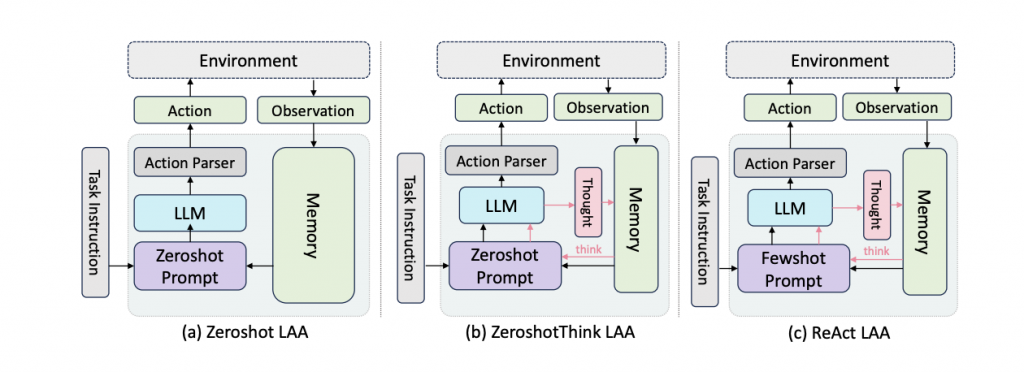
「圖源來自BOLAA: Benchmarking and Orchestrating LLM Autonomous Agents 論文架構圖」
AI Agent,可以看到上圖架構圖是參考由 Liu 等人發表的提出的Agent架構,這張圖說明了一個以大型語言模型為核心的Agent系統架構。整個流程從左到右展開,首先由「任務指令 Task Instruction」啟動,這會是使用者輸入的目標,例如完成一項操作或回答一個問題。接著,任務會被轉換成「規劃提示 Plan Prompt」,引導語言模型產出接下來的行動計畫。
大型語言模型 LLM 是系統的核心推理模組。它接收來自 Plan Prompt 的輸入,並結合「少樣本提示 Fewshot Prompt」與「記憶 Memory」中的過往經驗,來生成一個合理的計畫 Plan。「少樣本提示」提供了相關任務的範例,有助於模型對當前情境進行類比推理,而記憶模組則提供歷次觀察與行動紀錄,提升上下文理解能力。
接著,模型輸出的計畫會進入「行動解析器 Action Parser」,這個模組的功能是把自然語言的行動描述轉換為系統能夠執行的具體操作指令,也就是 Action。
行動會被送出到外部的環境中執行,例如控制畫面、查詢資料,或觸發任務執行。
環境執行完行動後,會回傳一個新的觀察結果 Observation,這些觀察會再被寫入記憶模組,並提供給下一輪提示構建與推理參考,形成一個閉環迴圈。
整體而言,這個架構實現了「感知Observation」、「記憶 Mem」、「規劃 Plan」與「行動 Action」之間的閉環整合,讓代理人能夠在多步任務中進行動態決策,並具備一定程度的上下文感知與任務適應能力。
參考文獻:
https://openreview.net/pdf/415b90cc73d9318ea278aa6c62ac9c6969234999.pdf


 iThome鐵人賽
iThome鐵人賽