昨天終於把 FFN 的部分講完也實作完了,雖然只是小小一個 block 但內部其實包含了很多觀念。
參考文章&圖片來源: https://www.cnblogs.com/rossiXYZ/p/18774865
今天把前面的坑補一下,先來介紹常見的三種 Norm,分別是 batchnorm, layernrom, rmsnorm
標準差核心觀念: 描述數據的分散程度
在高中統計的單元,你一定算過平均和標準差或變異數,如果想複習一下標準差,建議可以看以下兩個高中影片,回味一下。
https://www.youtube.com/watch?v=aeB5ftpf0ak
https://www.youtube.com/watch?v=0X9yGwP2jX4
這裡變異數公式: 離差平方和/n, 離差 = 各點與平均值之間的差值,可以透過公式來衡量數據的分散程度。
步驟:
底下是論文的流程圖可以當參考

可以想像原始是 x 分布,經過歸一化讓他落在平均值0(左右剛好抵銷), 標準差 1,最後再透過 scale 和 shift 還原回去
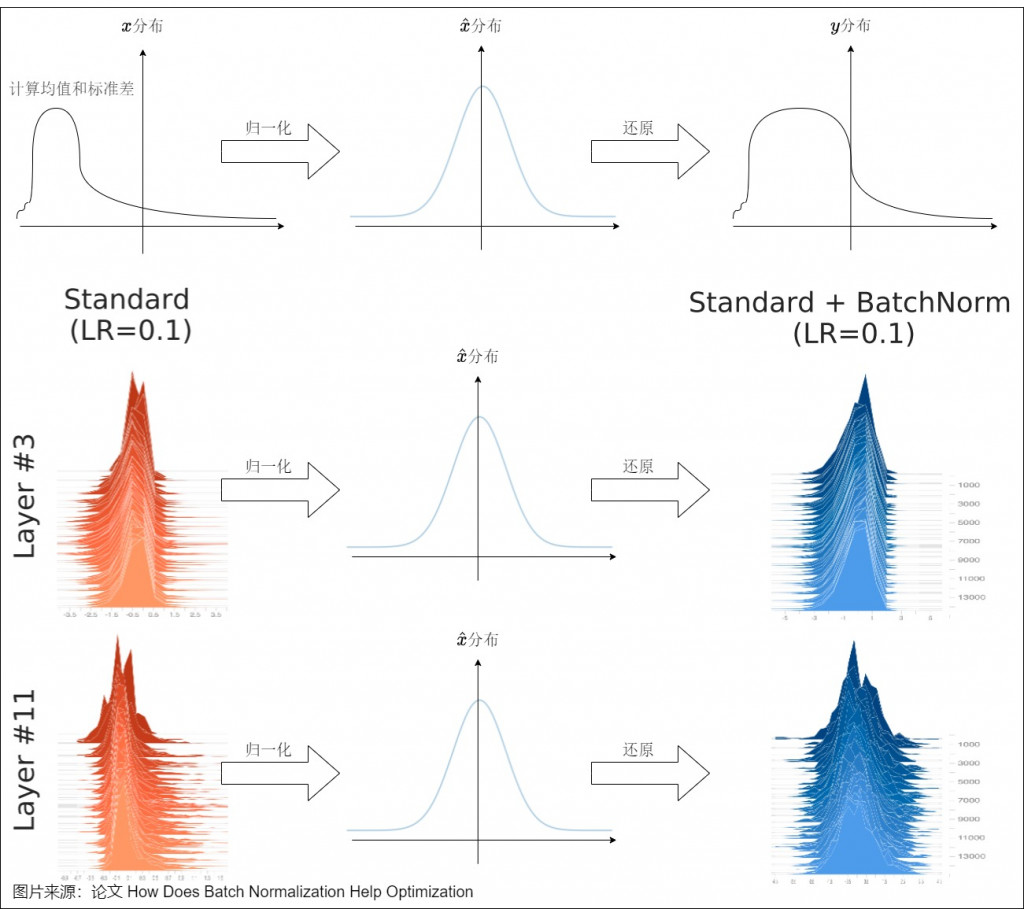
batchnorm 提出是在2015年的時候,當初其實還比較少 LM 的相關研究,基本上是以圖像為主,那圖像通常是固定的 size,所以會像下圖上半這樣,可能維度3表示一個"固定"特徵,所以當初論文加了 batchnrom 大幅提高精準度以及減少訓練難度。
但後來有 LLM 跟 ASR 更多研究,序列長度都不一定一樣,一樣看下圖下半,當中的["大", "香", "網", pad, "杯"],把這五個本來就沒什麼關係的特徵去歸一化,可想而知沒有太大意義,也就導致 batchnrom 效果不好,因此除了CV領域外漸漸被後續 layernrom 跟 rmsnorm 取代掉。
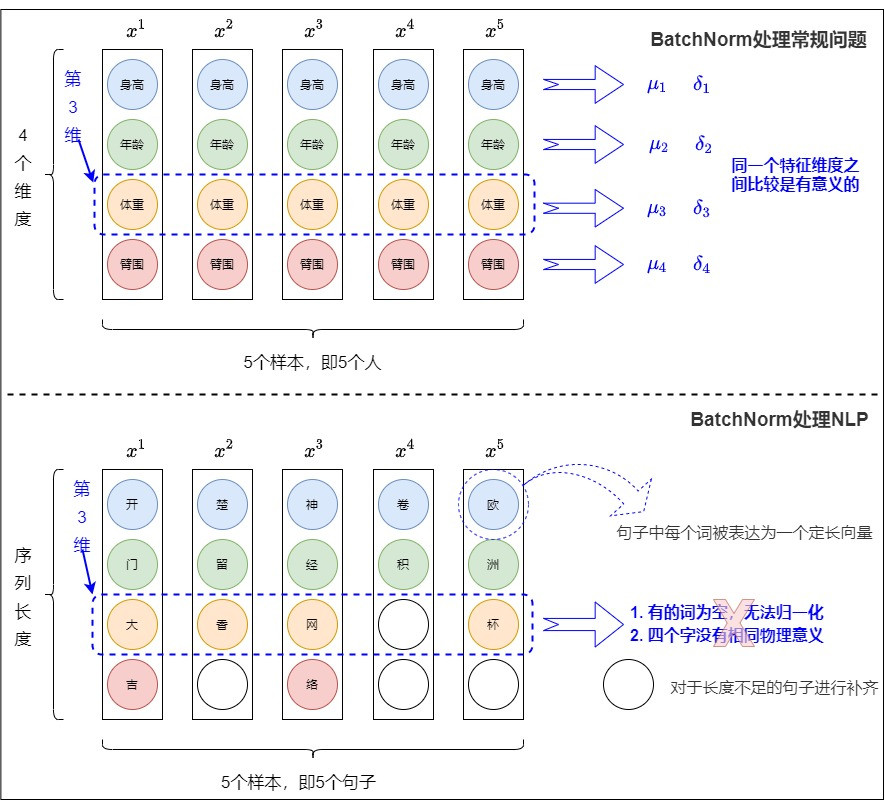
核心觀念: 著重在單個句子(token) → 不受序列長度影響
一樣以上圖做講解,在處理 NLP 的部分,基本上 batch 當中的每筆資料(每句話)不見得有關係,所以將整個 batch 就歸一化就沒有意義,所以轉換成每筆資料(每句話)自行做歸一化,那可以想像在一句話當中找一個"語義中心",所有詞都聚集在語義中心周圍。
註: 上述表達跟實際應用上有出入,實際應用在 NLP 當中是針對"單一" token 的所有 features 做標準化,而不是對單一句子(搭配下圖)。
基本上步驟跟 batchnrom 一模一樣,只算在算 mean and variance 針對不同維度(藍色區域),但應用在 CNN 跟 transformer 的 LayerNorm 用法又不一樣。
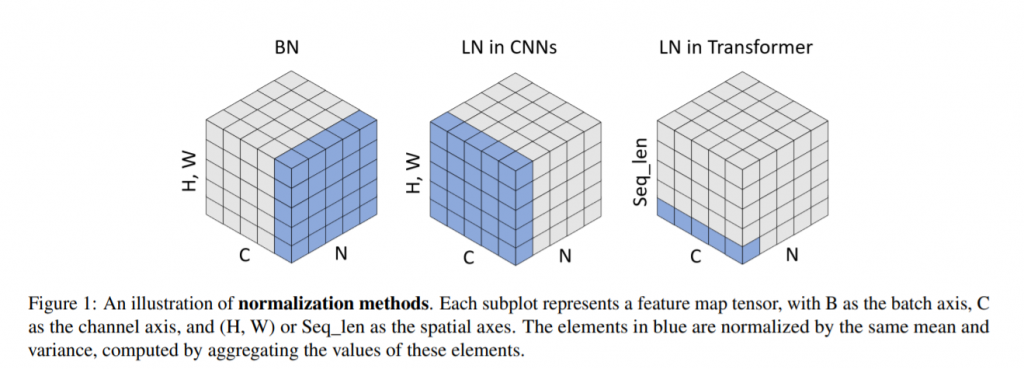
圖片來源: https://openaccess.thecvf.com/content/ICCV2021W/NeurArch/papers/Yao_Leveraging_Batch_Normalization_for_Vision_Transformers_ICCVW_2021_paper.pdf
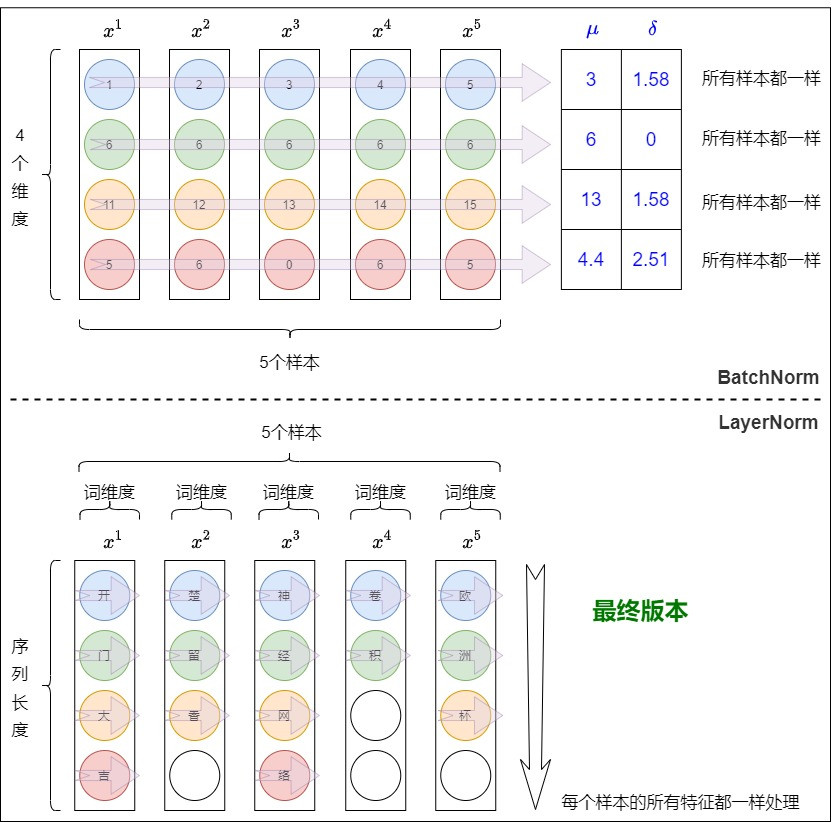
實際應用在 NLP 的 LayerNorm 會像下圖這樣,是針對"單一" token (比如說"開")的 features 進行歸一化,所以就不會受到 batch 跟序列長度影響。
老樣子一樣來個 QA
Question
Ans
讓我們分幾個層次來探討看看
所以 LN 在 NLP 的設計初衷比較會偏向,希望讓每個 toekn 各自獨立歸一化,讓這個 token 的 hidden state 在不同 feature 維度上的分布更穩定。
看了上面兩個 normalization,應該可以知道它的功用,主要有三點:
會有上面三點,主要是因為歸一化把範圍固定住了,固定在標準分布,然後也有把一部分不重要的複雜訊息過濾掉(比如說極端值,做完 Batchnrom 會變比較緩和),所以使得數據的分布穩定下來,這樣可以減少 over-fitting 的問題,加速模型的收斂。
今天就先到這裡囉,明天繼續講 rmsnrom 跟實作。


 iThome鐵人賽
iThome鐵人賽