昨天簡單介紹了 FFN 以及激活函數,會發現其實其中的觀念也是很多的。
參考文章&圖片來源: https://www.cnblogs.com/rossiXYZ/p/18765884
昨天 FFN 的核心觀念: 知識庫 → 儲存更多訊息 → 表達能力更強
這裡我們更進一步說明為什麼是"知識庫"。
假設模型想要回答一個問題,那某種意義上模型需要記住相關的知識,但 transformer 並沒有外接明確的資料庫,也就代表模型的知識只能表達在參數當中,所以真正學到的知識或資訊大多儲存在 FFN 中,也就代表這塊難以壓縮和加速。
FFN 可以類比為一種 key value 對儲存結構,當中的兩個 linear 可以這樣解釋:
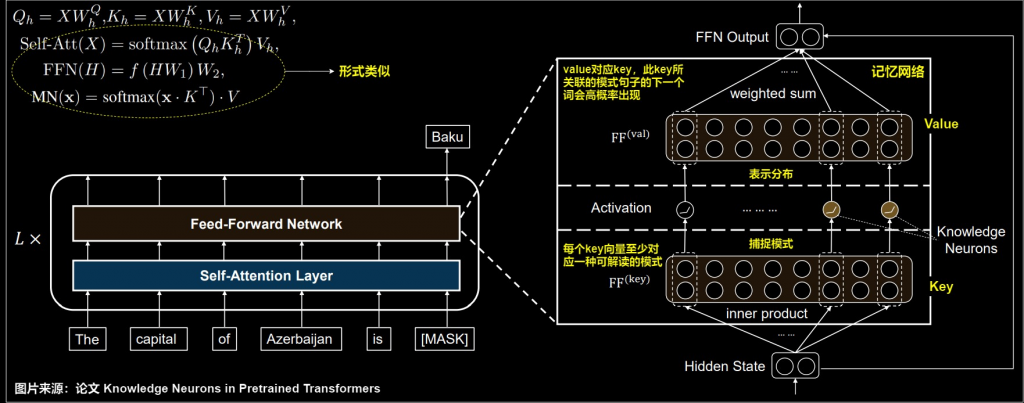
昨天有說到,現在 SLM 的主流是採用 swiGLU (其中參數設為1.0時為silu),其中門控 (Gated) 機制能學到"什麼要通過,什麼要抑制",可以有效的學習有用的資訊。
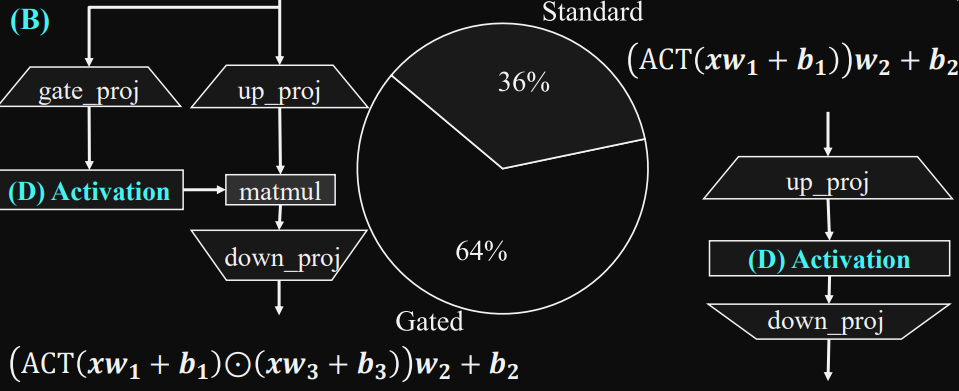
以下更詳細說明昨天提到 Ratio 為什麼主流不是 4倍,很大的原因是因為激活函數的改變,導致 ratio 的改變,如果使用 SwiGLU 因為多了一個 gate 的參數量,那希望保持跟原本參數量一樣,所以將 ratio 做些改變。
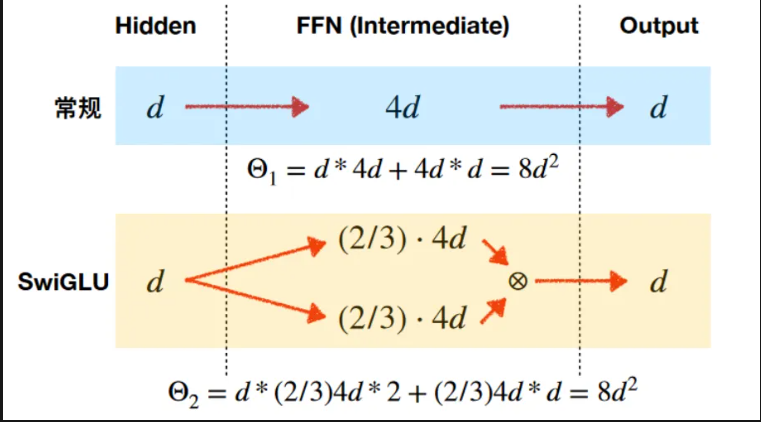
到這邊也許會覺得奇怪,這個門控機制和激活函數差在哪裡,因為激活函數昨天說到也是會過濾無用的訊息,跟這邊還蠻類似的,差距如下:
所以激活函數可以想像成它是一個"統一規則"的過濾器,而門控機制像是一個"智慧閘門"動態的調整。
湧現現象(emergent behavior),其主要原因與參數量有關。當參數達到一定規模時,模型整體效果會突然的提升。
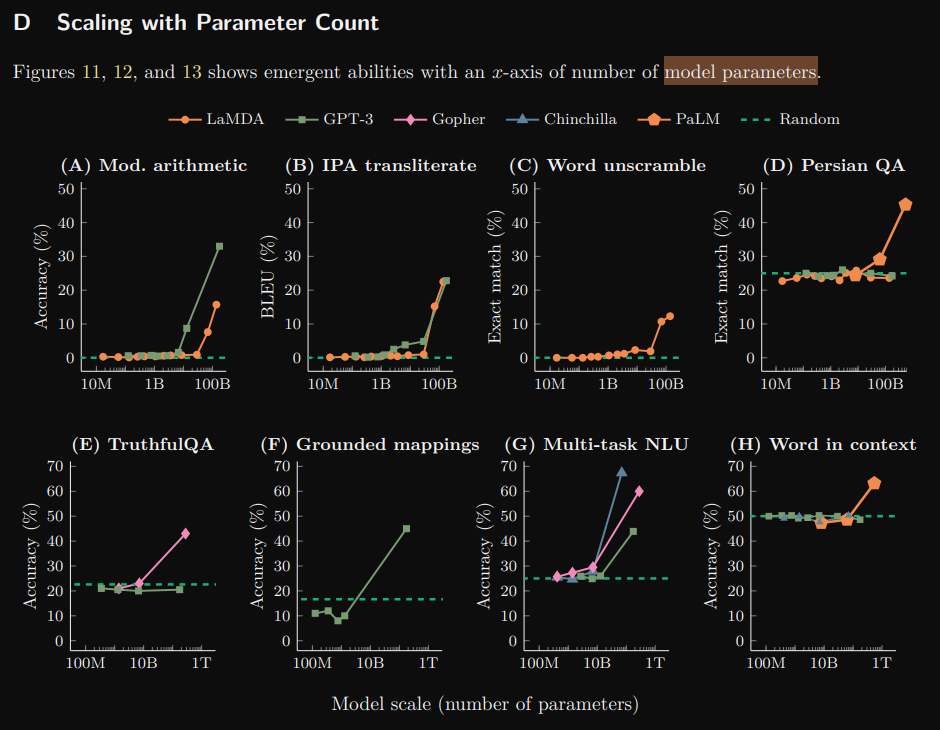
圖片來源: https://arxiv.org/pdf/2206.07682
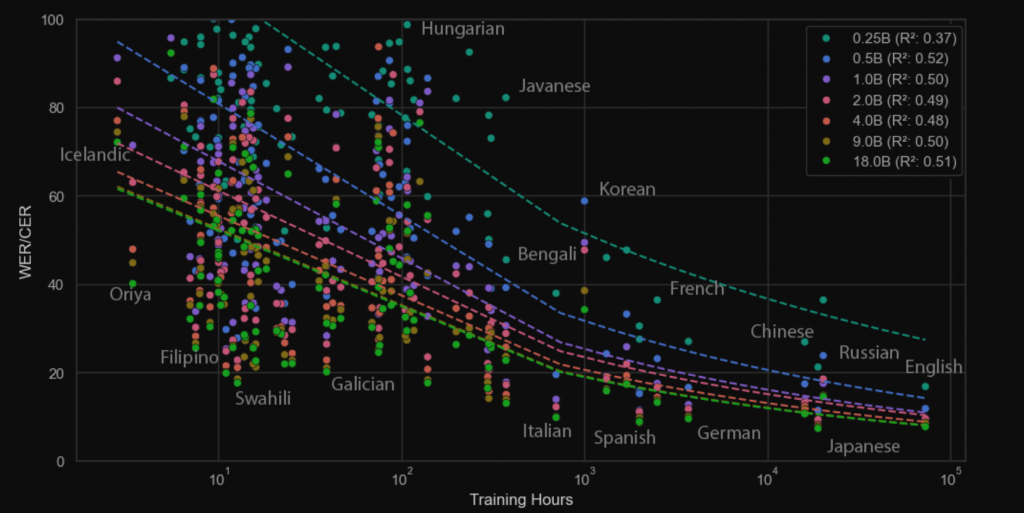
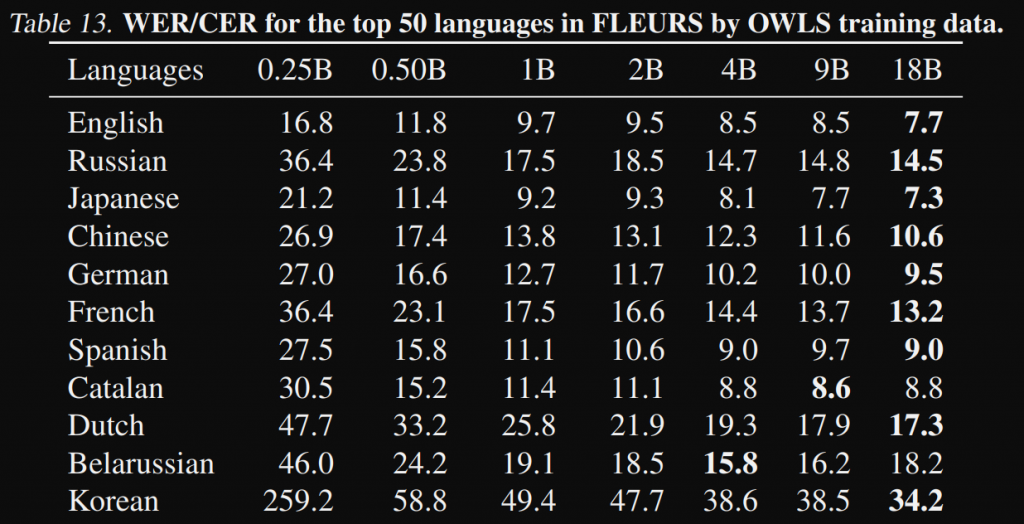
另外在 ASR 方面可以參考這篇論文,當中分別測試了訓練資料多寡以及各類模型大小,以數據來看的話大概是在 0.5B 發生湧現現象,WER 大幅的下降
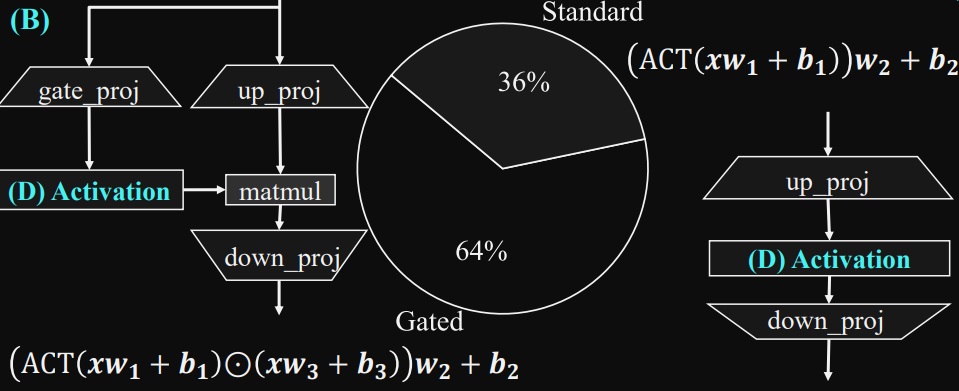
這裡完成名稱我們參照剛才論文的圖以
up_proj, down_proj, gate_proj 來命名,另外通常會用彈性的輸入來指定你是要用 relu 或者 silu
老樣子給出以下步驟,可參考圖
import torch
from torch import nn
import torch.nn.functional as F
# step 1
class MyFFN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor):
"""
x: (B, L, D)
"""
return
import torch
from torch import nn
import torch.nn.functional as F
# step 2
class MyFFN(nn.Module):
def __init__(
self,
hidden_size,
inner_size,
hidden_act = "relu"
):
super().__init__()
# 固定的兩個 linear
self.up_proj = nn.Linear(hidden_size, inner_size)
self.down_proj = nn.Linear(inner_size, hidden_size)
ACT2FN = {"relu": torch.relu, "silu": F.silu}
self.act_fn = ACT2FN[hidden_act]
self.hidden_act = hidden_act
# silu 需要再多宣告一個 linear
if self.hidden_act == "silu":
self.gate_proj = nn.Linear(hidden_size, inner_size)
def forward(self, x: torch.Tensor):
"""
x: (B, L, D)
"""
return
import torch
from torch import nn
import torch.nn.functional as F
# step 3
class MyFFN(nn.Module):
def __init__(
self,
hidden_size,
inner_size,
hidden_act = "relu"
):
super().__init__()
# 固定的兩個 linear
self.up_proj = nn.Linear(hidden_size, inner_size)
self.down_proj = nn.Linear(inner_size, hidden_size)
ACT2FN = {"relu": torch.relu, "silu": F.silu}
self.act_fn = ACT2FN[hidden_act]
self.hidden_act = hidden_act
# silu 需要再多宣告一個 linear
if self.hidden_act == "silu":
self.gate_proj = nn.Linear(hidden_size, inner_size)
def forward(self, x: torch.Tensor):
"""
x: (B, L, D)
"""
if self.hidden_act == "silu":
# SwiGLU: up_proj(x) * act(gate_proj(x))
up = self.up_proj(x)
gate = self.act_fn(self.gate_proj(x))
output_states = self.down_proj(up * gate)
else:
# 標準 FFN
hidden_states = self.up_proj(x)
hidden_states = self.act_fn(hidden_states)
output_states = self.down_proj(hidden_states)
return output_states
if __name__ == "__main__":
model = MyFFN(
hidden_size = 64,
inner_size = 64 * 4,
hidden_act = "relu"
)
model2 = MyFFN(
hidden_size = 64,
inner_size = 64 * 4,
hidden_act = "silu"
)
x = torch.rand(2, 100, 64)
y = model(x)
y2 = model2(x)
print(y.shape, y2.shape)
經過這十一天相信你比當初會了很多,想當初自己每天花四到五小時看觀念研究到實作,希望你也可以多加油,從 0 → 1 是最困難的,今天就到這裡囉~


 iThome鐵人賽
iThome鐵人賽