昨天我們已經學會如何將外部文件載入並進行分割,讓長篇內容被拆解成適合處理的小片段。今天要更進一步,透過 嵌入模型(Embedding Model) 將這些片段轉換成可被搜尋的語意向量,並儲存到 向量資料庫(Vector Store) 中。
這個步驟正是 RAG 的核心環節。唯有將文字轉換成向量並妥善管理,AI 才能依據語意進行檢索,從知識庫中挑選出最相關的內容,進而產生更準確且有依據的回應。
對電腦而言,文字本質上只是字元的排列,並不具備人類的語意理解能力。它不會自然知道「貓」和「狗」之間的關聯,也無法理解牠們同屬於「動物」這個類別。若僅依賴傳統的關鍵字比對,電腦只能找到與查詢字面相同的資料,卻難以辨識語意相近或同義的內容。
這正是 嵌入模型(Embedding Model) 發揮作用的地方。它能將文字轉換成一組高維度的 語意向量(Semantic Vector),並依據語意將它們映射到一個 語意空間(Semantic Space)。在這個空間中:
你可以把這個語意空間想像成一張地圖:
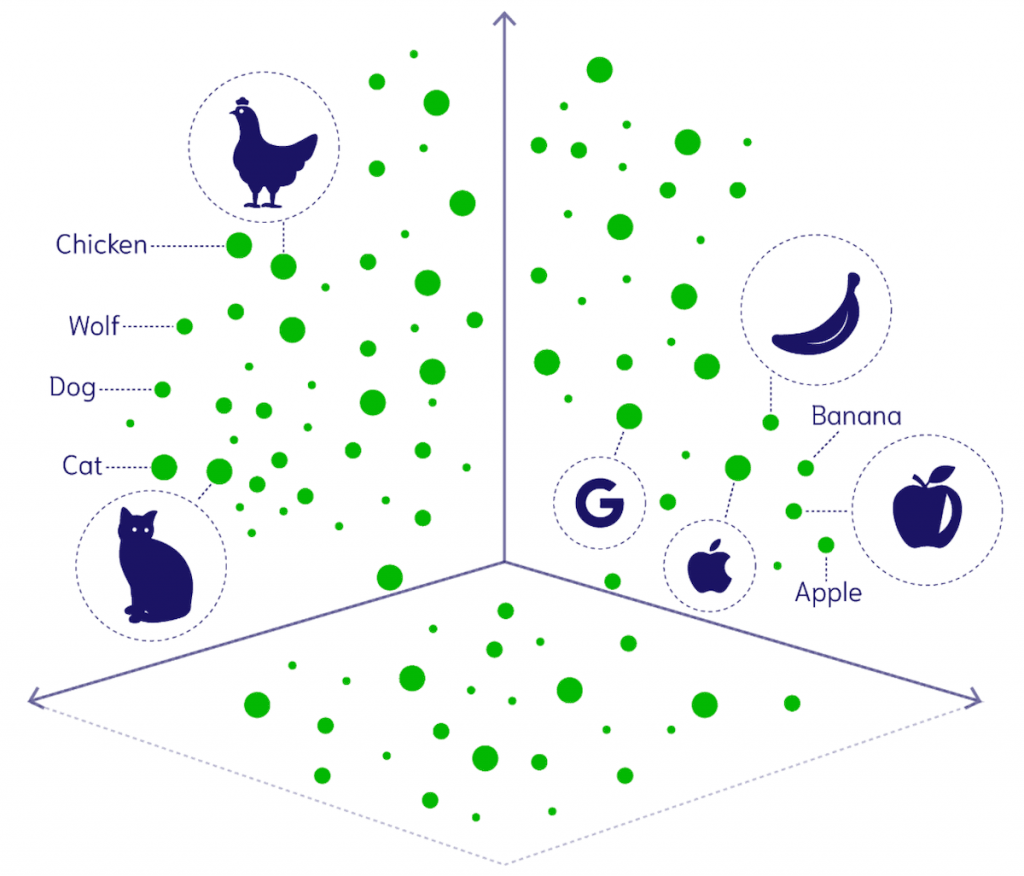
圖片來源:Weaviate
有了這張「語意地圖」,我們就能透過數學公式(例如 餘弦相似度)計算兩段文字之間的語意距離,進而找到與查詢最相關的內容。這也是 RAG 系統能實現語意搜尋的基礎。
嵌入模型可以將文字轉換成能反映語意的高維度向量,而在語意搜尋的流程中,電腦必須同時理解文件內容與使用者查詢的語意,才能比較它們的相似度並找出最相關的結果。這個過程通常分成兩個步驟:
在實作上,LangChain 提供了統一的 API 介面,讓我們可以用相同程式碼呼叫不同供應商的嵌入模型,並且支援兩種常用方法:
embedDocuments:一次將多段文字轉換成向量(適合整批文件處理)。embedQuery:將單一查詢轉換成向量(適合使用者輸入的問題)。以下範例使用 OpenAIEmbeddings,把一組文字段落轉換成向量:
import { OpenAIEmbeddings } from '@langchain/openai';
const embeddingsModel = new OpenAIEmbeddings();
const embeddings = await embeddingsModel.embedDocuments([
'今天的天氣很好,適合去散步。',
'明天天氣預報說會下雨。',
'我最喜歡的運動是打籃球。',
'你週末有什麼計畫嗎?',
'週末我想去爬山。',
]);
console.log(`(${embeddings.length}, ${embeddings[0].length})`);
// (5, 1536) → 5 筆文字,每筆是 1536 維的向量
在這個例子中,我們一次向量化了 5 段文字,embedDocuments 會回傳一個二維陣列,每列代表一段文字的向量表示。
當使用者輸入查詢時,可以使用 embedQuery 將其轉換為向量:
const queryEmbedding = await embeddingsModel.embedQuery(
'明天適合出門嗎?'
);
console.log(queryEmbedding.length);
// 1536 → 單一向量的維度
透過查詢向量與文件向量的比較,我們就能找到語意最接近的內容。
Tip:LangChain 支援多家供應商的嵌入模型(如 OpenAI、Cohere、Hugging Face 等),可依需求在精度、速度與成本之間做取捨。更多資訊可參考 官方文件。
當我們取得 文件向量 與 查詢向量 後,就能透過數學公式比較它們的距離。距離越近代表語意越相似。常見的計算方法包括:
以 餘弦相似度 為例,以下程式碼示範如何手動計算 查詢向量 與 文件向量 之間的相似度:
// 計算餘弦相似度
function cosineSimilarity(vecA: number[], vecB: number[]) {
const dotProduct = vecA.reduce((sum, a, i) => sum + a * vecB[i], 0);
const magnitudeA = Math.sqrt(vecA.reduce((sum, a) => sum + a * a, 0));
const magnitudeB = Math.sqrt(vecB.reduce((sum, b) => sum + b * b, 0));
return dotProduct / (magnitudeA * magnitudeB);
}
// 文件與查詢向量
const queryEmbedding = await embeddingsModel.embedQuery('明天適合出門嗎?');
const similarities = embeddings.map(docVec => cosineSimilarity(queryEmbedding, docVec));
console.log(similarities);
// 範例輸出:
// [
// 0.8130140664761355,
// 0.8287245820206064,
// 0.7561387019565815,
// 0.7893602986409918,
// 0.7753193155216169
// ]
在輸出結果中,數值越高代表文件與查詢的語意越接近。我們就能挑選相似度最高的段落,作為檢索的最佳答案。例如,在這個例子裡,查詢「明天適合出門嗎?」與文件「明天天氣預報說會下雨。」的相似度最高,因此可以推斷它是最相關的回應依據。
需要注意的是,這種「手動計算」的方式僅適用於小規模資料集。在文件數量上萬甚至百萬筆的情境下,效率會急速下降,甚至無法實際應用。因此在真實場景中,我們必須引入 向量資料庫(Vector Store),才能在大規模語料下進行快速且準確的檢索。
前面我們已經學會如何將文件與查詢轉換成向量,並比較它們之間的相似度。當資料規模還小時,我們可以直接在記憶體中進行計算。但隨著文件數量增加到成千上萬、甚至上百萬筆,再加上嵌入模型通常會產生上千維度的向量,這種單純依靠程式運算的方式就會變得非常低效,不僅耗費大量資源,還缺乏持久化保存的能力。
為了應對這些挑戰,我們需要 向量資料庫(Vector Store)。它是一種專門針對高維度向量設計的資料系統,具備以下特點:
與傳統關聯式資料庫不同,向量資料庫不是依靠字面或欄位值的精確比對(如 SQL 查詢),而是透過 語意相似度(向量距離) 來進行搜尋,特別適合處理非結構化資料,例如文字、圖片、音訊等。
| 類型 | 傳統資料庫(RDB) | 向量資料庫 |
|---|---|---|
| 查詢方式 | 精確比對(SQL) | 語意相似度(Cosine 距離) |
| 適用資料類型 | 結構化表格數據 | 非結構化文本、多媒體 |
| 常見工具 | PostgreSQL、MySQL、MSSQL | Chroma、Qdrant、Pinecone 等 |
目前常見的向量資料庫包括 Chroma、Qdrant、Pinecone、Weaviate、Faiss 等。在實務中,向量資料庫的選型需依應用場景決定,例如資料量、查詢效能、相似度演算法支援度、系統整合方式,以及雲端託管或自建需求。不同產品各有優缺點,技術選擇會影響擴展性與維運成本,因此在規劃系統架構時必須一併納入考量。
在 LangChain 中,向量資料庫有一個統一的操作介面,讓開發者能夠方便地切換不同的後端實作,而不需要修改主要的應用邏輯。換句話說,無論你選擇的是哪一種向量資料庫,操作方式基本一致。
常用的核心方法包括:
addDocuments:加入多筆文件到向量資料庫。deleteDocuments / delete:刪除多筆文件。similaritySearch:根據查詢進行相似度搜尋。透過這些方法,我們可以快速完成新增、刪除與查詢的基本操作,並在不同規模與場景下靈活應用。
更多向量資料庫的整合範例與支援列表,可以參考 LangChain 官方文件 。
在 LangChain 中,大多數向量資料庫在初始化時,都需要先指定一個 嵌入模型,用來將文字轉換成向量表示。以下我們以 LangChain 內建的 MemoryVectorStore 搭配 OpenAIEmbeddings 為例為例,示範基本的 API 用法:
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
import { OpenAIEmbeddings } from '@langchain/openai';
// 建立嵌入模型
const embeddings = new OpenAIEmbeddings({
model: 'text-embedding-3-small'
});
// 使用嵌入模型初始化向量資料庫
const vectorStore = new MemoryVectorStore(embeddings);
要將文件加入向量資料庫,可使用 addDocuments 方法。
這個方法接收一個 Document[] 陣列作為輸入,每個 Document 都包含:
pageContent:文件的主要內容。metadata:額外的附加資訊,例如來源、作者或日期。import { Document } from '@langchain/core/documents';
const document1 = new Document({
pageContent: '今天早餐我吃了火腿蛋吐司和一杯熱美式咖啡。',
metadata: { source: 'tweet' },
});
const document2 = new Document({
pageContent: '氣象報告指出,明天台北將有短暫陣雨,最高溫預計 28 度。',
metadata: { source: 'news' },
});
const documents = [document1, document2];
// 將文件加入向量資料庫
await vectorStore.addDocuments(documents);
通常,我們也會替文件指定 ID,方便之後進行更新或刪除:
await vectorStore.addDocuments(documents, { ids: ['doc1', 'doc2'] });
若需要刪除文件,可以使用 deleteDocuments 方法,並傳入要刪除的文件 ID 陣列:
await vectorStore.deleteDocuments(['doc1']);
或是使用 delete 方法,效果相同:
await vectorStore.delete({ ids: ['doc1'] });
當我們傳入查詢文字時,向量資料庫會先將查詢轉換成向量,接著與資料庫中已儲存的文件向量進行比較,最後依照相似度回傳最相關的結果。
常見的相似度度量方式包括餘弦相似度、歐幾里得距離、點積等。大多數向量資料庫在初始化時就能選擇或內建這些演算法,開發者只需透過 LangChain 的 similaritySearch 介面即可使用,不必關心底層實作:
const query = '我的查詢';
const docs = await vectorstore.similaritySearch(query, 2);
上述方法會將查詢文字轉換成嵌入向量,接著搜尋相似文件,並回傳 Document[]。
此外,多數向量資料庫還支援進階搜尋參數,例如:
k:控制回傳的文件數量。filter:根據 Metadata 進行條件篩選。以下範例展示如何搭配 Metadata 過濾,只回傳 source 為 tweet 的文件:
await vectorstore.similaritySearch('LangChain 相關介紹', 2, {
filter: { source: 'tweet' },
});
透過語意搜尋結合 Metadata 過濾,我們不僅能在大型知識庫中找到語意上相關的內容,還能確保結果更符合實際需求,提升檢索的精準度。
今天我們學會了如何透過 嵌入模型(Embedding Model) 與 向量資料庫(Vector Store),把文字轉換成可進行語意檢索的高維向量,並建立可持久化、可查詢的 AI 知識庫:
addDocuments、deleteDocuments、similaritySearch 完成增刪查操作。透過嵌入模型與向量資料庫的結合,RAG 系統得以真正實現語意搜尋,讓 AI 的回應更貼近問題本質,也更有依據。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964



 iThome鐵人賽
iThome鐵人賽