
現今的市面上已經擁有眾多的的監控系統,如 Prometheus、Grafana、Zabbix、Datadog、New Relic 等等,這些監控系統各自有著不同的告警通知方式,如 Email、Slack、WeChat、Telegram 等等,這些不同的告警通知方式,往往會讓使用者感到困惑,不知道該如何是好。加上大部分的團隊都會不只使用一種監控系統,如地端或網路硬體設備可能會採用 Zabbix 作為監控系統。而 Kubernetes 叢集可能會是採用 Prometheus、Grafana 作為解決方案,並且實施在多個環境當中。
在這些前提之下,告警事件的生命週期就會變得更加複雜,導致即使已經實施相關告警,仍然會有許多問題無法如預期般解決。而本章節將會探討那些在告警事件處理中的最佳實踐。
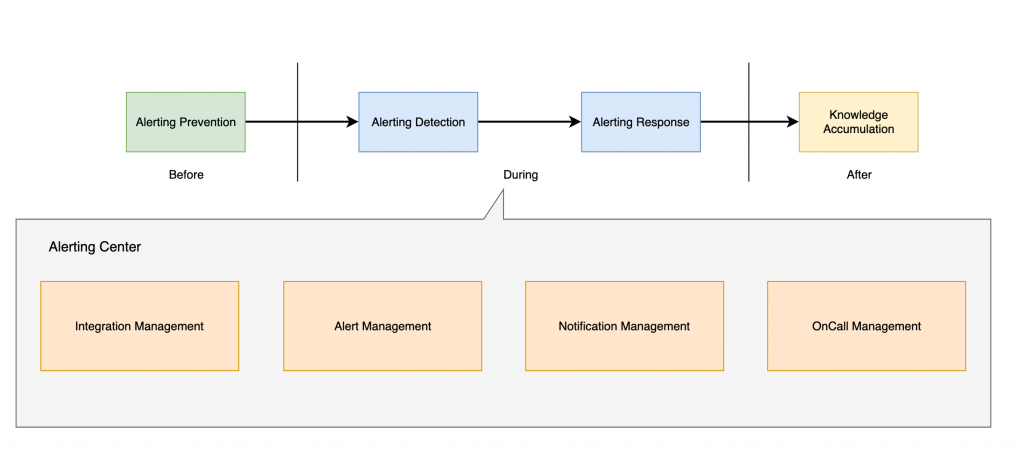
在前面的章節中,我們已經介紹了告警生命週期所包含的事前、事中、事後三個階段,而告警事件中心主要著重在事中階段的處理,接下來我們將以這裡為核心作為基礎,來介紹告警事件中心的功能架構。
一個好的告警事件中心,首先需要能夠整合來自各種不同監控系統的告警事件,並且能夠將這些告警事件進行有效的組織,實現統一且中心化的管理。必須對於對於主流商業監控系統或開源系統的告警通知方式有著良好的支援,才能夠讓使用者無需為了告警通知方式的問題而煩惱。且保留 Webhook 的機制,讓使用者可以自行擴充告警通知方式,實現更彈性的告警通知。
告警事件管理著重在於告警事件的處理,包含告警事件的接收、過濾、分類、優先級調整、轉發、抑制、重複等處理,這部份是有效減少告警風暴的關鍵。不僅如此,告警事件管理還支援編排基礎的處理流程,對於告警事件進行再加工,實現豐富告警事件上下文的目的。
告警通知策略管理掌管著告警事件的路由方式,無論是分派到多個團隊、多個人員、多個系統,甚至是多個通知方式,都可以在這邊進行管理。好的告警通知可以以多種管道發送,如 手機簡訊、Email、Slack、Telegram 等等,而不僅限於傳統的 Email 通知方式。且包含了通知的策略設定,如每小時 1 次、每日 1 次、每週 1 次等,甚至是更細緻的控制,如每 30 分鐘 1 次、每 15 分鐘 1 次等,都可以在這邊進行管理。
告警輪值管理主要著重在於告警事件的輪值機制,包含告警事件的輪值排班、輪值人員的通知、輪值人員的職責等,這部份是有效減少告警疲勞的關鍵。當我們在排班時,可以根據不同的班別(如白班、夜班、假日班),來決定不同的輪值人員,並且在不同的時間點,通知不同的輪值人員,來減少告警無差別轟炸的問題。而告警如果無法由第一線值班人員解決時,可以透過各種升級策略,將告警事件升級到下一個層級的輪值人員,來解決問題。
簡單來說,擁有一個好的告警事件中心,可以讓我們的告警事件處理更加順暢,減少告警風暴的問題,並且讓告警事件的通知更加及時、準確,形成一個顧及維運人員身心健康的良性循環。
告警事件的事中階段,簡單來說包含了告警的抑制、收斂聚合、降噪、分級路由、值班人員管理等等,來達成最有效率的告警閉環處理。看起來觀念非常繁雜,但實際上我們最核心的痛點只有兩個:
接下來就來探討些告警事件的最佳實踐
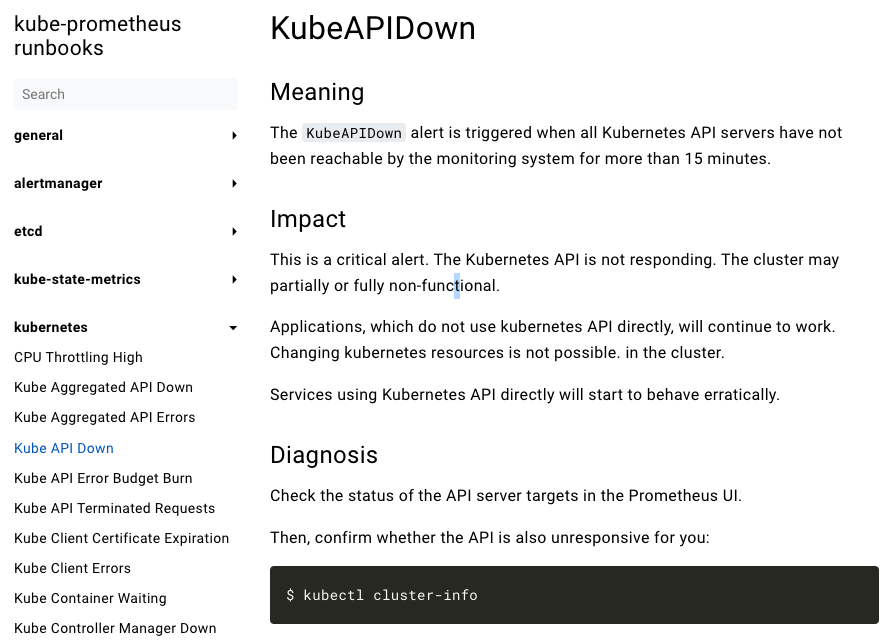
Runbook 可以理解成是告警事件處理的操作文件,當告警事件發生時,可以根據 Runbook 的步驟來進行處理。一個好的告警規則應該是 Actionable 的,也就是說,當告警事件發生時,可以根據 Runbook 的步驟來進行處理,而不需要額外的溝通成本。如此一來,即使是非維運人員,也可以快速解決問題。
但實際上真的要實踐時,會發現到要為每個告警規則都撰寫對應的 Runbook 是一件非常困難的事情,尤其是當告警規則非常多時,更是難以管理。對於如何有效實施 Runbook 文化的制度,可以劃分產品及服務的去建立一個 Runbook 覆蓋率指標,這將使團隊找到一個平衡點,並且持續的進行 Runbook 的撰寫。
Note: 以下為 Kubernetes Mixin 推薦的 Runbook 模板: https://github.com/SkeltonThatcher/run-book-template
對於有些不這麼緊急的告警,當初只想做為某個事件觸發的通知而已,難以收斂成一個對應的 Runbook。而我們可以針對不需要採取行動的告警規則,最少需要調整告警閾值或開立低級別工單紀錄處理,避免造成告警疲勞。而對於僅當作事件通知的告警規則,最好將其發送到一個獨立群組,每天依需求定時查看就足夠。
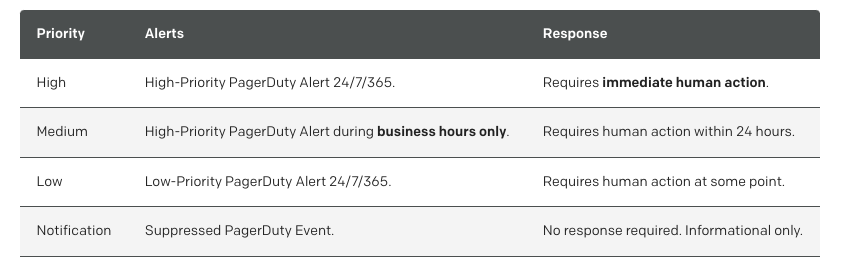
為每個告警規則建立合理的分級制度是提升告警管理效率的關鍵。透過分級,團隊能夠根據告警的嚴重性和影響範圍,快速識別和優先處理最重要的問題。這不僅有助於減少告警疲勞,還能確保關鍵事件不會被忽視。
合理的分級制度能夠促進團隊之間的協作,讓不同職能的成員清楚了解各自的責任和處理流程。當告警被正確分級後,相關人員可以根據其優先級迅速做出反應,從而縮短問題解決的時間。此外,這樣的制度還能幫助團隊在事後進行回顧和分析,持續改進告警管理流程,提升整體效率。
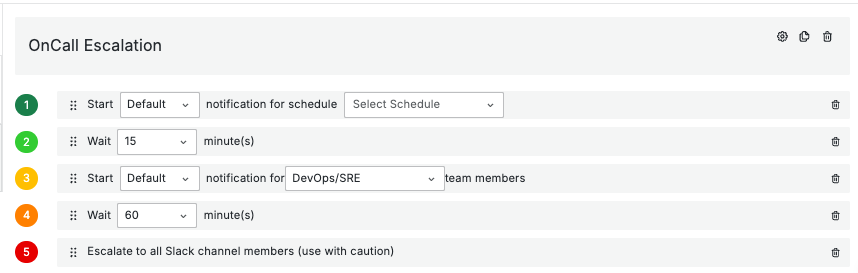
建立輪值制度與告警升級鏈是有效減少告警疲勞的關鍵。透過輪值制度,團隊成員可以根據其職責和能力,快速識別和優先處理最重要的問題。這不僅有助於減少告警疲勞,還能確保關鍵事件不會被忽視。
聽起來不是非常高大尚,但實際在輪班的人員,往往在值班期間會拿出原本 120% 的專注力在處理突發事件,讓其他非值班人原則可以心無旁騖的專注於非緊急任務,如此一來也顧及到了非值班人員的身心健康。
而告警輪值系統的建立,通常也實現了告警升級鏈的機制,使一線值班人員沒辦法馬上回復的告警,可以透過告警升級鏈的機制,將告警事件升級到二線輪值人員,來解決問題。如圖中我們可以看到,告警事件會先指派給一線值班人員,如果沒有收到應答,則會升級到二線值班人員,最終將會發送到 Slack 大群中,讓所有人都知道事態嚴重性。或者是也能看出是否過程中是否有值班人員失聯,而需要進行下一步的處理。
通常告警事件系統會有收斂和壓縮機制,來減少告警事件的數量。如 Grafana 的 Alerting 和 Prometheus 的 Alertmanager 都有提供這樣的機制,可以將多個相同或相似的告警事件進行收斂,只保留一個告警事件,來減少告警事件的數量。這將是告警事件中心中非常重要的一環,可以有效減少告警事件的數量,避免造成告警疲勞。 而告警事件管理的收斂壓縮策略通常可以透過對告警事件的不同維度進行壓縮。
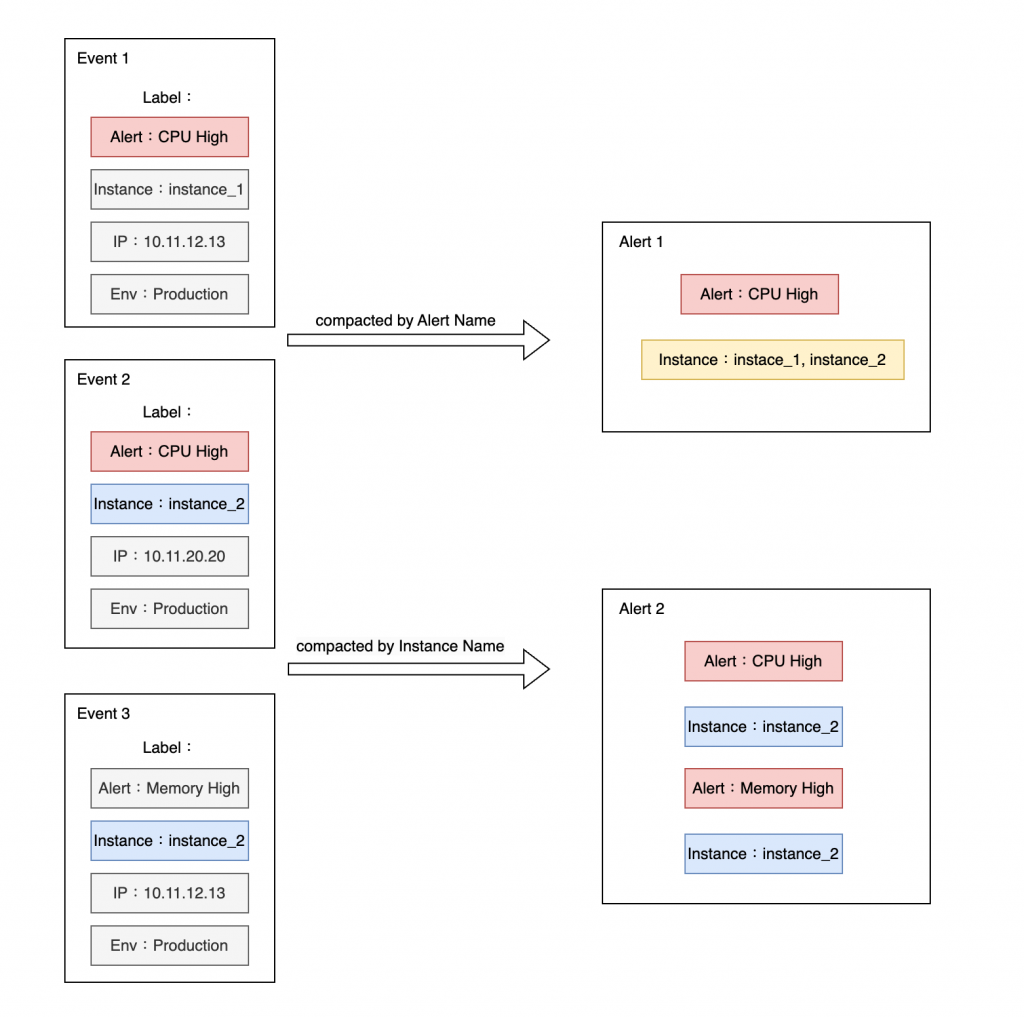
基於相同的標籤:
滿足條件的告警事件在收到通知時會按照通知策略中的進行分組,並且只保留一個告警事件,來減少告警事件的數量。
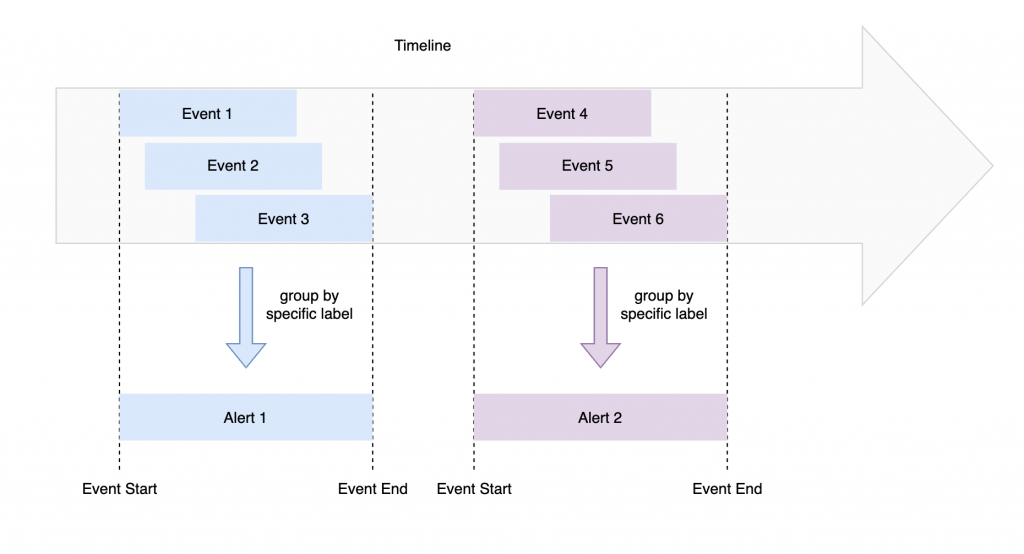
基於相近的時間:
對於相近時間的告警事件,我們也可以將其進行壓縮,讓其在同一段時間內合併為一個告警事件,來減少告警事件的數量。
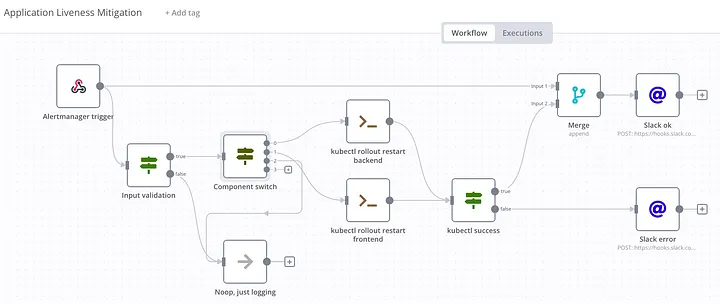
由 Alertmanager 觸發的 n8n 工作流,調用 kubectl rollout restart
很多的監控告警系統都具備配置 Webhook 的能力,當告警事件觸發後自動請求某個 API 端口,來執行一連串自動化的流程,讓告警事件可以擁有一部分的自癒能力。例如某台主機無法正常存取後,自動轉移流量、自動重啟服務、自動擴容等等,來減少人工介入的時間,提升效率。
當然,這些自動化流程並不能完全實現系統自癒,但完成的告警自動化搭配 Runbook 的實施,將能夠大幅減少維運人員的負擔,也讓值班人員在告警事件發生時能夠快速解決問題,不需經過消化不熟悉的操作文件和繁複的手動排查。
ChatOps 能有效解決告警處理中的資訊孤島問題,因為它將關鍵資訊和協作工具整合到一個平台上,讓維運人員能在同一界面上即時獲取資訊和協作。這避免了不同角色之間的資訊斷層,並加快了問題解決速度。以 Slack 為例,ChatOps 的主要優點包括:
透過 ChatOps,如 Slack 這樣的平台能有效打破資訊孤島,並且在介面互動中執行各種操作,同時記錄下操作歷程使所有歷程透明化。
告警事件中心是現代化維運中不可或缺的一環,透過有效的告警事件管理,可以大幅提升維運效率,減少告警疲勞的問題。而告警事件中心的最佳實踐,不僅可以提升維運效率,還可以讓維運人員在告警事件發生時能夠快速解決問題,不需經過消化不熟悉的操作文件和繁複的手動排查。 而下個章節,我們就將要回到 Grafana 生態系中,來介紹告警事件中心如何在 Grafana 中的實現!

