
在 Cluster 架構中,除了 Master Slave 架構外,還有多 Master 架構,該架構主要解決:
為解決上述問題要用 Data Sharding 技術,如同 Table Partition 將資料分散到不同 B+Tree 檔案,Data Sharding 也採用類似策略將資料依照 Sharding Key 分散到不同的資料庫。
好的 Sharding 策略需滿足:
而滿足上述條件且廣泛用於許多資料庫的策略為 Consistent Hashing。
什麼是 Consistent Hashing?
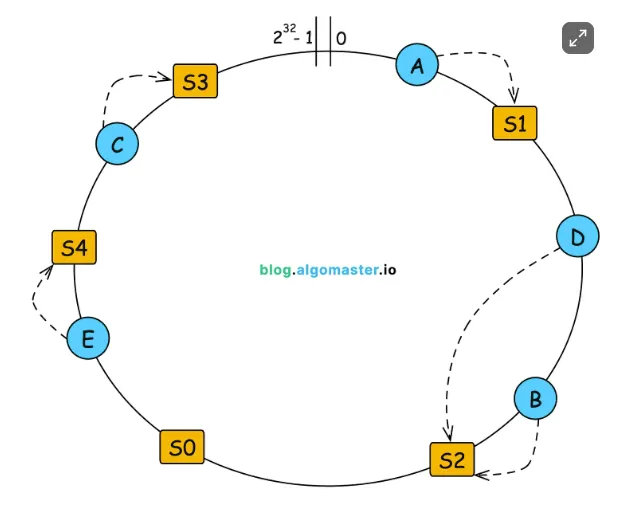
Consistent Hashing 利用 Hash Function 將 sharing key 轉成 hash value,但不是透過取餘數方式分配資料,而是建立一個環狀的空間,將資料分配到該空間中。
(圖來源:https://blog.algomaster.io/p/consistent-hashing-explained)
如上圖, Hash Function 產生 Value 的範圍為 0~2³²-1,將 0 與 2³²-1 相連形成一個環,把資料庫用不同數字代表,並放在環中,而獲得資料的 Hash Value 後順時針尋找,第一個遇到的資料庫就是該資料的歸屬。
但如果 Hash Function 無法平均分散 Hash Value 呢?
Consistent Hash 使用 Virtual Node 的概念,一個資料庫可負責環中不同區段資料,即便 Hash Function 產生的 Value 都坐落在某些區段也能分散到不同資料庫儲存。
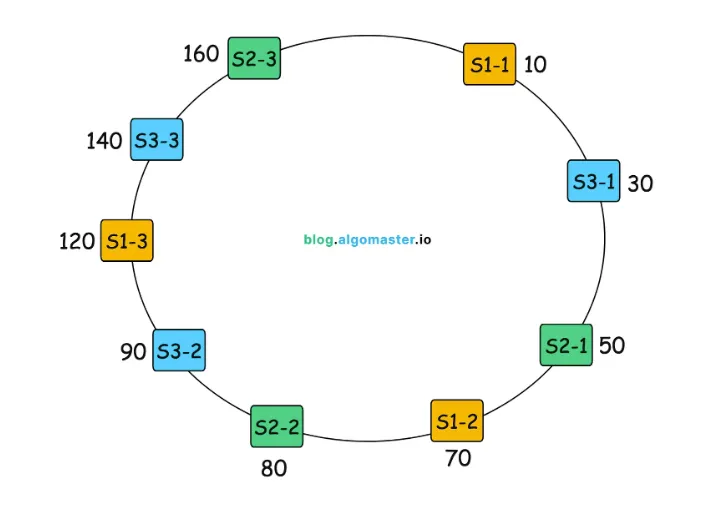
(圖來源:https://blog.algomaster.io/p/consistent-hashing-explained)
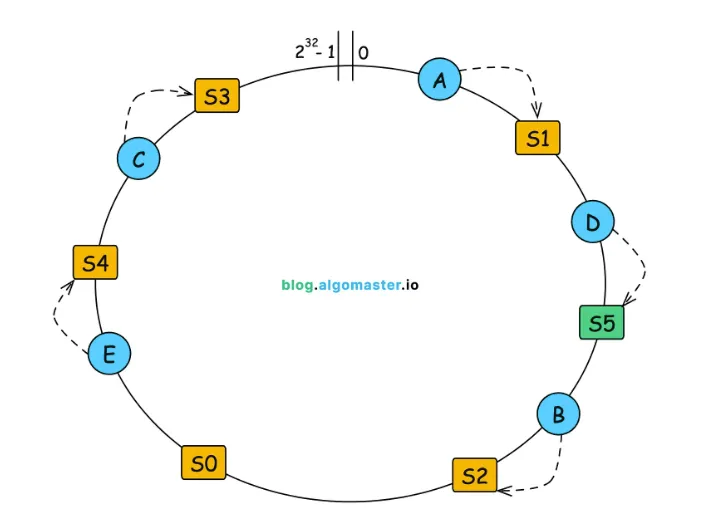
此外當 Cluster 新增或刪除節點時,只會影響部分區段的資料:
新增 S5 資料庫後,只需將 D 資料從 S2 移動到 S5,其他都不動。
(圖來源:https://blog.algomaster.io/p/consistent-hashing-explained)
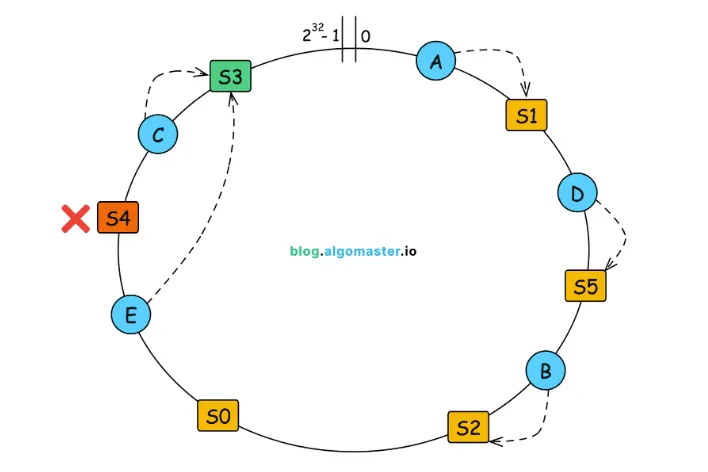
同樣刪除也是,除了移動數量少的優點外,資料搬移範圍是可控且可預測的,這在需要動態擴展的 Cluster 架構中是非常大的優勢!
(圖來源:https://blog.algomaster.io/p/consistent-hashing-explained)
Consistent 也並非完美,他的缺點有:
第一種方式可透過集中式 Proxy Server 導流,Proxy Sever 會從外部資料庫獲取 Sharding Metadata,而該資料透過 Cluster DB 寫入。
Sharding Metadata 包含:
儲存 Sharding Metadata 的資料庫需具備:
集中式的優點 是一致性強、運維與更新方便,缺點是會增加一層網路傳輸、增加延遲和單點故障風險,不過 Proxy Server 也可水平擴展。
第二種方式為分散式架構中,每個資料庫都有一份 Sharding Metadata,透過網路協定互相同步,不依賴外部儲存元件,也無需 proxy,Client 可向任一 DB 拉取 Metadata 內容,直接獲取資料位置並發送請求。
例如 Cassandra 透過 Gossip 網路協議,一傳十,十傳百將 Sharding Metadata 廣播給所有 DB,優點是 Client 直連降低延遲,資料分散降低風險,缺點沒有即時一致性,可能導致短暫資料錯誤且實作和維運較複雜。
節點動態擴展時,需要移動資料到新節點,稱為 ReSharding,而 ReSharding 過程必須:
Offline 搬移安全簡單,但會影響線上讀寫,所以必須 Online 搬移,同時處理全量與增量同步:
假設使用 ShardingSphere 來建立 MySQL Data Sharding 的 Cluster,Resharding 時會用 primary key 分段全量同步,和使用 binlog 增量同步。
資料搬移完後要更新 Sharding Metadata 啟動新 Routing 規則,此時就像部署新的服務一樣,若發現問題要能 Rollback。
但 Rollback 又要把資料搬移回來嗎?
首先 Sharding Metadata 有版本跟狀態,例如 Cluster 剛加入新 DB 時,狀態可是同步中,同步完後更新狀態為啟用,但為了 Rollback 後資料不會出問題,我們可以加一個切換中的過渡狀態。
在該狀態底下,寫入採用 Dual Write,同時寫入舊 DB 跟 新 DB,這樣當新 DB 出問題,Rollback 成舊 DB 時不需要搬資料回來,資料也不會有遺失,而讀取使用 Read Fallback,當新 DB 讀取不到資料時,會往舊 DB 讀取,若 Read Fallback 比例很高,就代表資料搬移到新 DB 出問題,要 Rollback Sharding Metadata。

 iThome鐵人賽
iThome鐵人賽