在學習 微服務 (Microservices) 時,會遇到非常多的 terms 與 開發套件,而且有些概念很容易混淆。
SOA (Service-Oriented Architecture)
是一個設計哲學,把大系統拆成多個可以互相溝通的小服務,透過共同的protocols(像 SOAP、HTTP)合作,來一起完成一個任務。
就像一座城市裡的建築物,各自有功能,才能讓整個城市運作。
Microservice
像是每棟建築物都有獨立的進出入口,服務小、獨立、通常是 HTTP-based。
Hexagonal Architecture
像是每棟房子內的房間設計允許家具隨時更換,而不影響房子整體結構(保持乾淨邊界)-> it is about the internal。
“An approach to distributed systems that promotes the use of finely grained services that can be changed, deployed, and released independently.” — Sam Newman, Building Microservices
微服務 (Microservice) 是一種處理 分散式架構 (Distributed System) 的方法。將一個大系統(大問題)拆解成小系統(每個小型服務就是一個小問題),這樣每個小服務可以,獨立開發、部署、測試。
每個設計思想都有正反兩面,微服務也帶來挑戰:
微服務 並不總是最好的選擇 (not always good)。在小型專案或團隊人力不足的情況下,microservice 的複雜度可能會比它帶來的好處還多。
接下來我會簡述幾個設計理念
“Changes inside a microservice boundary shouldn’t affect an upstream consumer, enabling independent releasability of functionality.” — Sam Newman, Building Microservices
微服務應該隱藏內部細節 (implementation details),僅提供必要的 API 給外部使用。換句話說,微服務就是一個 Black Box。
每個微服務應該能獨立維護 (self-managed)。
舉例:
在本專案中,Java Spring Boot 是core app,他是一個訊息處理的平台。
Don’t share databases unless you really need to… sharing databases is one of the worst things you can do if you’re trying to achieve independent deployability. — Sam Newman, Building Microservices
微服務架構中的一個重要原則是:盡量不要共享資料庫。
舉例:
這個專案有個資料庫,用來儲存從 API 抓到的新聞 URL。接著,爬蟲服務會根據這些 URL 抓文章。那抓下來的文章該怎麼放?爬蟲要不要直接存取資料庫?
最後我的解法是讓 Java Spring Boot 成為唯一能操作 DB 的入口。爬蟲只專心處理 URL → 文章的抓取,不自己維護 DB。
“Separate core business logic from entry points (customers) and exit points (suppliers, tools).” — Alistair Cockburn
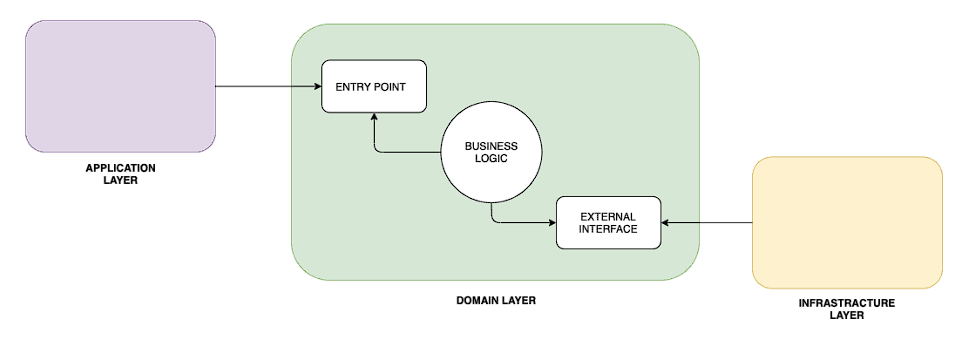
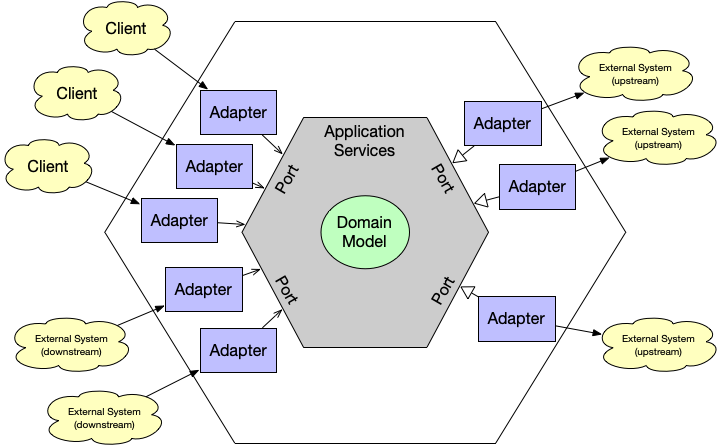
DDD (Domain-Driven Design) 是一種幫助我們將 程式碼圍繞在 Business Logic (domain, core logic) 的設計哲學和方法。
用 DDD + Hexagonal 來定義 Microservice Boundary,使服務達到 Information Hiding。
Hexagonal Ports & Adapters:
AggregateFeedUseCase(外部可以怎麼用這個domain)ContentSourcePort(新聞來源的api client)DDD 設計:
FeedItem、SourceType
AggregateFeedService
Directory Layout :
├─domain
│ ├─model
│ │ FeedItem.java
│ │ SourceType.java
│ ├─ports
│ │ ├─in
│ │ │ AggregateFeedUseCase.java
│ │ ├─out
│ │ │ ContentSourcePort.java
│ ├─service →
│ │ AggregateFeedService.java
model/ 主要放DTOs 物件資料型別來源種類ports/ 定義可以跟新聞整合器互動的「插槽」。
ports/in/ 外部可以叫這個系統做什麼?ports/out/ 這個系統需要新聞來源提供什麼?service/ 核心邏輯,負責實際整合不同來源的新聞。所以這裡就是在用 DDD :整個設計都圍繞著「如何處理商業邏輯」。而這domain是,我提供一個平台,讓使用者可以一問就得到新聞資料。至於實務上「每個新聞 API client的細節」要怎麼實作暫且不重要,就像黑盒子一樣我們會確保使用者可以拿到文章內容就好。(API client 實作細節會留到接下來的文章再介紹。)
Logic Diagram :
[ Application layer ]
↓ calls
[ IN port (use case) ]
└─ AggregateFeedUseCase
↓ implemented by
[ Domain layer ]
└─ AggregateFeedService (domain service)
↓ depends on
[ OUT ports ]
└─ ContentSourcePort
↑ implemented by
news api client service (could be many!!)
FeedItem.java
public record FeedItem(
String id,
SourceType source,
String title,
String url,
String author,
Integer score,
java.time.Instant publishedAt
) {}
SourceType.java
public enum SourceType {
HN, GUARDIAN,
}
AggregateFeedUseCase.java
public interface AggregateFeedUseCase {
// find the top <limitPerSource> number articles
List<FeedItem> topAcrossSources(int limitPerSource);
}
ContentSourcePort.java
public interface ContentSourcePort {
String sourceName();
List<FeedItem> top(int limit);
Optional<FeedItem> byId(String id);
}
AggregateFeedService.java
public class AggregateFeedService implements AggregateFeedUseCase {
private final List<ContentSourcePort> sources;
public AggregateFeedService(List<ContentSourcePort> sources) {
this.sources = sources;
}
@Override
public List<FeedItem> topAcrossSources(int limitPerSource) {
return sources.stream()
.flatMap(s -> s.top(limitPerSource).stream())
.sorted(Comparator.comparing(FeedItem::publishedAt).reversed())
.toList();
}
}

