If not use all of
HTTP_X_FORWARDED_FOR if it is available, if not use REMOTE_ADDR.
"""
xff = request.META.get('HTTP_X_FORWARDED_FOR')
remote_addr = request.META.get('REMOTE_ADDR')
num_proxies = api_settings.NUM_PROXIES
if num_proxies is not None:
if num_proxies == 0 or xff is None:
return remote_addr
addrs = xff.split(',')
client_addr = addrs[-min(num_proxies, len(addrs))]
return client_addr.strip()
return ''.join(xff.split()) if xff else remote_addr
def wait(self):
"""
Optionally, return a recommended number of seconds to wait before
the next request.
"""
return None
allow_request:決定是否允許請求,因為是抽象方法,在子類別中需要自定義相關邏輯。當我們想要自定義限流時通常會改寫這個方法wait:返回客戶端在下一個請求前應該等待的時間,單位為秒get_ident:默認情況下是去判斷請求的ip位址,並且根據是否有代理伺服器,盡可能準確辨認初始客戶端ip這時候可能會想,那這樣DRF要怎麼記住每一個客戶端的資料?
這時候我們可以看SimpleRateThrottle類別,該類別繼承BaseThrottle,並且被AnonRateThrottle、UserRateThrottle、ScopedRateThrottle所繼承
class SimpleRateThrottle(BaseThrottle):
"""
A simple cache implementation, that only requires `.get_cache_key()`
to be overridden.
The rate (requests / seconds) is set by a `rate` attribute on the Throttle
class. The attribute is a string of the form 'number_of_requests/period'.
Period should be one of: ('s', 'sec', 'm', 'min', 'h', 'hour', 'd', 'day')
Previous request information used for throttling is stored in the cache.
"""
cache = default_cache
timer = time.time
cache_format = 'throttle_%(scope)s_%(ident)s'
scope = None
THROTTLE_RATES = api_settings.DEFAULT_THROTTLE_RATES
def __init__(self):
if not getattr(self, 'rate', None):
self.rate = self.get_rate()
self.num_requests, self.duration = self.parse_rate(self.rate)
def get_cache_key(self, request, view):
"""
Should return a unique cache-key which can be used for throttling.
Must be overridden.
May return `None` if the request should not be throttled.
"""
raise NotImplementedError('.get_cache_key() must be overridden')
def get_rate(self):
"""
Determine the string representation of the allowed request rate.
"""
if not getattr(self, 'scope', None):
msg = ("You must set either `.scope` or `.rate` for '%s' throttle" %
self.__class__.__name__)
raise ImproperlyConfigured(msg)
try:
return self.THROTTLE_RATES[self.scope]
except KeyError:
msg = "No default throttle rate set for '%s' scope" % self.scope
raise ImproperlyConfigured(msg)
def parse_rate(self, rate):
"""
Given the request rate string, return a two tuple of:
<allowed number of requests>, <period of time in seconds>
"""
if rate is None:
return (None, None)
num, period = rate.split('/')
num_requests = int(num)
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]]
return (num_requests, duration)
def allow_request(self, request, view):
"""
Implement the check to see if the request should be throttled.
On success calls `throttle_success`.
On failure calls `throttle_failure`.
"""
if self.rate is None:
return True
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
self.history = self.cache.get(self.key, [])
self.now = self.timer()
# Drop any requests from the history which have now passed the
# throttle duration
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
if len(self.history) >= self.num_requests:
return self.throttle_failure()
return self.throttle_success()
def throttle_success(self):
"""
Inserts the current request's timestamp along with the key
into the cache.
"""
self.history.insert(0, self.now)
self.cache.set(self.key, self.history, self.duration)
return True
def throttle_failure(self):
"""
Called when a request to the API has failed due to throttling.
"""
return False
def wait(self):
"""
Returns the recommended next request time in seconds.
"""
if self.history:
remaining_duration = self.duration - (self.now - self.history[-1])
else:
remaining_duration = self.duration
available_requests = self.num_requests - len(self.history) + 1
if available_requests <= 0:
return None
return remaining_duration / float(available_requests)
cache與cache_format:這就能解釋我們前面的疑問,DRF是透過儲存快取來知道對應的庫戶端的相關資料scope:獲取設置的節流速率THROTTLE_RATES:從DRF設置中獲取的默認節流速率__init__:如果沒設置scope,則透過get_rate方法拿到對應的速率,接著透過parse_rate方法,返回在特定的時間窗口內允許的請求數allow_request:在這個核心的方法中,先把已經不再時間窗口(self.duration)內的紀錄刪除,再來判斷時間窗口內的請求數量是否超標根據上面的方法我們了解到,我們需要先設置默認或是特定視圖中允許請求的頻率,當客戶端發起請求時,根據快取的資料以及設置的請求頻率來決定是否要接受請求。如果超標則不接受,反之則紀錄客戶端資料到快取
現在我們知道基礎的現流實現方式,我們就可以來看各類別的區別
AnonRateThrottle
如果用戶有註冊過則不需進行限流,反之則紀錄客戶端ip
class AnonRateThrottle(SimpleRateThrottle):
"""
Limits the rate of API calls that may be made by a anonymous users.
The IP address of the request will be used as the unique cache key.
"""
scope = 'anon'
def get_cache_key(self, request, view):
if request.user and request.user.is_authenticated:
return None # Only throttle unauthenticated requests.
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
UserRateThrottle
如果是註冊的用戶,使用用戶id當作快取的key,反之則紀錄ip位址
class UserRateThrottle(SimpleRateThrottle):
"""
Limits the rate of API calls that may be made by a given user.
The user id will be used as a unique cache key if the user is
authenticated. For anonymous requests, the IP address of the request will
be used.
"""
scope = 'user'
def get_cache_key(self, request, view):
if request.user and request.user.is_authenticated:
ident = request.user.pk
else:
ident = self.get_ident(request)
return self.cache_format % {
'scope': self.scope,
'ident': ident
}
ScopedRateThrottle
比較不一樣的地方是,在初始化時不會去判斷限流頻率,而是在調用視圖時才進行紀錄,並且紀錄方式與UserRateThrottle相同
class ScopedRateThrottle(SimpleRateThrottle):
"""
Limits the rate of API calls by different amounts for various parts of
the API. Any view that has the `throttle_scope` property set will be
throttled. The unique cache key will be generated by concatenating the
user id of the request, and the scope of the view being accessed.
"""
scope_attr = 'throttle_scope'
def __init__(self):
# Override the usual SimpleRateThrottle, because we can't determine
# the rate until called by the view.
pass
def allow_request(self, request, view):
# We can only determine the scope once we're called by the view.
self.scope = getattr(view, self.scope_attr, None)
# If a view does not have a `throttle_scope` always allow the request
if not self.scope:
return True
# Determine the allowed request rate as we normally would during
# the `__init__` call.
self.rate = self.get_rate()
self.num_requests, self.duration = self.parse_rate(self.rate)
# We can now proceed as normal.
return super().allow_request(request, view)
def get_cache_key(self, request, view):
"""
If `view.throttle_scope` is not set, don't apply this throttle.
Otherwise generate the unique cache key by concatenating the user id
with the `.throttle_scope` property of the view.
"""
if request.user and request.user.is_authenticated:
ident = request.user.pk
else:
ident = self.get_ident(request)
return self.cache_format % {
'scope': self.scope,
'ident': ident
}
如果要設置限流,可以直接在settings.py中配置全局變數,設置想要配置的限流類別與頻率
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': [
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle',
],
'DEFAULT_THROTTLE_RATES': {
'anon': '2/min',
'user': '10/min'
}
}
在視圖中便可以直接調用
from rest_framework.throttling import UserRateThrottle
class WorkspaceViewSet(viewsets.ModelViewSet):
throttle_classes = [UserRateThrottle]
那如果我們想要修改全局的頻率,可以新建throttles.py在app目錄下
from rest_framework.throttling import UserRateThrottle, ScopedRateThrottle
class WorkspaceThrottle(UserRateThrottle):
THROTTLE_RATES = {"user": "5/day"}
# 如果是要配置scope的話,可以這樣寫
class DocumentThrottle(ScopedRateThrottle):
THROTTLE_RATES = {"document": "10/day"}
最後在視圖中調用即可
分頁在API中扮演重要的角色:
在DRF中有幾種類
使用的方法可以全局設定
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 10
}
或是自定義類別來修改參數
from rest_framework.pagination import LimitOffsetPagination
class CustomPagination(LimitOffsetPagination):
default_limit = 10
max_limit = 100
class WorkspaceViewSet(viewsets.ModelViewSet):
pagination_class = CustomPagination
而請求時則是直接調用想要的資料範圍
http://127.0.0.1:8000/note/workspaces/?page=1 # PageNumberPagination
http://127.0.0.1:8000/note/workspaces/?limit=1&offset=0 # LimitOffsetPagination
實現過濾的功能,在API請求時也相當重要,除了提高效率之外,也能改善用戶體驗,使客戶端能快速找到所需的資訊。同時能夠直接在調用API時根據特定欄位來進行排序,也能進一步提升客戶端體驗
如果使用DRF原生方法進行過濾,可以分成視圖函式與視圖類別:
self.request.query_params.get() 拿到客戶端的查詢關鍵字參數get_queryset方法,在Django REST framework: 視圖的進化之旅 - GenericAPI 到 ViewSet,從通用基礎到高層抽象中已經有提及過,這邊就不再贅述此外DRF還提供了不同的API來快速使用過濾功能
from rest_framework import filters
class DocumentViewSet(viewsets.ModelViewSet):
queryset = Document.objects.all()
serializer_class = DocumentSerializer
permission_classes = [permissions.IsAuthenticated]
filter_backends = [filters.SearchFilter]
search_fields = ["title", "content"]
filter_backends屬性為filters.SearchFilter
search_fields中通常我們會選擇具備text type的欄位進行搜尋# 來源於官方文檔
search_fields = ['data__breed', 'data__owner__other_pets__0__name']
當我們在視圖中配置filter時,我們就能透過路由來對特定來為進行搜尋
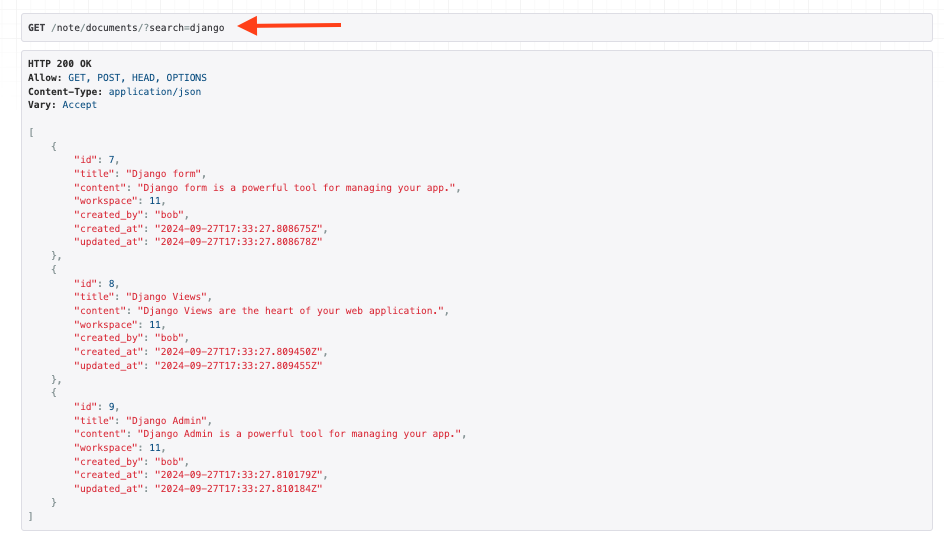
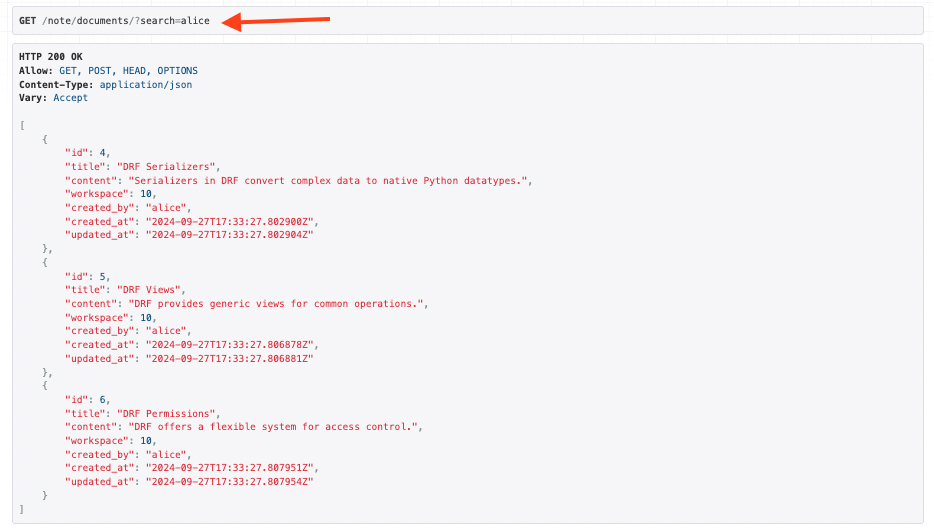
此外我們也能根據外鍵或是多對多的欄位進行搜索,例如以我們的Document model來說,我們也能透過workspace欄位拿到owner的名稱
class DocumentViewSet(viewsets.ModelViewSet):
queryset = Document.objects.all()
serializer_class = DocumentSerializer
permission_classes = [permissions.IsAuthenticated]
filter_backends = [filters.SearchFilter]
search_fields = ["workspace__owner__username"]# 透過雙底線來解構
而在排序方面,DRF則是提供OrderingFilter類別快速設定排序功能
class DocumentViewSet(viewsets.ModelViewSet):
queryset = Document.objects.all()
serializer_class = DocumentSerializer
permission_classes = [permissions.IsAuthenticated]
filter_backends = [filters.SearchFilter, filters.OrderingFilter] # 一起配置不衝突
search_fields = ["workspace__owner__username"]
ordering_fields = ["created_at", "updated_at", "id"] # 設定想要排序的欄位
路由配置
# 正冪排序
http://127.0.0.1:8000/note/documents/?ordering=created_at
# 降冪排序
http://127.0.0.1:8000/note/documents/?ordering=-created_at
# 多個欄位排序時,可以根據順序
http://127.0.0.1:8000/note/documents/?ordering=-id,created_at
在這個章節中,我們針對提升API效能、客戶端體驗與減輕服務端壓力來進行介紹
除了認證與權限之外,透不不同方式的限流也能避免API被濫用
此外提供分頁與過濾的功能,也能避免傳遞過多不必要的資料,讓客戶端能夠更精準的取得所需的資料範圍

