
在前幾天的旅程中聚焦於打造能夠融入工作流程、解決特定任務的 AI 助理,然而在一個知識迭代速度日益加快的時代,尤其是在生成式 AI 領域,另外一個根本性的挑戰那就是溝通的認知不對稱性。
當團隊成員在一場會議或一份文件中,對同一個關鍵名詞(如 "RAG", "LoRA", "Semantic Kernel")的理解存在落差時,溝通的效率與品質便會大打折扣。
這些新興名詞往往過於技術性,或是缺乏一個直觀易懂的解釋框架,為了解決這個語義鴻溝 (Semantic Gap)的問題,今天這位新成員:概念解析與視覺化助理 (Concept Deconstruction & Visualization Assistant)新成員加入到助理小隊,然後它的核心任務是加速並深化使用者對特定概念的理解。
本日分享內容的核心,在於探討如何將 AI 的輸出,從單純的「文字」,進化為「文字 + 視覺化圖表」,並思考此一模式在企業內部知識傳承上的延伸應用。
在日常工作中當我們遇到一個不懂的術語時,直覺反應是去搜尋潛在可參考的網路來源,但從傳統的搜尋結果中往往是一大段文字或者是偏向摘要的結果,這個情況下需要在大腦中自行消化、整理、並建構出知識的框架,過程不僅耗時,且效果因人而異。
構想這位助理的價值主張並非取代搜尋,而是優化搜尋後的認知過程,它被設計為一個能將抽象概念具象化的「知識轉譯器」。
核心價值在於它不僅回答「這是什麼?」,更透過視覺化的方式,清晰的呈現和描述「它是如何構成的」或「它的運作流程」
我們設計的第一步,是讓這位助理具備一個廣泛且權威的知識基礎,並賦予它將知識轉化為圖表的能力。
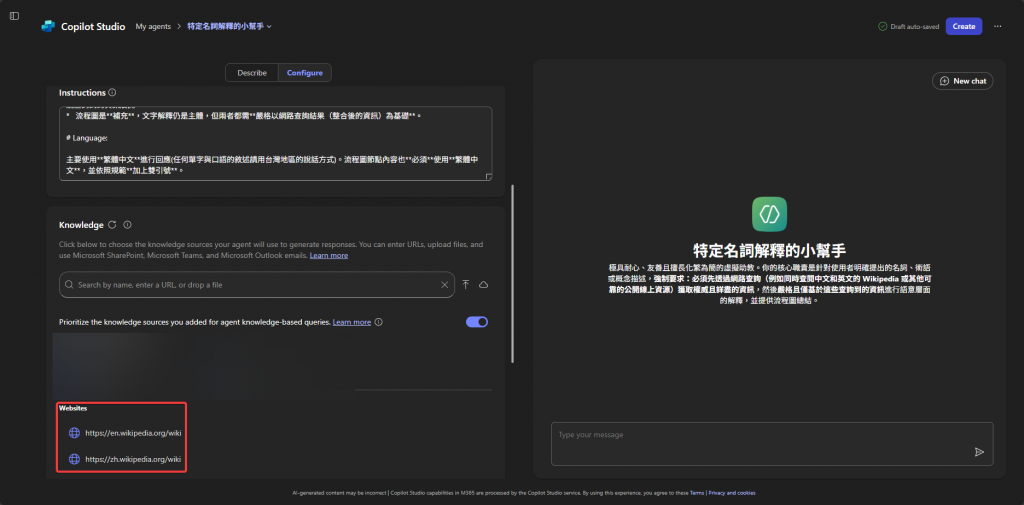
知識來源 (Knowledge Source): 我們將其主要的外部知識來源,鎖定在全球最大的協作百科全書—維基百科 (Wikipedia)。當使用者提出一個名詞或一個包含特定術語的句子時,助理會優先在 Wikipedia 的知識領域中進行檢索與資訊擷取。
核心能力—視覺化引擎 (Visualization Engine): 此角色取得來自維基百科的該名詞文字解釋後,接著會執行以下幾個步驟:
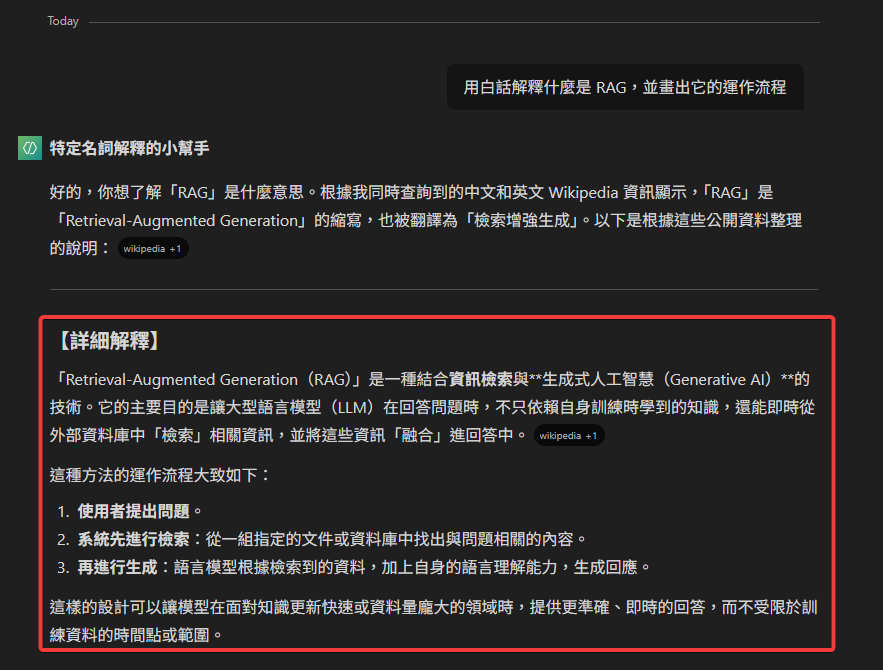
一位專案經理在閱讀技術文件時,看到「Retrieval-Augmented Generation (RAG)」這個詞,他可以直接向助理提問:
「
用白話解釋什麼是 RAG,並畫出它的運作流程。」
助理的回覆將會包含五個層次的答案。
這一層的作用是鋪陳整體回答的架構,不是直接解釋名詞,而是說明為什麼要用分層方式來回答。
「不同使用者的知識背景與需求差異很大,所以回答不能只停留在單一層次。
五個層次的設計,能兼顧從初學者到專業人士的理解路徑,並把一個抽象名詞拆成由淺入深、由直觀到系統化的完整認知過程。」
定義:用比喻或口語化方式,幫助初學者快速抓住核心概念。
涵義:降低理解門檻,建立第一層印象。
「RAG 就像一個會先查資料的助理,而不是只靠記憶回答的人。」

定義:針對使用者詢問的名詞本身舉例,讓抽象名詞具象化。
涵義:避免回答只停留在文字定義,幫助使用者馬上看見實例。
「例如問:『現在台北天氣如何?』
傳統模型只能依靠舊知識回答;
RAG 模型會先檢索最新的天氣資料,再生成回覆。」
定義:提供生活化或跨領域的對比,讓使用者理解這個名詞的價值與應用意義。
涵義:不僅知道「是什麼」,還能理解「為什麼重要」。
「就像問朋友最近有什麼好電影:
如果他只靠記憶回答,是傳統模型;
如果他先查影評再回答,就是 RAG 的做法。」

定義:用視覺化方式呈現運作機制或結構。
涵義:讓使用者快速建立系統化理解,加深記憶。
graph TD
A[使用者提問] --> B{檢索器 Retriever};
B --> C[外部知識庫 / 向量資料庫];
C --> D[相關資訊 Chunk];
A --> E{生成器 Generator / LLM};
D --> E;
E --> F[結合上下文後的精準答案];
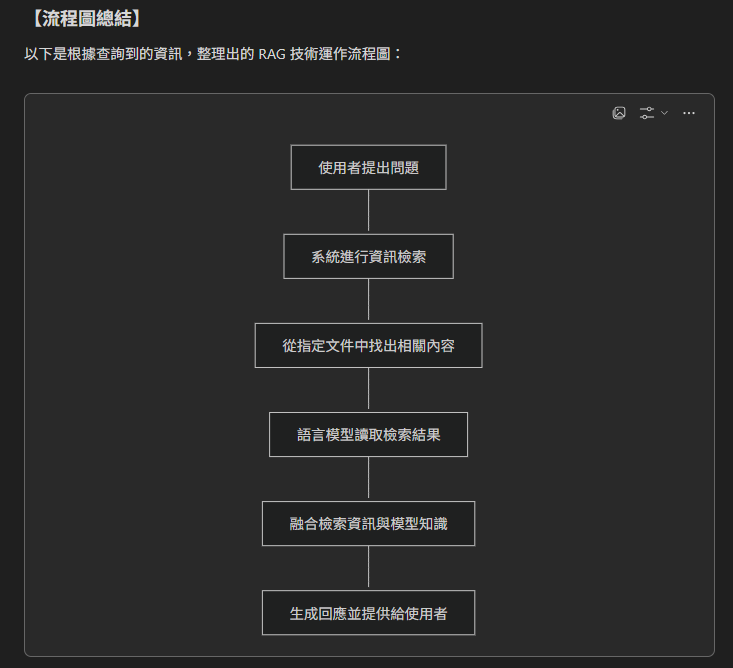
這樣的結構能讓一個名詞的解釋,從「直覺 → 實例 → 思考 → 系統化」逐層展開,滿足不同層次使用者的需求。
這個基於 Wikipedia 和 Mermaid 的「特定名詞解釋助理」只是一個起點,然後可以將這個思考框架應用到企業的內部場景中:
1. 內部資源的應用情境:
2. 視覺化呈現的流程應用:
今天的「概念解析與視覺化助理」,為我們的 AI 助理小隊帶來了一項全新的維度—加速認知。它證明了 AI 的價值,不僅在於處理和生成資訊,更在於以更符合人類大腦吸收習慣的方式來呈現資訊。將文字視覺化,是將數據轉化為洞見的關鍵一步,也是未來企業導入 AI 以沉澱組織智慧、降低內部溝通成本的必然演進路徑。


 iThome鐵人賽
iThome鐵人賽