
前言
我們在先前的章節中已經探討了非常多關於 Grafana IaC 的實踐與應用,包括了如何使用 Grafana IaC 來管理 Grafana 的資源,以及如何使用 Grafana IaC 來管理 Grafana 的告警規則。而現在我們將會進入一個全新的章節,來探討如何在團隊中建立一個告警事件中心。告警管理這個議題一直是許多團隊在維運過程中的一大痛點,而大多無法找到一個有效的解決方案,在這個議題中確實沒有特效藥般的解決方案,但我們仍然可以透過對告警事件管理的深入理解,來找到一個能幫助到自己團隊的解決方案。
常見的告警事件管理痛點
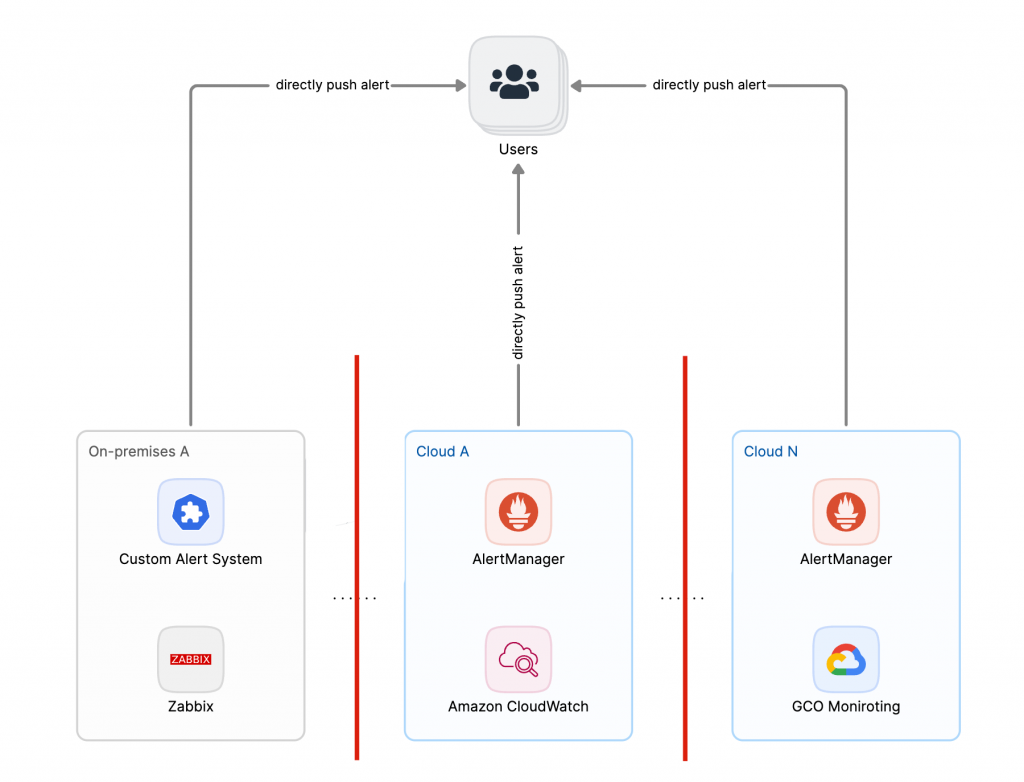
多雲、混合雲架構下的告警系統不一致
在現今的多雲和混合雲架構下,告警系統的不一致性成為了一個普遍的問題。不同的雲服務提供商有各自的告警系統和標準,這導致了在多雲環境中管理告警事件變得極為複雜。團隊需要花費大量的時間和精力來適應和整合這些不同的系統,這不僅增加了工作負擔,也提高了出錯的風險。當告警事件發生時,團隊可能需要在多個平台之間切換,這樣不僅延誤了問題的解決,也可能導致重要的告警被忽略。
自製監控告警系統的訊息孤島
此外,許多團隊選擇自製監控告警系統,以滿足特定的需求。然而,這些自製系統往往缺乏與其他商業監控工具的整合能力。這意味著,當告警事件發生時,這些自製系統無法與其他系統協同工作,導致訊息孤島的出現。團隊成員需要手動整合來自不同系統的數據,這不僅耗時費力,也容易出現錯誤。更糟糕的是,這些自製系統通常缺乏完善的維護和更新,隨著時間的推移,可能會變得越來越難以使用和管理。
簡單來說,多雲和混合雲架構下的告警系統不一致性,以及自製監控告警系統無法整合,都是現代告警事件管理中團隊常見且棘手的痛點。這些問題不僅影響了團隊的工作效率,也對整體的運營穩定性構成了威脅。
告警事件規模大且無效雜訊過多
在告警事件管理中,無效告警事件的雜訊多且未壓縮是一個常見的問題。這些無效告警事件不僅浪費了團隊的時間,也增加了團隊的壓力。例如,一些告警事件可能會重複發生,而一些告警事件可能會被誤報。這些無效告警事件不僅浪費了團隊的時間,也增加了團隊的壓力。
隨著監控系統的增多,當業務系統出現故障時,所有各個層級的監控系統通常會同時爆發大量的告警資訊,導致我們忽略了核心關鍵訊息。且在告警處理中,告警事件通常沒有被妥善的收斂和壓縮。因此,實現告警收斂來降低告警事件規模對於維運人員的處理反應效率顯得格外重要。
告警事件通知策略不成熟
常常告警事件發生後,無法通知到真正需要處理告警事件的角色或無法針對告警優先等級進行通知。而是否建立了 7X24 的值班制度來避免告警事件空窗期,確保 SLA 的高度穩定,也是告警事件管理中的一大挑戰。
實務上告警事件管理的挑戰
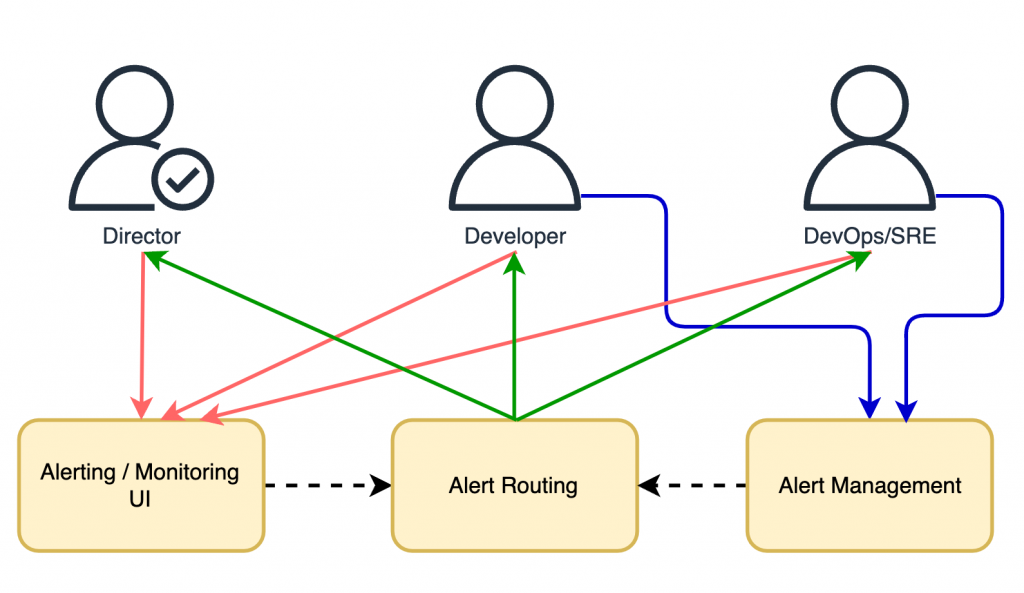
如同先前章節提到的,告警建設面臨著諸多挑戰,我們可以羅列出實務場景中每個角色所面對的痛點與期望來進行初步探討:
- 技術主管:
- 痛點:
- 監控系統過多,告警事件散落在各個系統中,難以查找和定位問題。
- 告警事件的處理過程無法追蹤,且經驗無法沉澱。
- 期望:
- 能有一個「集中式的告警管理系統」,能夠集中管理所有監控系統的告警事件,並能夠快速定位和解決問題。
- 告警事件的處理過程能夠被追蹤,並且經驗能夠被沉澱。
- 一二線值班工程師(DevOps、SRE、SOC):
- 痛點:
- 告警事件雜訊過多,導致告警事件的處理效率低。
- 無法通知到真正需要處理告警事件的角色,造成其他角色的心理負擔。
- 常規的告警處理手冊無法完善覆蓋所有可能的告警事件。
- 不同監控系統的告警內容格式不一,需要頻繁查詢上下文線索。
- 期望:
- 多種即時的通知方式,找到真正需要處理告警事件的角色,並且能夠快速定位和解決問題。
- 告警中自動化豐富上下文線索,輔助快速定位問題。
- 強大的告警降噪機制,減少不必要的告警疲勞負擔。
- 開發工程師:
- 痛點:
- 對於各自團隊的告警事件,無法正確的通知到正確的開發團隊管道。
- 告警事件記錄難以查詢,缺乏有效的查看介面。
- 期望:
- 妥善的告警事件通知鏈路,能夠自動化通知到正確的開發團隊管道。
- 友善的告警事件介面,能夠快速了解告警事件的詳細資訊。
主要有以下幾個方面:
- 透過人工設置固定閾值,各系統設置標準不一,存在大量重複、誤導告警,進而導致告警疲勞。
- 缺乏全局視圖直觀了解應用系統告警整體情況和關聯影響範圍,難以快速定位問題。
- 告警散落在各個監控系統中,導致查找告警原因,定位問題困難,浪費大量時間和資源。
- 告警處理人工干預過多,系統聯動少,告警流轉慢,降低了告警處理效率。
- 告警過程無法追踪,告警處理經驗難以沉澱,告警處理效率低,難以持續改善告警管理。
在介紹如何建設系統之前,我們先來介紹什麼是告警事件生命週期,這樣才能更有針對性的去做告警管理建設。
告警事件生命週期
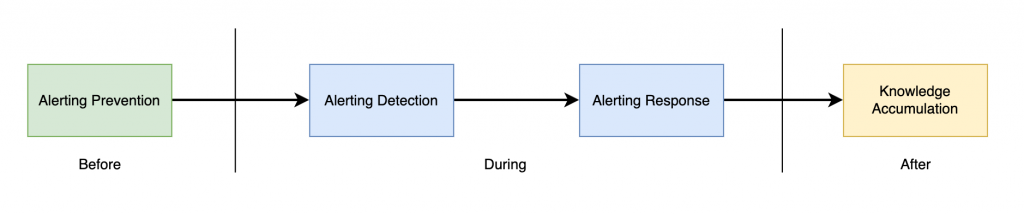
告警事件的生命周期可以簡略的分為三個階段:事前、事中和事後。
- 事前階段:主要著重於預防告警事件的發生
- 告警預防:透過監控系統與各種告警規則設定,來預防告警事件的發生。
- 事中階段:快速發現和解決問題,快速恢復業務運作。
- 告警偵測:透過告警偵測機制,來快速發現和解決問題,確保業務的連續性,並降低可能的損失。
- 告警響應:透過告警響應流程的設定,來快速通知到真正需要處理告警事件的角色,並且能夠快速定位和解決問題。
- 事後階段:追蹤並解決引發告警的根本問題,從而優化告警處理的效率。
- 告警分析:透過告警分析機制,來追蹤並解決引發告警的根本問題,從而優化告警處理的效率。
- 告警知識沉澱:透過告警知識沉澱機制,來將告警處理的經驗沉澱下來,以便於日後的告警處理。
而當我們了解了完整的告警事件生命週期後,我們可以看出告警事件每個階段都與環環相扣,其中包含個整個預防、處理、改善的過程,缺一不可。這也意味著在實務上,告警事件管理不僅僅是單一事件或過程而已,而是可以形成一種持續改善的良性循環。
告警事件管理成熟度模型
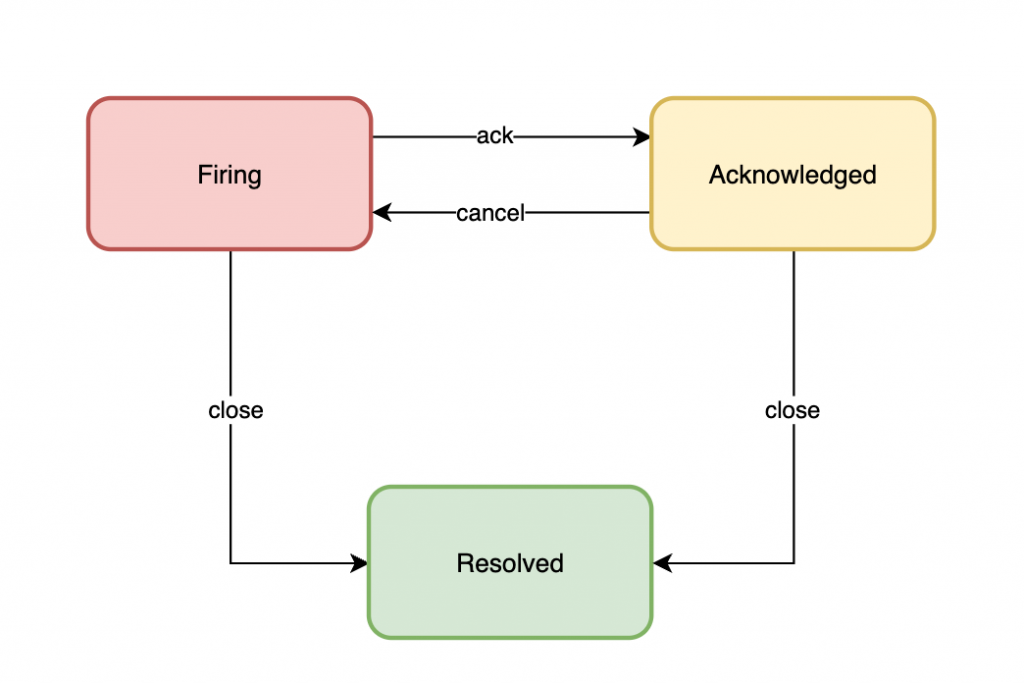
所以在告警事件管理領域中,我們也能透過是否實踐了告警生命週期閉環,來衡量一個團隊的告警管理成熟度:
一個典型的告警成熟度模型可以分為以下五個等級:
- Level 0:監控能力薄弱,主要仍然依賴手動監控,也就是說常常人工發現問題時,才臨時進入服務中搶修,缺乏有效的告警基礎建設。
- Level 1:告警分散管理,試著開始建立一些告警規則,但是缺乏有效的告警事件管理經驗,告警來源仍然散落在各個監控系統中,難以查找和定位問題。
- Level 2:告警統一管理,開始建立一些告警事件管理流程,並且開始將告警事件進行分類,並且開始建立一些告警事件管理的指標,來衡量告警事件管理的效率。
- Level 3:告警自動化管理,漸漸形成告警事件管理體系,引進自動化腳本和事件響應流程,來提升告警事件管理的效率、減少無效告警事件。
- Level 4:告警根因定位自癒,已經能夠針對事件根因進行有效告警,並且結合長久以來的知識沈澱建立一套完善的告警事件管理體系,對於系統故障恢復已經有了自動化自癒能力,並且能夠持續改善告警管理效率。
告警管理的關鍵衡量指標
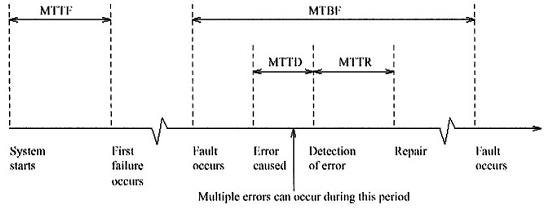
通常情況下,我們會使用以下幾個指標來衡量告警管理的效率:
- MTTR(Mean Time to Repair,平均修復時間):MTTR 表示從系統故障發生到完全修復的平均時間。它反映了團隊修復問題的效率。
- 用途:這個指標用於衡量故障解決的速度,對於維持系統正常運行至關重要。MTTR 越短,說明修復速度越快,系統的可靠性越高。
- 計算方法:MTTR = 所有修復時間的總和 / 修復次數。
- 例子:如果一個系統在一年內發生了 5 次故障,修復時間分別是 2 小時、1 小時、3 小時、1.5 小時和 2 小時,那麼 MTTR = (2 + 1 + 3 + 1.5 + 2) / 5 = 1.9 小時。
- MTTF(Mean Time to Failure,平均故障時間)
- 定義:MTTF 是指在設備或系統出現第一次故障之前的平均運行時間,通常適用於不可修復的系統或元件(例如一次性硬件)。
- 用途:用於衡量設備在初次故障之前的預期壽命,適用於一次性使用或無法修復的設備。
- 計算方法:MTTF = 系統或設備的總運行時間 / 發生故障的設備數量。
- 例子:如果一個硬盤總共運行了 10,000 小時,並且在這段時間內 5 個硬盤發生故障,那麼 MTTF = 10,000 / 5 = 2,000 小時。
- MTBF(Mean Time Between Failures,平均故障間隔時間)
- 定義:MTBF 表示兩次連續故障之間的平均運行時間。與 MTTF 不同,MTBF 適用於可修復的系統,並且反映了設備在每次修復之後能夠穩定運行的時間長度。
- 用途:這個指標主要用於衡量系統的可靠性。MTBF 越長,說明系統或設備的可靠性越高。
- 計算方法:MTBF = 總運行時間 / 故障次數。
- 例子:如果一個系統在 1,000 小時內發生了 2 次故障,那麼 MTBF = 1,000 / 2 = 500 小時。
- MTTD(Mean Time to Detect,平均檢測時間)
- 定義:MTTD 表示從問題發生到被檢測到的平均時間。它反映了系統或團隊識別問題的能力。
- 用途:MTTD 用於衡量問題發生後被檢測的速度,這對於快速響應和修復至關重要。MTTD 越短,代表問題被發現得越早,可以更快地進行處理。
- 計算方法:MTTD = 檢測時間的總和 / 檢測事件的次數。
- 例子:如果三個問題的檢測時間分別是 10 分鐘、15 分鐘和 5 分鐘,那麼 MTTD = (10 + 15 + 5) / 3 = 10 分鐘。
告警事件管理的根本目的就是降低 MTTR、MTTF、MTTD,提高 MTBF,即快速發現問題、快速解決問題、快速恢復業務運作,提升業務連續性。
結論
告警管理是現代 IT 運維中不可或缺的一部分,它不僅是維護系統穩定運行的關鍵,也是提升整體運維效率的重要手段。透過對告警事件生命週期的深入理解,以及對告警管理成熟度模型的探討,我們可以更有效地進行告警管理,提升系統的可靠性,並持續改善運維效率。
告警管理不僅僅是技術問題,更是管理與文化的結合。透過建立一套完善的告警管理體系,我們可以提升團隊的應變能力,減少故障帶來的損失,並最終實現系統的持續穩定運行。

