昨天把三分類模型(正面/中立/負面)練到一個還不錯的狀態,整體準確率大概 79% 左右。
但準確率好不代表「信心分數」就好用——有時候它跟我說 0.73,很有自信;結果一查,嗯…根本在唬爛。今天就來做三件事,讓它少一點神祕感:
做完這三步,模型不一定立刻從 79% 變 85%,但用起來會穩很多,而且遇到怪句子,你也比較知道該怪誰
我用我不是要把分數硬往上拉,而是要讓信心分數別亂吹牛
用了 Temperature Scaling,在驗證集學到一個溫度 T≈1.04;推論時把 logits 除以 T 再 softmax。答案不會變,只是把機率調得比較貼近真相
怎麼判斷有沒有用?看可靠度曲線(Reliability diagram):橫軸是 Average confidence,縱軸是 Empirical accuracy。
我的結果:校準前 ECE=0.031 → 校準後 ECE=0.028,綠線比橘線更靠近對角線一點點。
另外你會看到 0.6 以下幾乎沒有點——不是壞掉,是因為模型的 top 置信度大多落在 0.6–1.0,那段才有足夠樣本數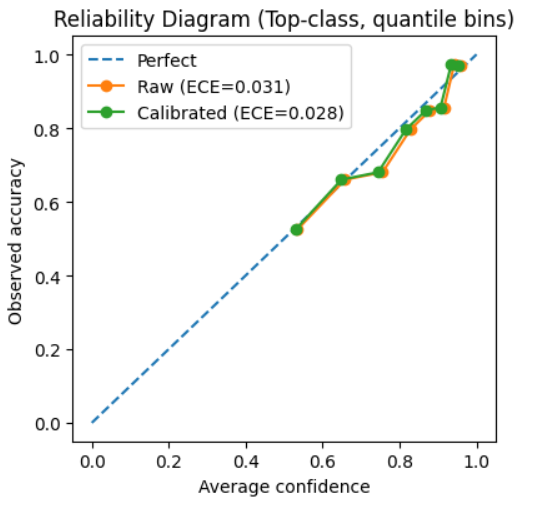
基於這個分布,我把**「不確定」門檻**先設在 0.6:低於 0.6 就先別判,交給人看。覆蓋率會少一點,但自動判那一批會更準,體感穩。
不確定就先不判。我用校準後的機率掃了一圈門檻,發現 t=0.60 時,自動標記的覆蓋率約 86.8%,而那一批的正確率約 82.7%;比整體測試準確率 78.8% 高一截。若我把門檻拉到 0.65,正確率會再升一點,但覆蓋率會掉到 ~80%。權衡後我先採 0.60,之後再視實際錯判型態微調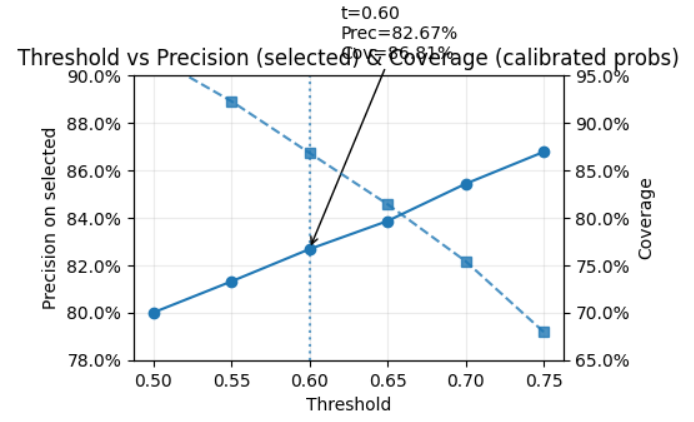
模型常常對語氣詞很敏感(「不太」「還好」「有點」「不過」「還行」…),但不看就不知道敏感到什麼程度。
我先用 LIME 做一個「快速看重點詞」的版本(上手快);有時間再玩 SHAP
LIME 會列出「把分數往上/往下拉的詞」
紅/綠的意義:是「對目標類別的貢獻」,紅色不代表負面語意,只是對該類別是負向貢獻(例如把 positive 分數往 neutral 拉)
我用中文分詞(jieba)+校準後機率,解釋更貼近語感
例句:「花了一百塊玩刮刮樂,結果什麼都沒中,真倒楣」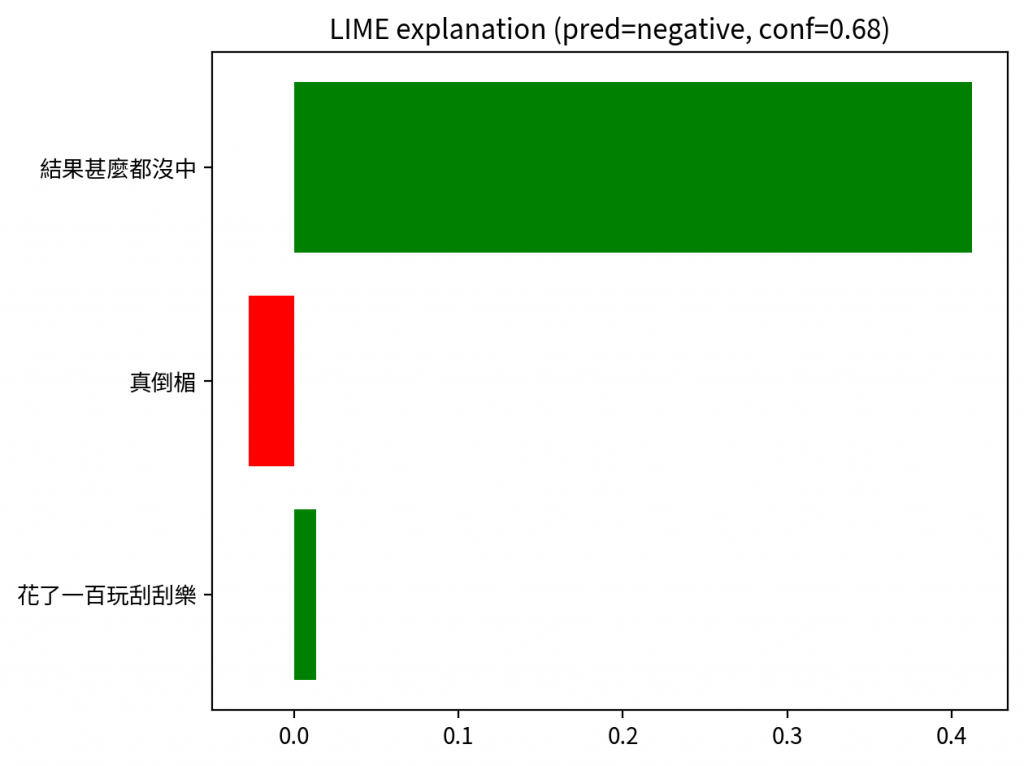
今天的改造比較像「教小朋友做人(?)」:
校準 -> 讓它的信心不再亂喊;
不確定門檻 -> 讓它學會說「我先不要」;
可解釋 -> 讓它講得出「為什麼」。
我不需要它每句都 100% 正確(那大概也不可能,我沒那麼厲害),我需要它在該保守時保守、該自信時自信,而我也看得懂它的判斷邏輯。這樣,把它接回日記系統的時候,整個體驗才會舒服。
明天我會把今天的成果接進推論 API,前端顯示中文標籤+校準後的 confidence,再把「不確定」當作一個正式狀態處理。
另外會挑幾段日記做「前/後對照」:加門檻前到底誤判了什麼;LIME/SHAP 看到的重點詞又是哪些。
如果一切順利,就準備回到主線任務:把情緒小標籤搬進日記列表與詳情頁。

