資料,就像藏在網頁裡的寶藏,要先學會一點點魔法,才挖得出來。
前面我們學會了許多節點、資料流的基礎運作方式,也開始熟悉如何觸發與執行任務。
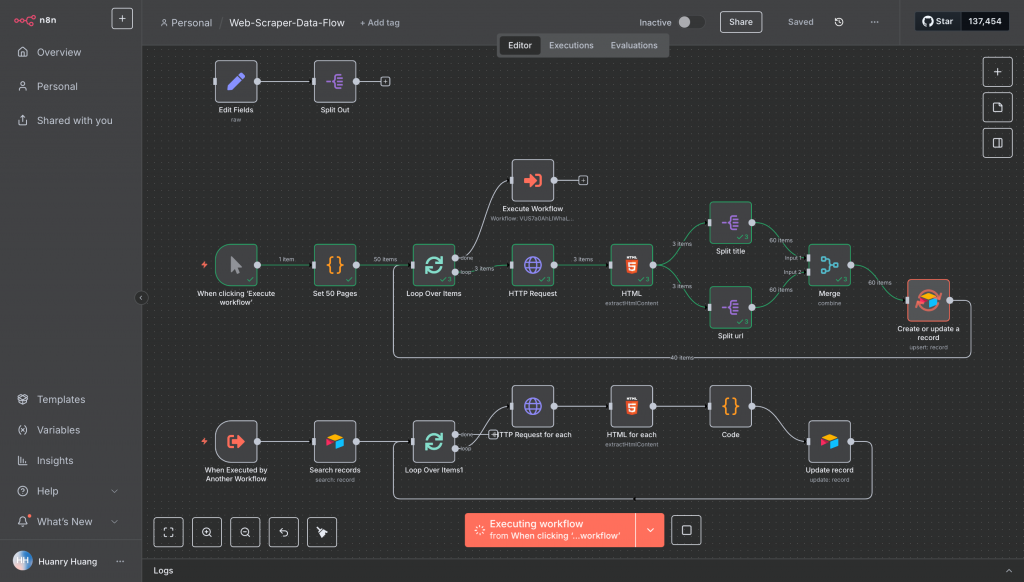
接下來,我們要開始學習更複雜的資料流案例,用 n8n 打造一條可以自動「爬取」網站資料的生產線!
我們不是要成為專業爬蟲工程師,而是要藉由這個練習,更深入理解資料流的傳輸、處理,以及流程的設計邏輯。
為了簡單上手,我們再次使用這個專門給人練習爬蟲的網站:
在 Day 8、Day 9,我們已經學會如何請求首頁,並解析出首頁 20 本書的書名與連結。
現在,我們要更進一步,把網站上全部 1000 本書的資料都抓下來!
觀察一下網站結構,我們會發現幾件事:
這就像是在工廠裡建立一條生產線,前段負責「找到書的門牌」、中段負責「進門拿資料」、後段負責「集中整理資料」。
今天的工作流範本可以在這個個鍊結下載。(鏈結)
爬蟲雖然可以一口氣串成一條完整流程,但為了讓大家一步步理解資料流的傳遞與轉換,我們會拆解成 5 個章節,分別在接下來 5 天學習:
Day 17 :資料分離與聚合
學會把混在一起的 HTML 資料,拆開後再重新組合
Day 18 :資料外部儲存及讀取
學會把資料存進 Airtable 這類資料庫,並能再讀出來
Day 19 :迴圈處理資料(爬每本書)與資料更新
學會讓流程自己重複處理一堆資料,不要靠人力複製節點
Day 20 :清洗處理資料、Code 節點
學會用程式碼節點來整理、轉換資料格式
Day 21 :Set 節點以及完整工作流
學會把資料欄位統一整理,並串成一條最終的完整工作流
為了預備接下來的章節,今天請先完成以下兩件事:
🧩 將你目前的工作流上傳到白板(n8n canvas)
並試著觀察每個節點,猜猜看它的用途與資料流向
🗄️ 註冊 Airtable 帳號,並在 n8n 裡設定 Airtable 節點的 Credential
(這會在 Day 18 用到)
這個練習的重點,不是寫出世界上最強的爬蟲,而是要讓你從一條可以自動流動的資料線中,看懂資料流的運作邏輯。
當你真的能做到一鍵爬完整個網站,你會發現,資料流就像水管,只要會接水管,任何資料都能為你所用 💧
我建立了一個行銷技術交流群,專注討論 SEO、行銷自動化等主題,歡迎有興趣的朋友一起加入交流。
掃QR Code 或點擊圖片加入


