Vercel 部署完成 ✔️ 使用者能寫日記 ✔️
接著我回頭處理一件更微妙的事:讓系統聽懂「普普通通的一天」
前一版我是用關鍵字規則做三分類(正向/中立/負向)。直覺、好維護,但遇到否定、轉折、反諷或是隱性情緒就會露餡,所以今天我先把規則法放一邊,純粹跑 HuggingFace 模型來做三分類:只測模型效果,暫時不接到日記系統。目標很單純:先把模型本體調好,再談整合
我用 multilingual sentiment datasets(已標好正向/中立/負向),再用 opencc 做簡轉繁,確保在繁中環境也穩。
切分方式:Train / Val / Test = 70% / 15% / 15%(分層抽樣,三類都要有代表性)
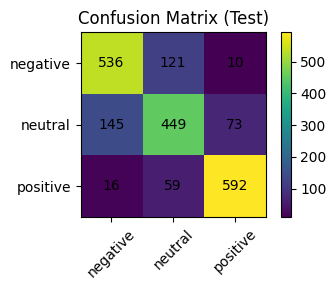
中立是最難的一類,因為多半代表「線索不足」或「描述客觀狀態」。不是資料有問題,而是語言本來就這樣
這次的 baseline 我選的是 bert-base-chinese,原因很單純:速度快、資源需求小
不過 BERT 的訓練語料主要來自簡體中文,所以我後來也測了 hfl/chinese-macbert-base。雖然是簡體語料,但因為 tokenizer 採字級斷詞,對繁體依然有良好效果
本輪代表性結果(以驗證集為主):
正向/負向辨識表現不錯(0.88/0.79),中立則稍弱一點(0.69)但還行啦
這個數字雖然不是頂尖,但對於「日記」這種天然模糊的文字來說,已經能給出相當實用的建議
Early Stopping 就看 驗證集的 loss(eval_loss) 表現,如果連續 2 次沒有更好就停。這次最佳點落在 第 2 輪(Epoch 2),再往後驗證集就開始「越學越糟」,也就是 overfitting 了
學習率 & 節奏控制
學習率抓 1e-5 ~ 2e-5 但我覺得可能可以再慢一點,前面 10% 步數先熱身(warmup),之後用 cosine 緩緩降速。用白話說就是:一開始慢慢踩油門,後面慢慢收,這樣後段比較不會把驗證集搞壞
regularisation(避免太黏訓練資料)
開 weight_decay=0.05、把 dropout 調到 0.2,再加一點 label smoothing=0.05~0.1。因為不能讓模型太自信、太黏訓練題目,面對雜訊句子會穩很多
長度 & 批量
MAX_LEN=128 就夠用(大多數句子不長)。batch size 32/64 看你的記憶體決定,能大一點會更平滑,但別把 GPU 撐爆就好
小結
訓練集的 loss 一直掉,但 驗證集在第 2 輪後開始回升。所以我先把 Epoch 2 的 checkpoint 鎖起來當候選上線版,等和日記系統整合時再跑一次完整驗證就好。
目前還沒有接到日記系統,這一輪純測模型本體。觀察如下:
Day 23 要升級到 文字情緒分類器 v2!
想把這顆模型「講得更老實、也講得更清楚」。先來做校準,讓那個 0.8 的信心分數真的比較接近「八成會對」的意思;順便試試把信心太低的案例先打個「不確定」標籤(我會先抓 0.6 左右),別硬判。然後我會偷看一下模型在想什麼,用 LIME/SHAP 把它在意的詞亮出來,看看哪些字眼把情緒往上拉、哪些又把它往下拖。等這兩件事穩了,再把結果包成好用的推論介面,離回接到日記系統就只差一步啦

