建築設計圖除了是由各種複雜圖元、符號、文字表格所交錯組成的一幅圖面外,它也受到不同設計繪圖者的習慣而有不同風格,檔案類型也有可能是手繪稿、CAD檔或是掃描圖像檔。
由於建築圖資料的多元特性,若單一使用YOLO同時來辨識圖形和文字,或許未必能達到最佳效果,而且也可能造成事倍功半。因為YOLO技術主要是透過標註資料集與卷積神經網路,預測特定物件的位置與信心分數。像建築圖中有中、英文或數字混雜、特定專有名詞的特性,如果要逐一分類並標註,勢必耗時又費力。
以車牌識別的例子來說,多以YOLO進行車牌物件定位後,再以OCR技術辨識文字與資料庫比對,不過因為車牌的文字組成簡單,僅有英文和數字的組合。同理,若建築圖圖元以YOLO辨識、文字採OCR辨識,發揮兩種AI技術的強項,最後再透過後處理整合,或許是建築圖資訊智慧數位化的一種解方。
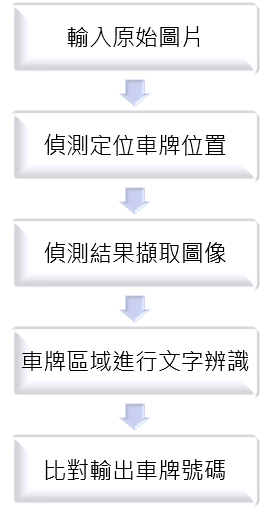
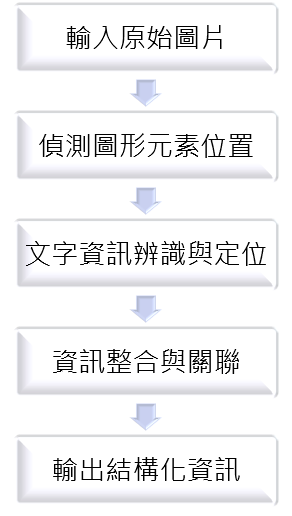
圖3.1 常見車牌辨識的流程圖 圖3.2 建築圖資訊辨識概念流程圖
傳統車牌辨識由於是真實環境所擷取的圖像或影像,一般需要將彩色圖像轉化為利於辨識的黑白圖像或線條框,而有經過二值化等影像處理技術。但在建築設計圖紙中,現階段多是由電腦繪圖軟體轉出2D黑白線條的圖面,但由於產業與智慧財產特性,有的時候並不能取得CAD圖檔,更多的是PDF檔或手繪稿照片。

因此,在開始訓練AI模型之前,首要的便是將圖檔或照片轉檔為模型可讀的圖像檔(如.png、.jpg等),如果圖檔中有彩色填充或線條,可以使用以下方法來前處理資料圖像(以Google Colab執行為例):
# 安裝opencv(Colab上通常已經有,沒裝才需要這行)
# !pip install opencv-python-headless
import cv2
import matplotlib.pyplot as plt
from google.colab import files
import os
# 1. 上傳你的圖片
uploaded = files.upload() # 選擇圖片
img_path = list(uploaded.keys())[0] # 取得原始檔名(如 sample.png)
# 2. 讀取圖片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 3. 轉成灰階
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 4. 自動二值化(Otsu's threshold)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 5. 用原檔名自動產生新的檔名
basename, ext = os.path.splitext(img_path)
binary_filename = f"{basename}_binary{ext}"
# 6. 儲存黑白圖
cv2.imwrite(binary_filename, binary)
# 7. 顯示對比
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plt.title('原始圖')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.subplot(1,2,2)
plt.title('二值化黑白圖')
plt.imshow(binary, cmap='gray')
plt.axis('off')
plt.show()
# 8. 下載黑白圖(自動以原檔名_binary命名)
files.download(binary_filename)
透過今天的例子可以了解到,當建築圖圖面色彩較複雜時,可以如同車牌辨識處理方法,先進行黑白二值化的影像前處理,有助於有效降低非主體的干擾,進而提升模型辨識的準確度。因此,在開始訓練AI之前,資料集的前處理是非常重要的一環。
在接下來的章節,我將以建築圖中的門與柱元素為例,進一步探討如何將AI辨識數據串聯進BIM模型,設計出一條完整的自動化流程,實現建築圖智慧化的下一步。

