註:本文同步更新在Notion!(數學公式會比較好閱讀)
自生成模型(Autoregressive Generative Model, ARGM) 是一類重要的生成模型,旨在利用數據的過去資訊來生成未來數據點。
自生成模型的核心概念是,序列中的每個數據點都依賴於之前的數據點。給定一個序列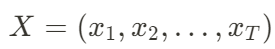 ,該序列的概率可以被分解為條件概率的乘積:
,該序列的概率可以被分解為條件概率的乘積:
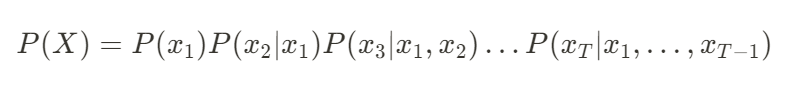
這種條件概率分解形式允許我們在生成一個新數據點時,基於過去的數據點來進行生成,從而產生一個有意義的序列。
自生成模型的結構可以是非常靈活的,最常見的有以下幾種:
線性自生成模型(Linear Autoregressive Models):基於線性假設,當前的數據點是過去數據點的線性組合,類似於自回歸模型(AR 模型)。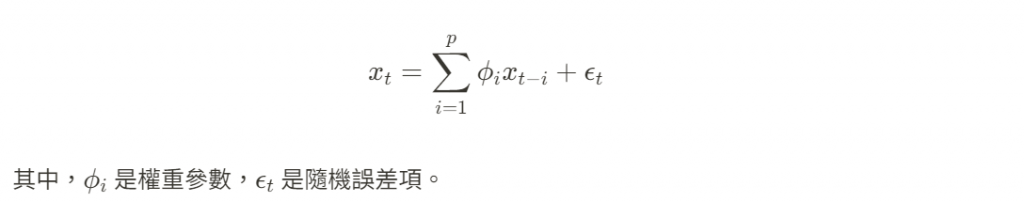
神經網路自生成模型(Neural Autoregressive Models):這類模型利用深度神經網路的強大學習能力,通過神經網路來捕捉數據中的非線性關係。典型的模型包括:
基於序列的自生成模型:如LSTM或GRU等遞迴神經網路,它們可以處理長距離依賴性,在生成長序列時非常有效。
自生成模型的生成過程是基於隨機過程的,每一步都是根據前一步生成的結果進行計算。具體步驟如下:
初始化:模型首先需要一個起始點(通常是隨機選取),例如序列的第一個數據點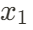
逐步生成:接著基於條件概率生成序列中的後續數據點:
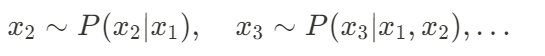
終止條件:生成過程可以按照固定長度終止,或者根據模型設計的一個停止符號來結束生成
自生成模型通常利用最大似然估計(Maximum Likelihood Estimation, MLE)來進行訓練。具體來說,模型會最小化負對數似然(Negative Log-Likelihood, NLL),即:
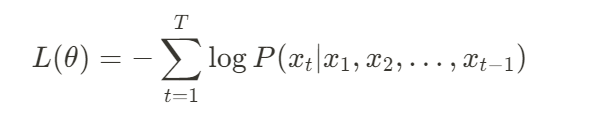
這個損失函數會指導模型學習每一步的條件概率分佈,從而提高生成的準確性。


 iThome鐵人賽
iThome鐵人賽